标签:ted ocs imu 服务 数据 逻辑 author cat 输入密码
版本采用的是neo4j-enterprise-3.5.3-unix.tar.gz
192.168.56.10 neo4j-node1
192.168.56.11 neo4j-node2
192.168.56.12 neo4j-node3
192.168.56.13 neo4j-node4
192.168.56.14 neo4j-node5$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #生成秘钥
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #cp公钥到验证文件中
$ chmod 0600 ~/.ssh/authorized_keys如上做免密登录,这里只做了neo4j-node1 免密登录其他节点
这里做不做免密,都可以,我做免密主要是为了方便,不需要一直输入密码,在正式环境中还是不用免密的好
/etc/hosts配置
192.168.56.10 neo4j-node1
192.168.56.11 neo4j-node2
192.168.56.12 neo4j-node3
192.168.56.13 neo4j-node4/etc/sysconfig/network配置
hostname neo4j-node1重启网卡
$ systemctl restart network如上内容完成之后退出重新登录,修改主机名的设置就能生效
官方配置参数详细列表
https://neo4j.com/docs/operations-manual/current/ha-cluster/tutorial/setup-cluster/
官方HA配置模式
https://neo4j.com/docs/operations-manual/current/ha-cluster/tutorial/setup-cluster/
分别在三台不同机器上进行修改配置文件,conf/neo4j.conf
neo4j-node1
# Unique server id for this Neo4j instance
# can not be negative id and must be unique
ha.server_id=1
# List of other known instances in this cluster
ha.initial_hosts=neo4j-node1:5001,neo4j-node2:5001,neo4j-node3:5001
# Alternatively, use IP addresses:
#ha.initial_hosts=192.168.0.20:5001,192.168.0.21:5001,192.168.0.22:5001
# HA - High Availability
# SINGLE - Single mode, default.
dbms.mode=HA
# HTTP Connector
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=:7474
neo4j-node2
# Unique server id for this Neo4j instance
# can not be negative id and must be unique
ha.server_id=2
# List of other known instances in this cluster
ha.initial_hosts=neo4j-node1:5001,neo4j-node2:5001,neo4j-node3:5001
# Alternatively, use IP addresses:
#ha.initial_hosts=192.168.0.20:5001,192.168.0.21:5001,192.168.0.22:5001
# HA - High Availability
# SINGLE - Single mode, default.
dbms.mode=HA
# HTTP Connector
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=:7474neo4j-node3
# Unique server id for this Neo4j instance
# can not be negative id and must be unique
ha.server_id=3
# List of other known instances in this cluster
ha.initial_hosts=neo4j-node1:5001,neo4j-node2:5001,neo4j-node3:5001
# Alternatively, use IP addresses:
#ha.initial_hosts=192.168.0.20:5001,192.168.0.21:5001,192.168.0.22:5001
# HA - High Availability
# SINGLE - Single mode, default.
dbms.mode=HA
# HTTP Connector
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=:7474根据上面官方给出的配置,启动的时候会报错的,报错信息如下:
logs/neo4j.log
2019-03-07 03:43:22.176+0000 INFO ======== Neo4j 3.5.3 ========
2019-03-07 03:43:22.194+0000 INFO Starting...
2019-03-07 03:43:24.254+0000 INFO Write transactions to database disabled
2019-03-07 03:43:24.662+0000 INFO Initiating metrics...
2019-03-07 03:43:26.000+0000 INFO Attempting to join cluster of [neo4j-node1:5001, neo4j-node2:5001, neo4j-node3:5001]
2019-03-07 03:44:56.174+0000 ERROR Failed to start Neo4j: Starting Neo4j failed: Component 'org.neo4j.server.database.LifecycleManagingDatabase@1e141e42' was successfully initialized, but failed to start. Please see the attached cause exception "Conversation-response mapping:
{1/13#=ResponseFuture{conversationId='1/13#', initiatedByMessageType=join, response=null}}". Starting Neo4j failed: Component 'org.neo4j.server.database.LifecycleManagingDatabase@1e141e42' was successfully initialized, but failed to start. Please see the attached cause exception "Conversation-response mapping:
{1/13#=ResponseFuture{conversationId='1/13#', initiatedByMessageType=join, response=null}}".
org.neo4j.server.ServerStartupException: Starting Neo4j failed: Component 'org.neo4j.server.database.LifecycleManagingDatabase@1e141e42' was successfully initialized, but failed to start. Please see the attached cause exception "Conversation-response mapping:
{1/13#=ResponseFuture{conversationId='1/13#', initiatedByMessageType=join, response=null}}".
