标签:temp vat article single elevation a20 第一部分 配置环境 one
2清水小虾
https://www.zhihu.com/question/280235834/answer/412407487
很巧,我最近也在调研和题主相似的方向,我关注的是物体姿态估计相关的一些网络结构。还在写总结,争取这几天把整理的一些paper和开源code分享出来。
--------------------------------分割线----------------------------------------------------
其实相关的的工作调研已经做了一段时间了,但是由于懒癌,一直没有把文档整理出来。看到题主和我感兴趣的方向基本一致,我把之前的自己的一些心得和大家做个方向,表述不准确的地方还请大家轻拍。也欢迎大家对我的结果进一步补充,交流。
交待一下背景,从事AR视觉算法开发,目前在调研基于手机单目相机DL框架。
---------------------------------分割线----------------------------------------------------
最近尝试编译了两个pose estimation的框架PoseCNN和PoseNet。同时阅读了ICCV 2017 Workshop on Recovering
6D Object Pose的一些文章。
根据demo来看,PoseCNN较为可以满足单目RGB的需求,同时也支持RGBD和Multi VIew,但编译有很多问题没有解决。PoseNet可成功编译,但检测目标为建筑物等大场景(图像占比50%以上),和小物体追踪略有不同。不过PoseNet在Google Scholar上的引用较多,可以跟踪一下相关引用的最新进展。
从ICCV 2017的workshop来看,paper的出点多是基于工业应用,因此输入图像多为RGBD,和基于手机单目的场景不太相同,但他们的数据集生成方式(多是基于CAD synthesis),数据增强的方法,以及误差函数的定义还是有很多借鉴和参考价值。ICCV该workshop的paper较多,我选了其中的三篇。
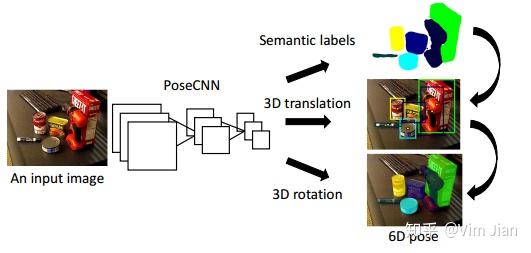
PoseCNN:
https://github.com/yuxng/PoseCNN
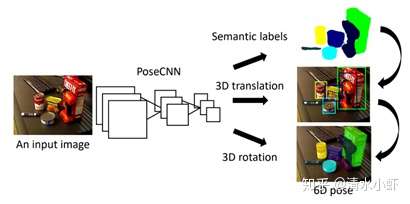
论文思想:
通过三个步骤实现end-end 6dof pose输出,语义分割->translation 估计-> rotation 估计,主要网络结构通过利用VGG16并根据文中定义的loss function来进行训练。
目前源码编译遇到的问题:
该代码对tensorflow 和 cuda等第三方库要求严格,cuda 9.2,tf 1.8/1.2,均不支持,改为cuda9.0和tf1.4后可成功编译相关模块。但代码中有个synthesize (optional)模块由于作者自行定义的几个头文件缺失,无法编译,在之后代码框架中注释调用该模块的所有代码。注释之后可以编译完成整个代码框架,但运行时底层tensorflow出现symbolic link error,Google上说可能是gcc版本问题,更换后动态库中函数缺失问题仍然存在。
总结:
PoseCNN的demo视频和result描述都较为符合单目小物体估计的需求,可以实时估计出6dof pose,同时github作者还在update code。
code的文档描述和实际配置环境差异较大,有些自定义的头文件缺失,使得结果复现难度较大。
PoseNet:
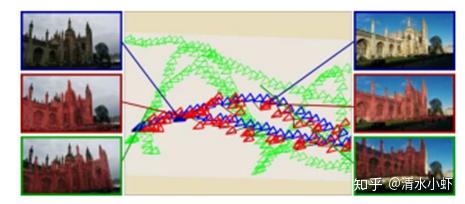
论文思想:
本文的思想和posecnn相反,作者发现分三步训练“less effective”,因此使用overall的方法来训练网络,网络的backbone是googleNet,训练数据标注是通过作者自行定义的SLAM 系统来生成,他们移除一些不用的框架,同时选取最robust的特征来进行估计,可以自动生成大量数据。
源码编译情况:
目前源码已经编译完成,也可以运行测试脚本进行测试。用他们训练集跑了一个测试,完成1万次mini-batch的迭代时间在十分钟以内,平均误差1m,4degree(基于他们的大尺度模型)。编译该源码过程也需要较多3rd party依赖库,安装Nvidia驱动过程中容易破坏系统自身kernel,花费了较长时间才修复成功。
总结:
该框架是目前成功编译运行的第一个框架,对认识基于dl的姿态估计有很大的帮助。没编译经验的同学可以用这个框架先测试一下算法表现。不过也有几个问题,该模型主要用于大场景的估计,对小物体的估计的性能不确定,框架是基于caffe的,目前已经很少有人使用,代码上次更新也是两三年前。Caffe对loss function的自动求导不支持,需要自己定义。现在主流的框架用pytorch和tensorflow的较多。
在Google scholar上查了一下该paper有200+的引用,目前很多新的框架也是部分基于posenet,比如CVPR2018的GeoNet也是利用posenet进行相机姿态估计。可以根据引用posenet的最新paper,来调研一下相关的进展。
《Multi-view 6D Object Pose Estimation and Camera Motion Planning using RGBD Images》

文章解决issue:
object with occlusions and clusters。
核心思想:
基于多个视角的图像创建出点云,然后对点云进行多个cluster的分割(substractive cluster),验证和排除不合理的cluster,合成其它视角的object,基于entropy对Next Best View进行预测。本文的创新点是可以处理多个objects,无监督情况下预测下一帧的cam pos和obj pos。本文基于点云和entropy的方法检测物体和传统基于投影contour的方法不一样,有借鉴的价值,不过缺点是需要depth信息,设备条件不同。
不过该篇论文源代码没有开源,不知道具体实现过程。
本文方法:
1 Hypothesis accumulation and verification combines single-shot based hypotheses estimated from previous views and extract the most likely set of hypotheses.
