标签:using 分解 lin proc net 更新 其他 for -o
***CA-RNN: Using Context-Aligned Recurrent Neural Networks for Modeling Sentence Similarity(CA-RNN:使用上下文对齐的递归神经网络建模句子相似度)***
**论文通读:**
## 1. 概要:
大多数RNN专注于基于当前句子对隐藏状态进行建模,而在隐藏状态生成过程中,其他句子的上下文信息却没有得到很好的研究。在本文中,我们提出了**一种上下文对齐的RNN(CA-RNN)模型**,该模型在句子对中**合并了对齐单词的上下文信息**,以生成内部隐藏状态。具体来说,我们首先执行单词对齐检测,以识别两个句子中对齐的单词。然后,我们提出一种**上下文对齐门控机制**,并将其嵌入到我们的模型中,以自动吸收对齐单词的上下文以进行隐藏状态更新
## 2. 具体工作:
1. 提出了一个新的上下文对齐RNN模型,其中两个句子中对齐单词的上下文被很好地利用以更好地产生隐藏状态;
2. 提出了一种上下文对齐选通机制,并将其很好地嵌入到我们的模型中,该机制可以自动吸收相关上下文并减少生成特定隐藏状态的噪声;
3. 我们对两个句子相似性任务进行了实验结果的详尽分析,从而更好地理解了模型的有效性相关工作
## 3. 模型分解:
- 神经网络:
其模型如下:
)
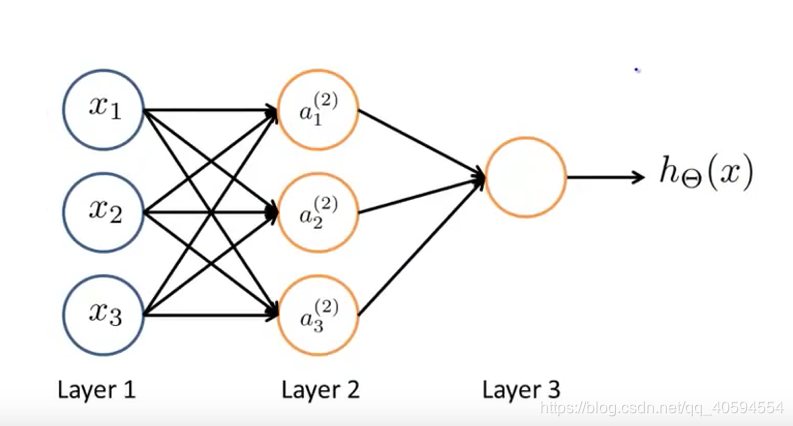
输入特征项:x1,x2,x3,最后h(x)为输出。
layer2为隐藏层,这里面的值我们不知道。所有输出层和输入层都是隐藏层。
上述的神经元,计算过程如下:

每个输入值,在一个节点中,有不同的权值,根据不同的权值来计算输出。
其中为矩阵相乘的相关知识,g为sigmode函数:
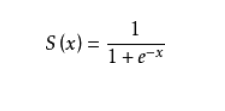
- 损失函数,反向传播
损失函数:
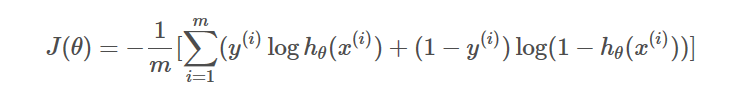
反向传播:(具体算式略):即采用正向传播得出的结果与真实值进行比较,得出误差,然后通过代价函数和误差推导输出前一层的神经网络的误差,然后通过得出的误差一直向前推导,直到输入层的下一层,然后再通过调整权值,调整误差,尽量使得误差较小。
- RNN:递归神经网络,其模型如下:
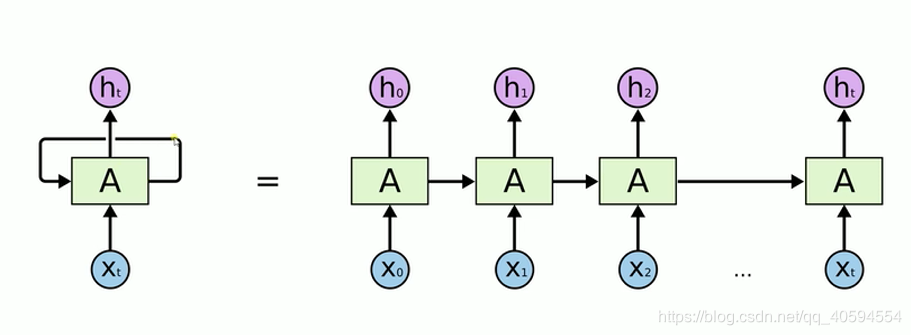