at org.neo4j.server.exception.ServerStartupErrors.translateToServerStartupError(ServerStartupErrors.java:45)
at org.neo4j.server.AbstractNeoServer.start(AbstractNeoServer.java:184)
at org.neo4j.server.ServerBootstrapper.start(ServerBootstrapper.java:123)
at org.neo4j.server.ServerBootstrapper.start(ServerBootstrapper.java:90)
at com.neo4j.server.enterprise.CommercialEntryPoint.main(CommercialEntryPoint.java:22)
Caused by: org.neo4j.kernel.lifecycle.LifecycleException: Component 'org.neo4j.server.database.LifecycleManagingDatabase@1e141e42' was successfully initialized, but failed to start. Please see the attached cause exception "Conversation-response mapping:
{1/13#=ResponseFuture{conversationId='1/13#', initiatedByMessageType=join, response=null}}".
at org.neo4j.kernel.lifecycle.LifeSupport$LifecycleInstance.start(LifeSupport.java:473)
at org.neo4j.kernel.lifecycle.LifeSupport.start(LifeSupport.java:111)
at org.neo4j.server.AbstractNeoServer.start(AbstractNeoServer.java:177)
... 3 more如上错误说明三台机器之间访问出现了问题,不能相互感知,不能加入集群,还需要增加下面配置
#在neo4j-node1 neo4j.conf中添加
dbms.connectors.default_listen_address=192.168.56.10
dbms.connector.bolt.enabled=true
dbms.connector.bolt.listen_address=:7687
#在neo4j-node2 neo4j.conf中添加
dbms.connectors.default_listen_address=192.168.56.11
dbms.connector.bolt.enabled=true
dbms.connector.bolt.listen_address=:7687
#在neo4j-node3 neo4j.conf中添加
dbms.connectors.default_listen_address=192.168.56.12
dbms.connector.bolt.enabled=true
dbms.connector.bolt.listen_address=:7687如上配置完成之后启动相关机器,启动没有顺序区别,依次进行启动
$ neo4j-node1$ ./bin/neo4j start
$ neo4j-node2$ ./bin/neo4j start
$ neo4j-node3$ ./bin/neo4j start2019-03-07 06:01:26.887+0000 INFO ======== Neo4j 3.5.3 ========
2019-03-07 06:01:26.892+0000 INFO Starting...
2019-03-07 06:01:28.897+0000 INFO Write transactions to database disabled
2019-03-07 06:01:29.255+0000 INFO Initiating metrics...
2019-03-07 06:01:30.911+0000 INFO Attempting to join cluster of [neo4j-node1:5001, neo4j-node2:5001, neo4j-node3:5001]
2019-03-07 06:01:42.993+0000 INFO Could not join cluster of [neo4j-node1:5001, neo4j-node2:5001, neo4j-node3:5001]
2019-03-07 06:01:42.993+0000 INFO Creating new cluster with name [neo4j.ha]...
2019-03-07 06:01:42.998+0000 INFO Instance 1 (this server) entered the cluster
2019-03-07 06:01:43.012+0000 INFO Instance 1 (this server) was elected as coordinator
2019-03-07 06:01:43.094+0000 INFO I am 1, moving to master
2019-03-07 06:01:43.170+0000 INFO Instance 1 (this server) was elected as coordinator
2019-03-07 06:01:43.256+0000 INFO I am 1, successfully moved to master
2019-03-07 06:01:43.264+0000 INFO Instance 1 (this server) is available as master at ha://192.168.56.10:6001?serverId=1 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:43.288+0000 INFO Sending metrics to CSV file at /root/neo4j-e-3.5.3/metrics
2019-03-07 06:01:43.300+0000 INFO Database available for write transactions
2019-03-07 06:01:43.357+0000 INFO Instance 1 (this server) is available as backup at backup://127.0.0.1:6362 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:43.787+0000 INFO Instance 2 joined the cluster
2019-03-07 06:01:43.893+0000 INFO Instance 3 joined the cluster
2019-03-07 06:01:43.905+0000 INFO Instance 1 (this server) was elected as coordinator
2019-03-07 06:01:43.955+0000 INFO Instance 1 (this server) is available as master at ha://192.168.56.10:6001?serverId=1 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:43.973+0000 INFO Instance 1 (this server) is available as backup at backup://127.0.0.1:6362 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:44.082+0000 INFO Bolt enabled on 192.168.56.10:7687.