2. An entropy-based Next-Best-View prediction generates next camera position to capture new data to increase the performance.
3. Camera motion planning plans the trajectory of the camera based on the view entropy and the cost of movement.
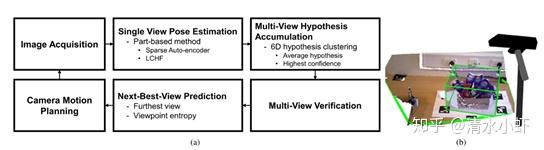
流程:
图像获取 -> 基于Single View Pose Estimation(LCHF and Sparse auto-encoder)-> Point Cloud -> Object hypothesis in world reference coordinate and then clustered -> Representative hypothesis for each cluster by averaging -> verification -> Next-Best-View Prediction(render unseen views and compute view entropy).
《3D Pose Regression using Convolutional Neural Networks Siddharth》
本文提供了一个3D pose estimation的神经网络,作者不关注6 DOF的状态,而是只关注其中决定旋转矩阵R的三个自由度R(az, el, ct),where azimuth az, elevation el, camera-tilt ct。文章作者认为现有的物体检测网络已经很成熟,但是缺少3D姿态的估计,因此提出了一种新的网络解决这一问题。
过去其它论文的工作利用pose classification来进行离散的角度姿态估计,误差函数为Cross-entropy loss,数据增强的使用方法是2D jittering。
本文利用pose regression来进行连续的角度或四元数的姿态估计,误差函数为Geodesic loss,数据增强用的是3D pose jittering。增强的方式为利用homograph对图像进行小角度变换。
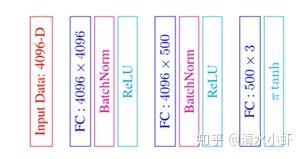
网络结构:
网络结构分为两部份,第一部分为Feature Network based on VGG-M upto FC6,第二部分为Pose Network based on 3 Fully Connected layers with Batch Normalization and ReLU activations.
误差函数:
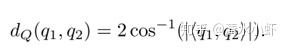
数据来源:
Training set: Imagenet-trainval images.
Validation set: Pascal-train images.
Testing set: Pascal-val images.
