标签:class mes png 列表 static apach 逻辑判断 dma cep
MapReduce可以实现一个简单的好友推荐,本文参考了文末博主的思路,个人感觉不错,自己修改部分代码也简单实现了,记录下。
如下数据就是好友关系,同一行的两个人就是好友,需要在这数据里寻找两个人是否是潜在好友,即两人不是直接好友,但是却有共同的好友,需要将这样关系的两个人作为结果推荐出去。
clyang messi
clyang herry
clyang ronald
messi clyang
messi kaka
messi ronald
herry clyang
herry kaka
ronald herry
ronald clyang
ronald messi
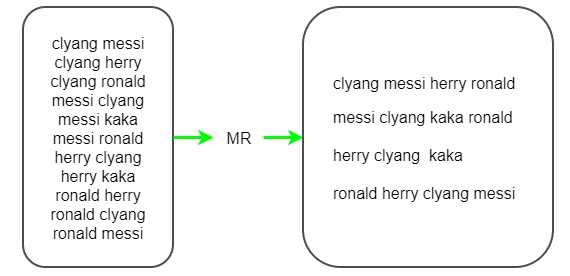
(1)首先按照第一个name来统计他的好友列表,即需要输出成clyang messi herry ronald这样一行行的数据,这样map的输出key就是第一个名字如clyang,value就是好友列表如messi herry ronald,这里使用一个MR来完成中间值的输出。
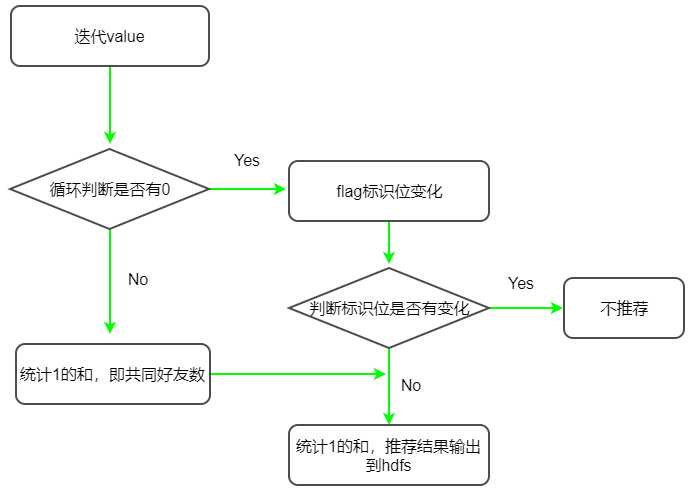
(2)根据上面MR的统计结果,在Map任务中,需将两人的名字和并到一起作为key,如果是直接好友,输出value记录为0,如果不是直接好友,但是有共同的好友,则value记录为1输出给reducer。用数字0和1来区分是否是直接好友,如clyang和messi是直接好友,则输出(clyang:messi, 0),而messi和herry都有共同的好友clyang,因此输出结果为(messi:herry,1)。接下来在Reduer会和并Map的输出结果,将分区结果和并后存入迭代器中,循环迭代器value,如果发现两人关系输出数字为0,则不再推荐,如果没有一个0出现,则推荐出去。
以下为第一轮MR示意图。
Map端代码

package com.boe.friendRecommend; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 先根据第一个name,分组求出它所有的朋友 */ public class FriendMapper extends Mapper<LongWritable,Text,Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拆分每一行 String[] s = value.toString().split(" "); //直接写出到map输出,第一个名字相同,会落在同一分区 context.write(new Text(s[0]),new Text(s[1])); } }
Reduer代码
package com.boe.friendRecommend; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FriendReducer extends Reducer<Text,Text,Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //好友字符串,用空格隔开 String s=""; for (Text text : values) { s+=text.toString()+" "; } //去掉最后一个空格 String friends = s.trim(); //写出 context.write(key,new Text(friends)); } }
main方法
package com.boe.friendRecommend; import com.boe.profitMapReduce.MyPartitioner; import com.boe.profitMapReduce.Profit; import com.boe.profitMapReduce.ProfitMapper; import com.boe.profitMapReduce.ProfitReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * mapreduce,先统计某个人的所有好友 */ public class FriendMain { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //向yarn提交一个job Job job=Job.getInstance(new Configuration()); //设置入口类 job.setJarByClass(FriendMain.class); //设置mapper类和reducer类 job.setMapperClass(FriendMapper.class); job.setReducerClass(FriendReducer.class); //设置map输出格式 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //设置reduce输出格式 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //如果map输出格式和reduce输出格式一样,就只需要设置reduce就行 //设置读取的文件 Path("hdfs://192.168.200.100:9000/txt/friend.txt")); //设置输出路径 //输出路径必须不存在 FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.200.100:9000/friendout")); //提交 job.waitForCompletion(true); } }
执行后结果