2019-03-07 06:01:44.703+0000 INFO Instance 2 is available as slave at ha://192.168.56.11:6001?serverId=2 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:46.444+0000 WARN Server thread metrics not available (missing neo4j.server.threads.jetty.all)
2019-03-07 06:01:46.455+0000 WARN Server thread metrics not available (missing neo4j.server.threads.jetty.idle)
2019-03-07 06:01:46.979+0000 INFO Started.
2019-03-07 06:01:47.403+0000 INFO Mounted REST API at: /db/manage
2019-03-07 06:01:47.514+0000 INFO Server thread metrics have been registered successfully
2019-03-07 06:01:49.508+0000 INFO Remote interface available at http://localhost:7474/
2019-03-07 06:01:49.895+0000 INFO Instance 1 (this server) was elected as coordinator
2019-03-07 06:01:49.923+0000 INFO Instance 1 (this server) is available as master at ha://192.168.56.10:6001?serverId=1 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:49.971+0000 INFO Instance 1 (this server) is available as backup at backup://127.0.0.1:6362 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:49.992+0000 INFO Instance 2 is available as slave at ha://192.168.56.11:6001?serverId=2 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:50.222+0000 INFO Instance 3 is available as slave at ha://192.168.56.12:6001?serverId=3 with StoreId{creationTime=1551928418454, randomId=5747408418777003467, storeVersion=16094931155187206, upgradeTime=1551928418454, upgradeId=1}
2019-03-07 06:01:50.872+0000 WARN The client is unauthorized due to authentication failure.如上日志中可以看出来,机器分别都已经加入到集群中,访问集群
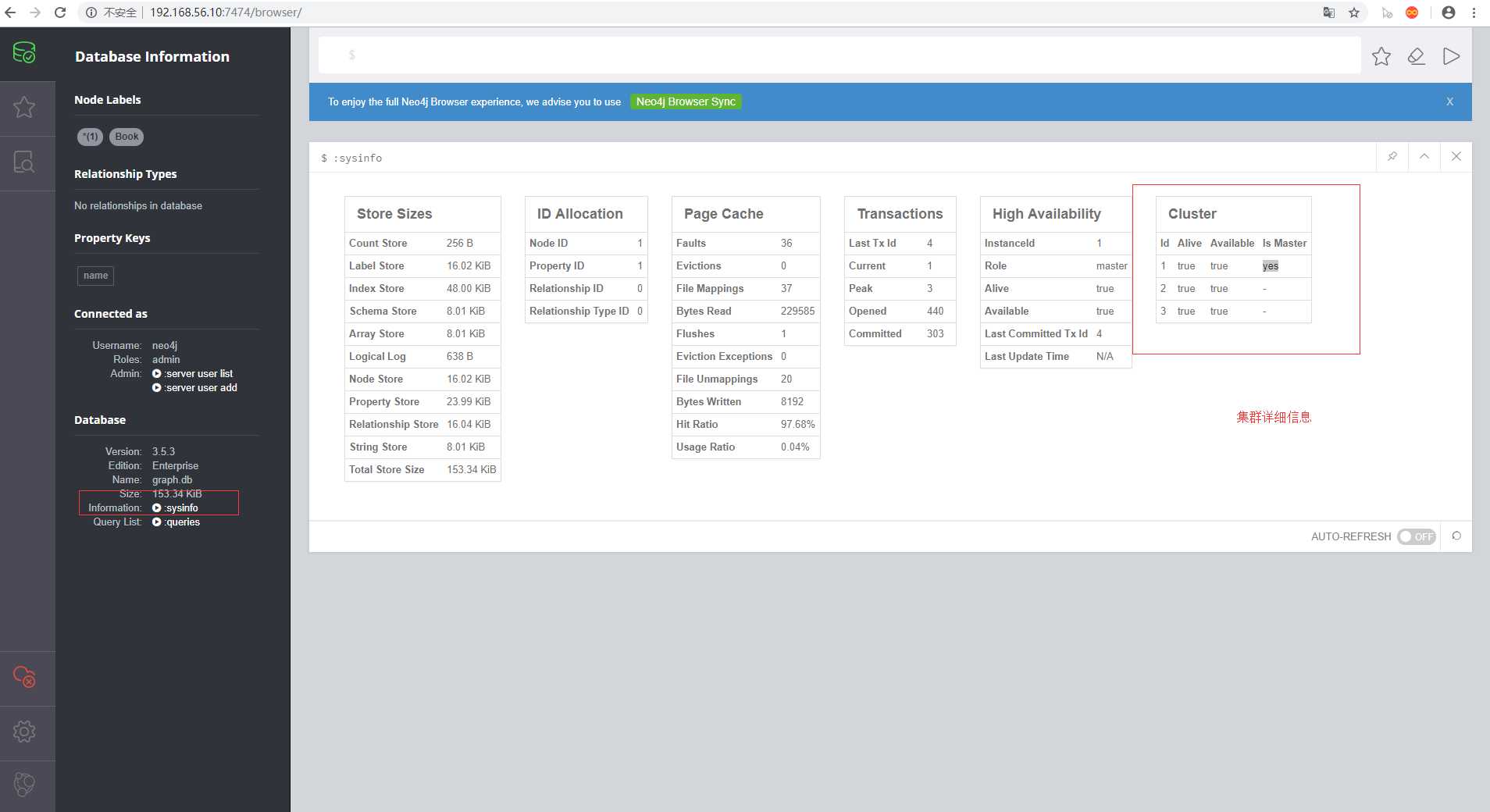
如上图,点击之后查询出集群的详细信息,可以看到配置的ha.server_id机器分别都加入集群中,并且可以看出那台机器为master节点
说明配置成功,随便访问任何一台机器都能够提供服务,可以自己新建一个node或者relation分别在不同的机器提供的访问接口查看是否创建成功,数据是否同步成功
官方文档:https://neo4j.com/docs/operations-manual/current/
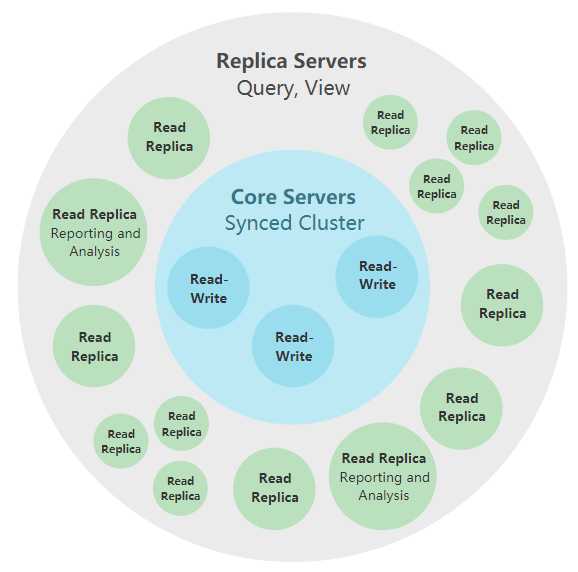
如上图所示就是因果集群的架构图,架构中主要分为两种角色类型,一种是Replica Servers和Core Servers两种角色,下面对两种角色进行介绍:
