标签:优势 角度 加速器 模拟 one 需要 描述 这一 转化
这里打算简单记录一下深度学习加速器相关的软件栈。
先上一张堆栈图, 图中没有包含runtime的东西。
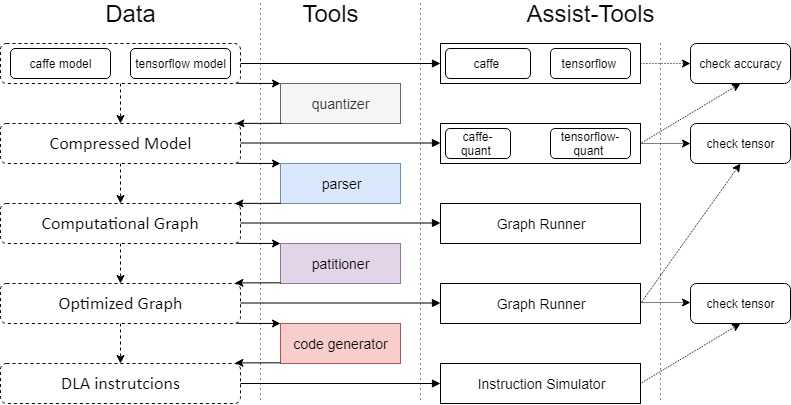
dlaflow要做的事情就是把常见的深度学习框架所描述的网络模型转化成DLA(Deep Learning Acceraor) 能读入执行的指令流。
如上图所示,从data flow的角度:
第一步,压缩, 压缩可以用减枝(减少计算节点)和量化(int32->int8)来实现。每家的深度学习框架都有自己的模型存储标准和格式,所以压缩只需要在对应框架中实现减枝和量化的OP。
第二步,解析,这里需要将各家的模型文件解析成统一的计算图格式。后续步骤只用看到这一级的graph。
第三步,优化,解析出的计算图还是比较原始的算子连接,为了匹配DLA的计算优势,这里需要对计算图进行优化,比如重排和拆分子图(OP Fusion)。
第四步,生成指令,根据优化后计算图和硬件限制生成出DLA可执行的指令流。
那么, 从工具链的角度至少需要4个工具,压缩量化工具(quantizer), 模型解析工具(parser),模型优化工具(partitioner),指令生成工具(code generator)。也可以将优化工具和指令生成工具合并成类似编译器的工具。
有了工具,还得验证,这里就还需要增加辅助工具。虽然各家的学习框架是已经有的, 为了支持压缩,还得增加相应压缩技术的OP。
验证parser正确性, 就需要执行计算图的graph runner。
验证code generator的正确性,需要一个指令模拟器。
标签:优势 角度 加速器 模拟 one 需要 描述 这一 转化
原文地址:https://www.cnblogs.com/chaobing/p/12005590.html