标签:构造 设定 用户 在线 数据请求 线性 预测 ons margin
1.来源
本质上 GBDT+LR 是一种具有 stacking 思想的二分类器模型,所以可以用来解决二分类问题。这个方法出自于 Facebook 2014 年的论文 Practical Lessons from Predicting Clicks on Ads at Facebook 。
2.使用场景
GBDT+LR 使用最广泛的场景是 CTR 点击率预估,即预测当给用户推送的广告会不会被用户点击。点击率预估模型涉及的训练样本一般是上亿级别,样本量大,模型常采用速度较快的 LR。但 LR 是线性模型,学习能力有限,此时特征工程尤其重要。现有的特征工程实验,主要集中在寻找到有区分度的特征、特征组合,折腾一圈未必会带来效果提升。GBDT 算法的特点正好可以用来发掘有区分度的特征、特征组合,减少特征工程中人力成本。
3.CTR的流程
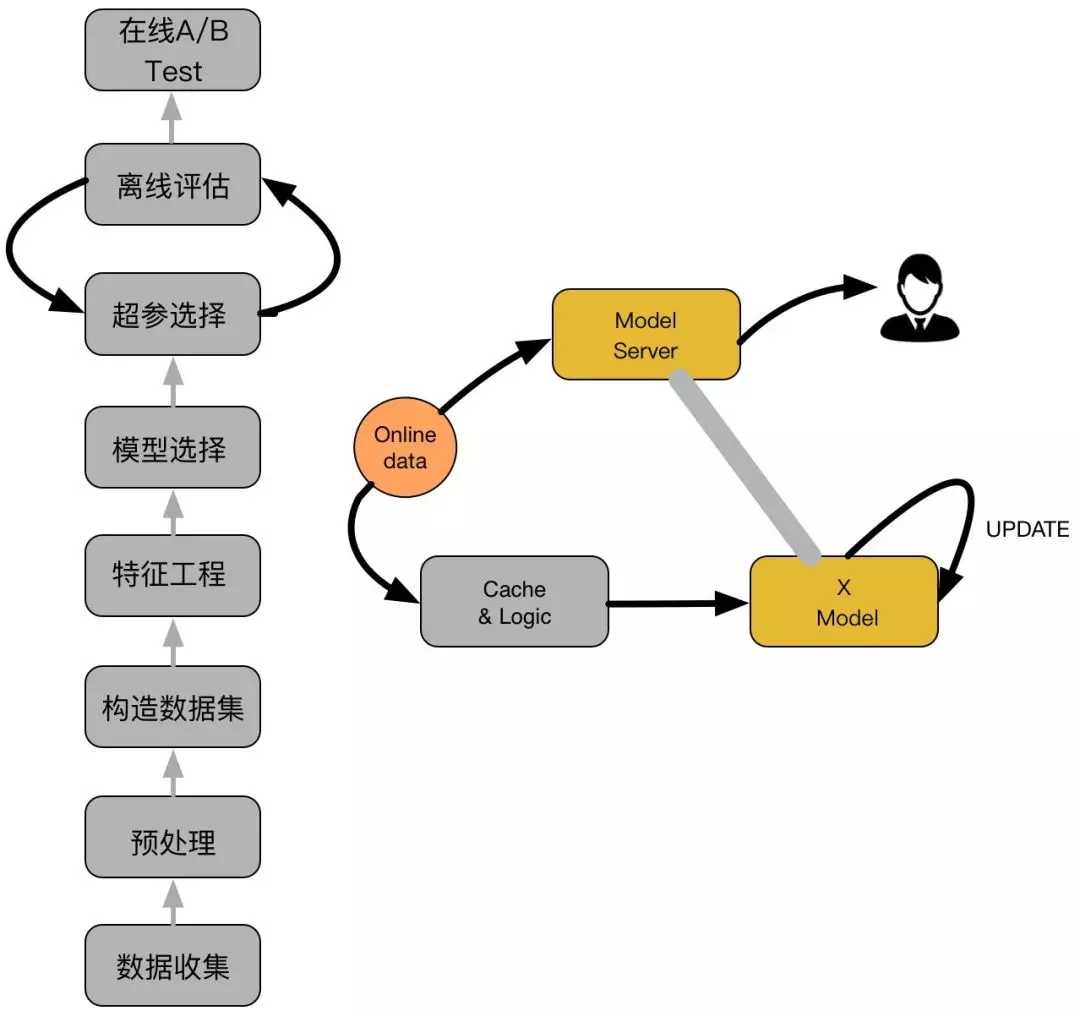
主要包括两大部分:离线部分、在线部分,其中离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,若出现这种情况,可选择使用 Online-Learning 来在线更新模型:
3.1离线部分
3.2 在线部分
标签:构造 设定 用户 在线 数据请求 线性 预测 ons margin
原文地址:https://www.cnblogs.com/tianqizhi/p/12012677.html