Core Servers:此角色是逻辑划分,在该系统角色中由多台物理实体机组成,主要提供数据的存储和数据一致性,事务处理等功能,同时在Core集群中是支持HA的,所以有Leader和Follower两中角色,这两种角色能够互相进行切换,Leader角色主要提供管理集群的作用,存储元数据信息和处理集群心跳、数据分发等工作,Core节点是能够进行writer and read,Core集群中是能够进行集群拓扑的
Replica Servers:该角色系统中的节点主要提供的是对数据的查询,他能提供查询任意在Core集群中的图数据,这里的数据是由Core集群发送给Replica集群的副本,所以在Replica中,数据丢失不会影响到整个集群的使用,他主要的作用就是扩展集群的工作负载例如查询等
因果一致性:neo4j采用的是因果一致性来保证数据的一致性,使用到的协议是Raft协议来复制所有事务来实现数据的安全和数据一致性;这和其他的分布式系统中采用的Paxos协议不同
Raft协议原理解释https://www.jianshu.com/p/8e4bbe7e276c
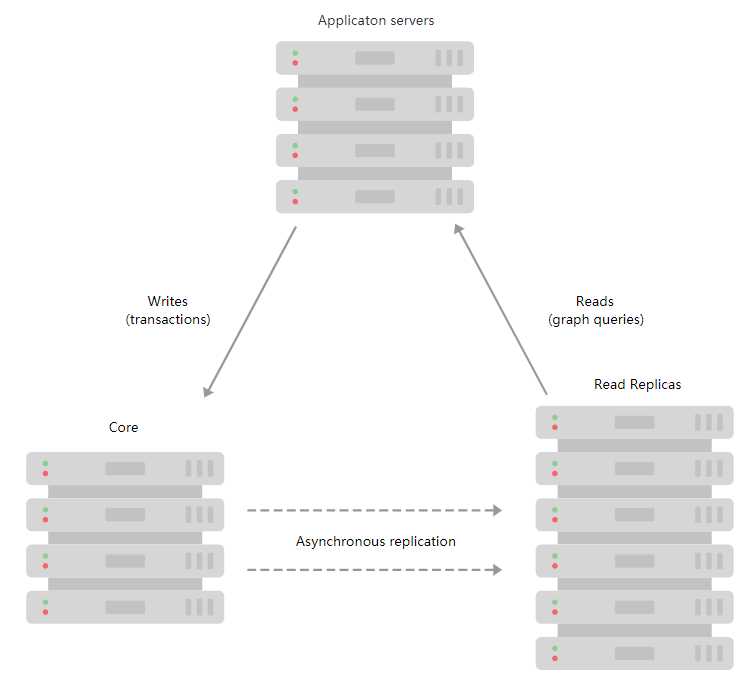
官方提供的一个应用程序对图进行读写操作的一个流程图,这里Core和Read Replicas都是集群的方式进行展示
在上面的图中能够看出数据是怎么流动的,Core是能够写和读,reads是只能被读的,但是Core只能是Leader提供写操作,否则报错如下:
Neo.ClientError.Cluster.NotALeader: No write operations are allowed directly on this database. Writes must pass through the leader. The role of this server is: FOLLOWER本次的搭建中的节点规划是:
neo4j-node2 core
neo4j-node3 core
neo4j-node4 core
neo4j-node5 add core OR add Read因果集群的Core集群配置