《Mutual Hypothesis Verification for 6D Pose Estimation of Natural Objects》
由于自然界物体如蔬果具有高度的形态多样性,同时自然界6D pose的样本匮乏,只能通过小样本或合成的样本进行训练。
一直难以估计pose,本文提出一种基于Mutual Hypothesis Verification的方法来估计6D pose 。 Local descriptor 用来检测 particular local shapes 同时使用 a global estimator来分析global shapes,此方法对物体形变鲁棒。训练集使用CAD模型生成。文中相关工作提到了一些利用CAD模型来训练估计物体pose的工作,缺数据集的同学可以查阅一下,作为参考。
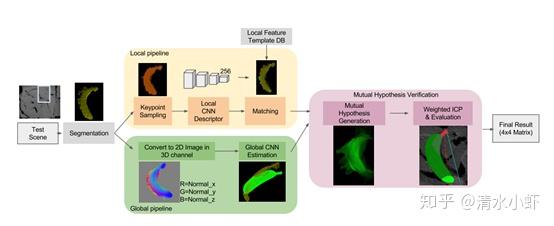
Flowchart:
分为local pipeline和global pipeline两个部分,最后进行mutual hypothesis verification(MHV)。
Local :Input Data(segemented 2.5D point cloud cluster) -> kepoint sampling ->local CNN descriptor -> Matching local feature to template -> MHV
Global: Input Data(segemented 2.5D point cloud cluster) -> Convert to 2D Image in 3D channel -> Global CNN Estimation -> MHV
MHV: Mutual Hypothesis Generation -> Weighted ICP& Evaluation -> Pose by 4 x 4 Matrix
local 网络通过Convolutional Auto-Encoder(CAE)提取到对背景鲁棒的特征描述子,global 网络则直接估计物体的pose,网络通过映射2D图像的法向量到XYZ三个通道作为输入,通过简化的AlexNet,网络输出为姿态的四元数表示,训练数据通过CAD模型生成。
最后通过MHV来对local和global估计出的一系列pose进行验证,然后选出best result。
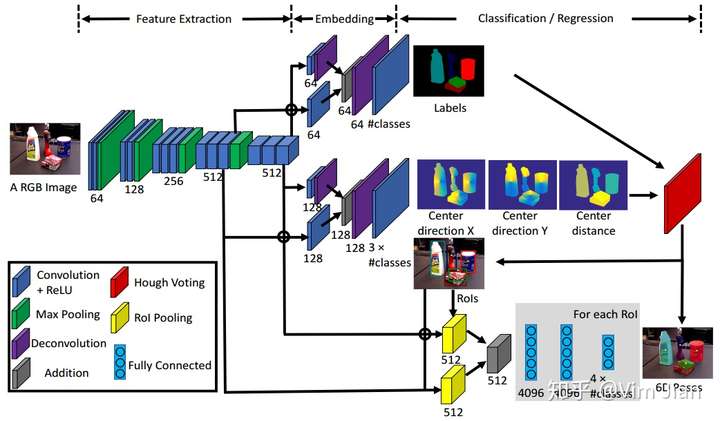
上述是整个网络结构图
对于上述的每个分支,都有一个loss,一共有3个loss。同时,作者为了应对旋转对称物体的姿态迷惑性(即可以用多个四元数来表示一个姿态),作者提出了一个新的loss——ShapeMatch-Loss。
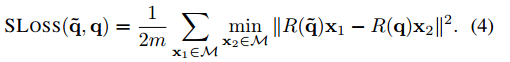
M是代表3d模型空间中的点,R(q?)、R(q)分别代表预测的3d旋转矩阵和真正的3d旋转矩阵。X1表示场景中的点,X2表示模型上离X1最近的点。
作者在OccludedLINEMOD Dataset 和YCB-Video Dataset(作者提出的)进行训练和测试。
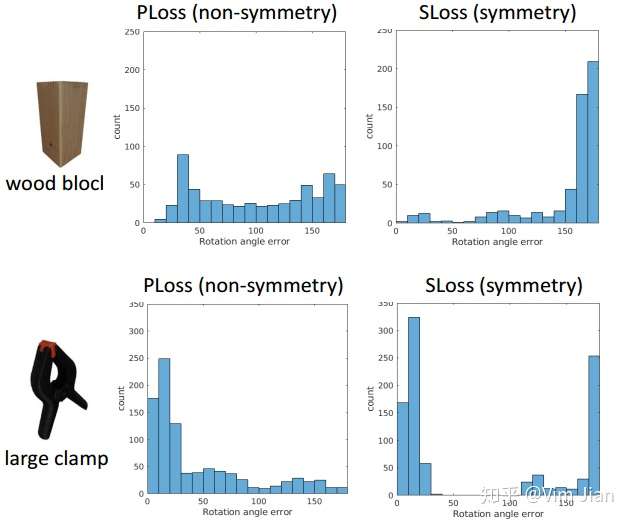
baseline为3D coordinate 。
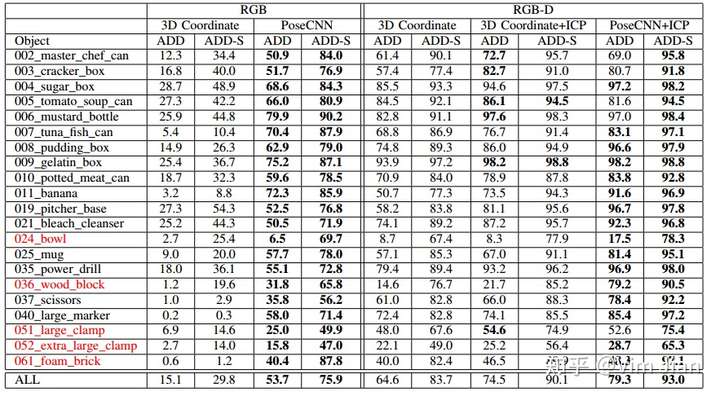
使用RGB作为输入,poseCNN明显性能更高。
使用RGB-D作为输入,使用ICP作为后处理能够明显提升性能。
标签:temp vat article single elevation a20 第一部分 配置环境 one
原文地址:https://www.cnblogs.com/skydaddy/p/11988429.html