我们在处理文字等问题的时候,我们的输入会把上一个时间输出的数据作为下一个时间的输入数据进行处理。
例如:我们有一段话,我们将其分词,得到t个数据,我们分别将每一个词传入到x0,x1…xt里面,当x0传入后,会得到一个结果h0,同时我们会将处理后的数据传入到下个时间,到下个时间的时候,我们会再传入一个数据x1,同时还有上一个时间处理后的数据,将这两个数据进行整合计算,然后再向下传输,一直到结束。
rnn本质来说还是一个bp回路,不过他只是比bp网络多一个环节,即它可以反馈上一时间点处理后的数据。
- LSTM(长短期记忆网络)
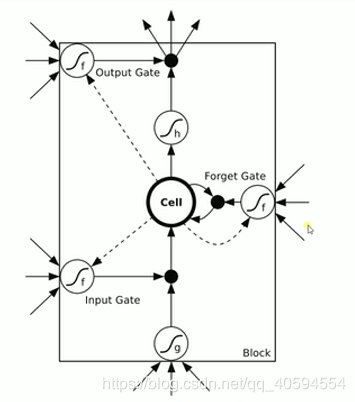
上图有三个门:输入门 忘记门 输出门
1.输入门:通过input * g 来判断是否输入,如果不输入就为0,输入就是0,以此判断信号是否输入
2.忘记门:这个信号是否需要衰减多少,可能为50%,衰减是根据信号来判断。
3.输入门:通过判断是否输出,或者输出多少,例如输出50%。
所以通过上述神经网络和RNN模型以及LSTM我们可以通读此论文。
按照上述要求:
**上下文对齐选通机制:**
- 1.基于单词重叠
单词重叠即相同单词,获取相同单词的上下文信息即可。
- 2.基于语义相似度
基于语义,即为相似词,例如:爸爸也叫老爸,通过词或字的相似性来进行选择上下文。(基于Stanford Core NLP工具2的单语单词aligner1算法(语义算法))
**上下文对齐门控机制**
- 1.相关性度量
- 2.上下文吸收
1.测量对齐的单词所在的句子(HX)的表示与当前单词对应的隐藏状态(hy j)之间的相关性,这是确定多少上下文信息的良好标准另一个句子中对齐的单词中要吸收的部分。(即为激励函数求概率)
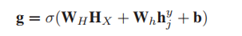
2.由RNN获得的原始隐藏状态(hy j)将根据所测量的相关性直接吸收其他句子中对齐单词的上下文信息(hx i)。结果,将生成新的隐藏状态,其公式为:hyj = g hx i +(1- g)hy j(3)其中,g是通过公式(2)获得的内插相关参数,表示逐元素相乘,并且hyj是新生成的隐藏状态
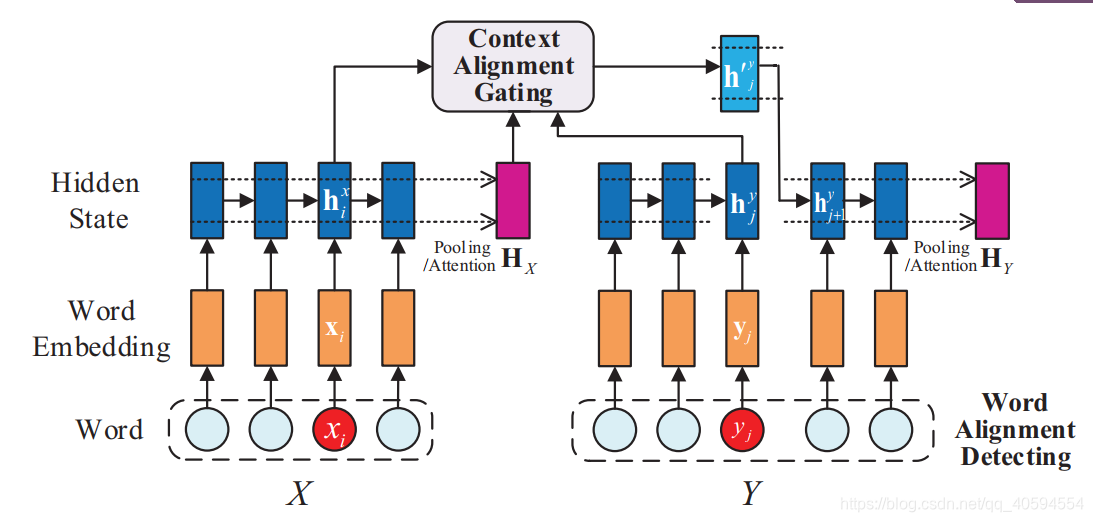
综上,ca-rnn即为其流程
CA-RNN论文读取
标签:using 分解 lin proc net 更新 其他 for -o
原文地址:https://www.cnblogs.com/lh9527/p/9527-12.html