neo4j-node2
dbms.connectors.default_listen_address=192.168.56.11
dbms.connectors.default_advertised_address=192.168.56.11
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.discovery_members=192.168.56.11:5000,192.168.56.12:5000,192.168.56.13:5000neo4j-node3
dbms.connectors.default_listen_address=192.168.56.12
dbms.connectors.default_advertised_address=192.168.56.12
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.discovery_members=192.168.56.11:5000,192.168.56.13:5000,192.168.56.13:5000neo4j-node4
dbms.connectors.default_listen_address=192.168.56.13
dbms.connectors.default_advertised_address=192.168.56.13
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.discovery_members=192.168.56.11:5000,192.168.56.12:5000,192.168.56.13:5000如上内容配置完成之后依次启动集群中core节点
$ neo4j-node2$ ./bin/neo4j start
$ neo4j-node3$ ./bin/neo4j start
$ neo4j-node4$ ./bin/neo4j start启动完成之后登陆到响应的web界面,然后查询集群详情就能看出来相关集群的配置是否正确
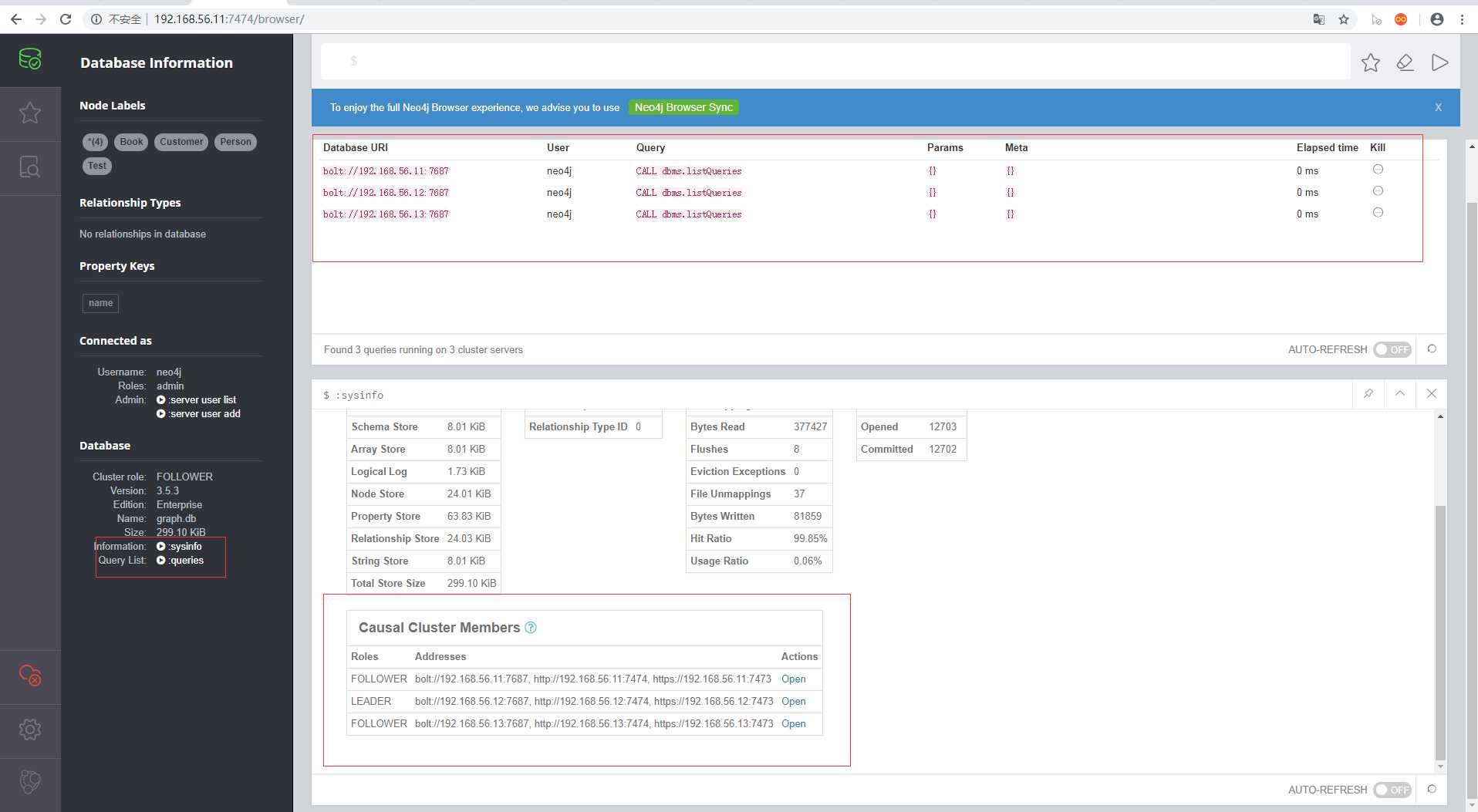