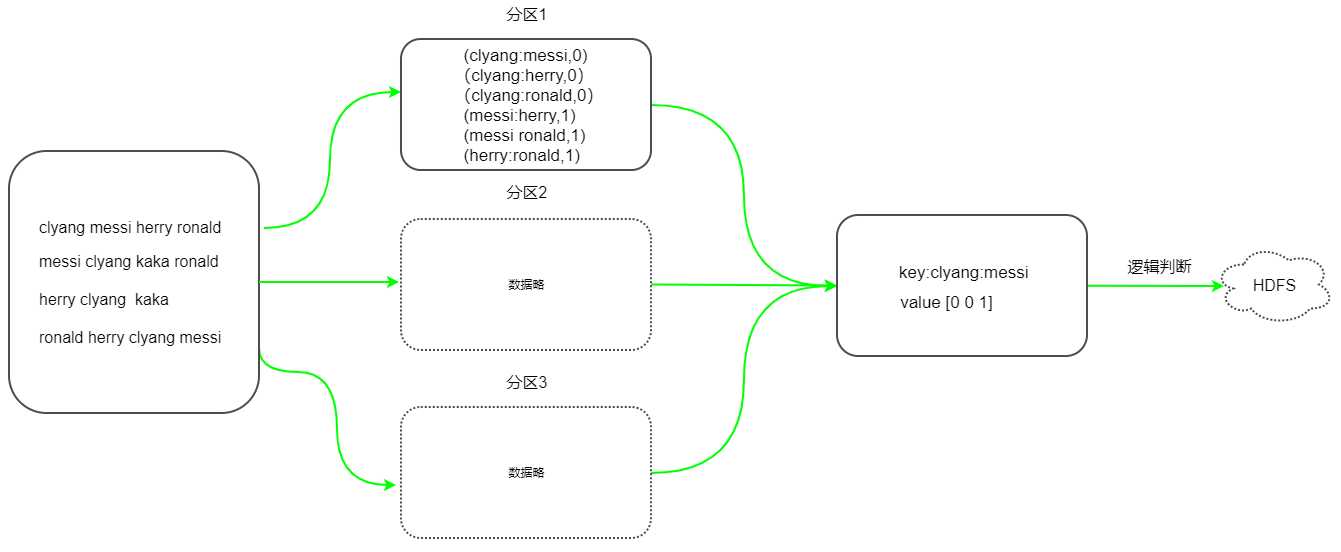
以下为第二轮MR的示意图,假设有map端结果有3个分区,reducer端直接以分区merge后的结果进行计算来简单示意,其中reduce端的逻辑判断大概就是上面的判断示意图。
Map端代码
package com.boe.friendRecommend; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 第二层map,统计第一次mapreduce计算后的结果 */ public class FriendMapper2 extends Mapper<LongWritable, Text,Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //value 形如tom+制表符+lucy smith jim rose的结果 String[] strings = value.toString().split("\t"); String name=strings[0];//tom String friends=strings[1];//lucy smith jim rose //拆分得到好友列表 String[] s = friends.split(" "); //name和所有好友列表都是好友,输出拼接后好友为key,0为value,0代表不推荐,本身就是好友 for (String friend : s) { String fkey = getKey(name, friend); context.write(new Text(fkey),new IntWritable(0)); } //其他好友列表之间,因为有共同好友,value为1 for(int i=0;i<s.length;i++){ for(int j=i+1;j<s.length;j++){ String fkey=getKey(s[i],s[j]); context.write(new Text(fkey),new IntWritable(1)); } } } //写一个方法,拼接好友 public static String getKey(String name1,String name2){ if(name1.compareTo(name2)>0){ return name1+":"+name2; }else{ return name2+":"+name1; } } }
Reduer代码
package com.boe.friendRecommend; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 第二层Reduce */ public class FriendReducer2 extends Reducer<Text, IntWritable,Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //key就是心如clyang:messi这样的字符串 //values就是[0 1 0 1 0]这样的结果,只要有0,就不写出,不推荐 boolean flag=true; //共同好友个数 int num=0; for (IntWritable value : values) { if(value.get()==0){ flag=false; } num++; } //如果flag为false,不推荐,否则输出,value为共同好友数 if(flag){ context.write(key,new IntWritable(num)); } } }
main方法
package com.boe.friendRecommend; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 第二次mapreduce的main的方法 */ public class FriendMain2 { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //向yarn提交一个job Job job=Job.getInstance(new Configuration()); //设置入口类 job.setJarByClass(FriendMain2.class); //设置mapper类和reducer类 job.setMapperClass(FriendMapper2.class); job.setReducerClass(FriendReducer2.class); //设置map输出格式 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置reduce输出格式 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //如果map输出格式和reduce输出格式一样,就只需要设置reduce就行 //设置读取的文件,为上次输出的路径 FileInputFormat.addInputPath(job,new Path("hdfs://192.168.200.100:9000/friendout/")); //设置输出路径 //输出路径必须不存在 FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.200.100:9000/friendrecommend")); //提交 job.waitForCompletion(true); } }
执行后结果如下。
(1)kaka和clyang是潜在好友,并且有2个共同好友。
(2)messi和herry是潜在好友,并且有2个共同好友。
(3)ronald和kaka是潜在好友,并且有1个共同好友。
对比源数据,发现计算结果正确,推荐结束。

以上就是使用MapReduce实现的简单版好友推荐,记录一下。
参考博文:
(1)https://www.cnblogs.com/benjamin77/p/10203645.html
标签:class mes png 列表 static apach 逻辑判断 dma cep
原文地址:https://www.cnblogs.com/youngchaolin/p/11999872.html
