标签:idt 一点 为什么 one 信号 softmax 学习 包含 等于
其实logistic函数也就是经常说的sigmoid函数,它的几何形状也就是一条sigmoid曲线(S型曲线)。
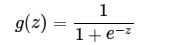
其中z是一个线性组合,比如z可以等于:b + w1*x1 + w2*x2。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1
A logistic function or logistic curve is a common “S” shape (sigmoid curve).
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0
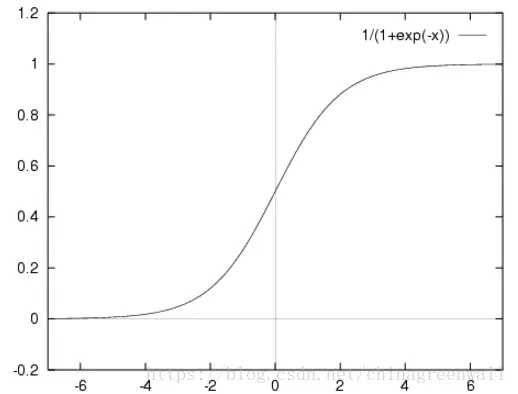
压缩至0到1有何用处呢?用处是这样便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
优点:
1、Sigmoid函数的输出在(0,1)之间,输出范围有限,优化稳定,可以用作输出层。
2、连续函数,便于求导。
第二点,激活函数的偏移现象。sigmoid函数的输出值均大于0,使得输出不是0的均值,这会导致后一层的神经元将得到上一层非0均值的信号作为输入,这会对梯度产生影响。。
第三点,计算复杂度高,因为sigmoid函数是指数形式。 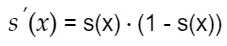
sigmod 求导过程很简单,可以手动推导。
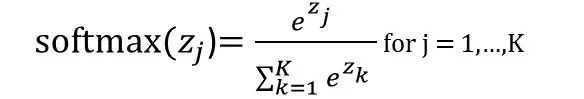
下面这张图便于理解:
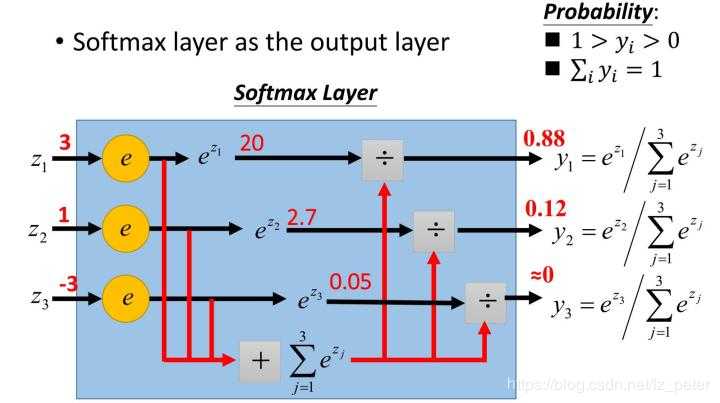
由于Softmax函数先拉大了输入向量元素之间的差异(通过指数函数),然后才归一化为一个概率分布,在应用到分类问题时,它使得各个类别的概率差异比较显著,最大值产生的概率更接近1,这样输出分布的形式更接近真实分布。
Softmax可以由三个不同的角度来解释。从不同角度来看softmax函数,可以对其应用场景有更深刻的理解。
Softmax函数的输出符合指数分布族的基本形式
其中 。
不难理解,softmax将输入向量归一化映射到一个类别概率分布,即 个类别上的概率分布(前文也有提到)。这也是为什么在深度学习中常常将softmax作为MLP的最后一层,并配合以交叉熵损失函数(对分布间差异的一种度量)。
• 如果模型输出为非互斥类别,且可以同时选择多个类别,则采用Sigmoid函数计算该网络的原始输出值。
• 如果模型输出为互斥类别,且只能选择一个类别,则采用Softmax函数计算该网络的原始输出值。
标签:idt 一点 为什么 one 信号 softmax 学习 包含 等于
原文地址:https://www.cnblogs.com/jiashun/p/doubles.html