添加新的节点到集群中,这里使用新的节点neo4j-node5来进行操作
conf/neo4j.conf
dbms.connectors.default_listen_address=192.168.56.14
dbms.connectors.default_advertised_address=192.168.56.14
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.discovery_members=192.168.56.11:5000,192.168.56.12:5000,192.168.56.13:5000在配置新的机器到Core集群中作为Core节点时配置基本和上面的一样,但是需要注意的是causal_clustering.discovery_members这个配置,这个配置还是上面的配置,并没有将目前的机器加入,是因为当前的机器是新加入的,不是永久存在的集群,当不使用的时候可以将当前机器剔除集群,如果一开始就规划好了集群,那么开始就配置完整
neo4j-node5配置完成之后,启动该节点,启动完成之后需要登录当前节点,登录完成之后查看当前节点是否加入集群中,查看方式和上面的查看方式相同,或者可以看日志,是否加入集群,并且拥有集群id
启动
$ neo4j-node5$ ./bin/neo4j start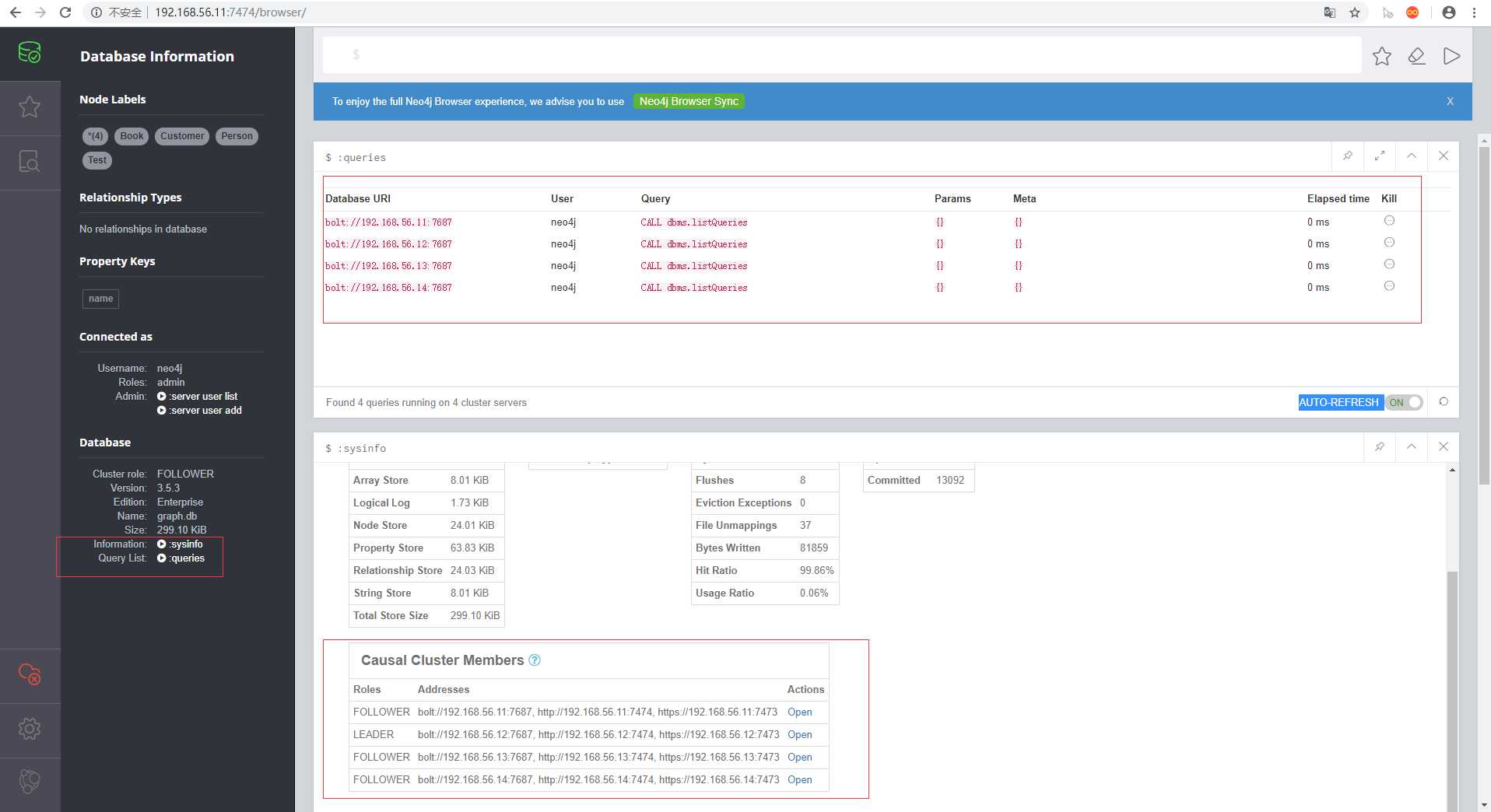
下面是添加Replicas角色节点,在集群中他是可有可无的,没有他集群也能够正常的工作,有他的存在是扩展了查询和过程分析能够多了一些节点来进行处理,但是该节点的数据均是来源于Core节点
还是用neo4j-node5来进行试验
conf/neo4j.conf配置
dbms.connectors.default_listen_address=192.168.56.14
dbms.mode=READ_REPLICA
causal_clustering.discovery_members=192.168.56.11:5000,192.168.56.12:5000,192.168.56.13:5000该节点不参与集群中的Leader选举所以配置相对简单
修改完成之后启动
$ neo4j-node5$ ./bin/neo4j start启动完成之后如果是新节点需要先访问当前的web服务设置好密码之后,接着可以到集群中任意节点查询节点是否添加到集群中
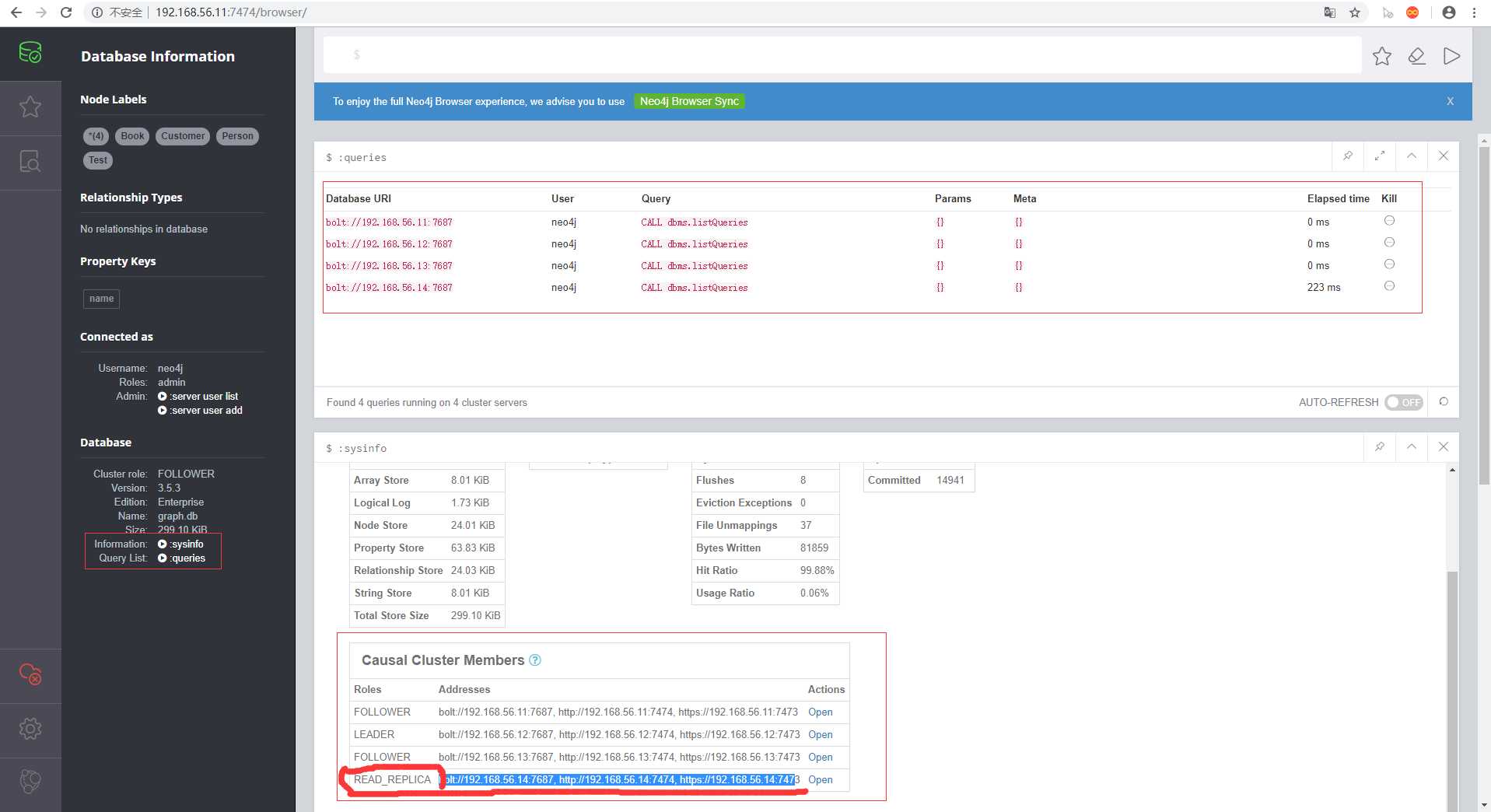
如上图所示,说明成功添加到集群中
pom.xml
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.7.2</version>
</dependency>访问实例:
public Driver createDriver() throws URISyntaxException {
List<URI> rout = new ArrayList<>();
rout.add(new URI("bolt+routing://192.168.8.106"));
rout.add(new URI("bolt+routing://192.168.8.107"));
rout.add(new URI("bolt+routing://192.168.8.108"));
Driver driver = GraphDatabase.routingDriver(rout,AuthTokens.basic("neo4j","123456"),null);
return driver;
}
Driver访问集群:在访问因果集群的时候设置好集群的相关访问地址,驱动能够自己判断当前访问应该走那台机器,负载由集群自己实现,程序不用关心集群机器可用性,驱动会自己发现集群可用性,并且选择能够操作的机器进行操作!
web方式访问:上面的方式是通过代码的方式进行访问,这里是通过web进行访问,在web访问的时候写数据只能在leader节点,查询数据在所有节点都能进行查询,这里和上面的驱动访问是有区别的
注:这里暂时省略了,目前还没使用,一般的公司也用不到,而且还是收费的
标签:ted ocs imu 服务 数据 逻辑 author cat 输入密码
原文地址:https://www.cnblogs.com/mojita/p/12012693.html