标签:ica market 完成 distance str 生态 区分 情况下 ini
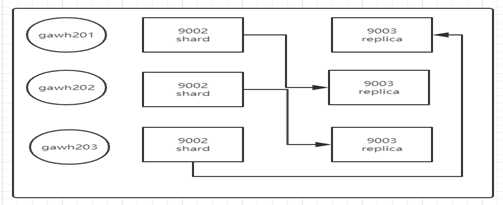
说明:
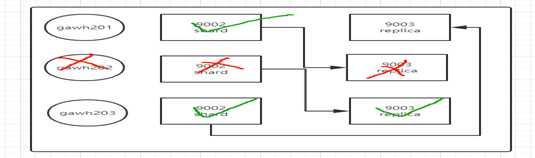
假设gawh202宕机了,如下图依然可以找到三个shard的数据(gawh202的shard的数据可以从gawh203的replica找到)
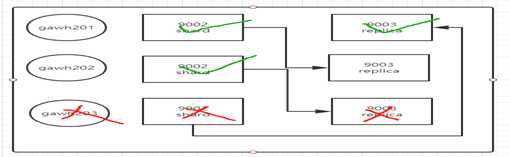
假设gawh203宕机了,如下图依然可以找到三个shard的数据(gawh203的shard的数据可以从gawh201的replica找到)
注意:
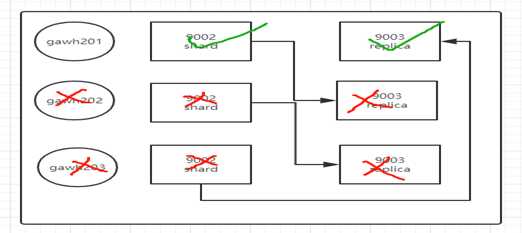
如果想要三节点集群两节点宕机数据保证一次性,那么只有在gawh201上将clickhouse服务扩展一个,但不建议这么做,一个节点上三个clickhouse服务会增加该节点的资源消耗影响性能
$: cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config1.xml$:vim /etc/clickhouse-server/config1.xml<log>/var/log/clickhouse-server/clickhouse-server1.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server1.err.log</errorlog>
<http_port>8124</http_port>
<tcp_port>9003</tcp_port>
<interserver_http_port>9010</interserver_http_port>
<path>/apps/clickhouse/data/clickhouse1</path>
<tmp_path>/var/lib/clickhouse1/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse1/user_files/</user_files_path>
原有的clickhouse服务的配置应该是这样的:
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<http_port>8123</http_port>
<tcp_port>9003</tcp_port>
<interserver_http_port>9009</interserver_http_port>
<path>/apps/clickhouse/data/clickhouse</path>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path>$:vim /etc/clickhouse-server/config.xml<include_from>/etc/clickhouse-server/metrika.xml</include_from>$:vim /etc/clickhouse-server/config1.xml<include_from>/etc/clickhouse-server/metrika1.xml</include_from>$:cp /etc/init.d/clickhouse-server /etc/init.d/clickhouse-server1在原有基础上修改以下项
$vim /etc/init.d/clickhouse-server1CLICKHOUSE_CONFIG=$CLICKHOUSE_CONFDIR/config1.xml
CLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM-1.pid"原有的clickhouse-server为
$vim /etc/init.d/clickhouse-serverCLICKHOUSE_CONFIG=$CLICKHOUSE_CONFDIR/config.xml
CLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM.pid"$:cp /etc/metrika.xml /etc/clickhouse-server/
$:cp /etc/metrika.xml /etc/clickhouse-server/metrika1.xmlmetrika*.xml共同部分:<yandex>
<clickhouse_remote_servers>
<!-- <perftest_3shards_2replicas> -->
<cluster>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh201</host>
<port>9002</port>
</replica>
<replica>
<host>gawh202</host>
<port>9003</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh202</host>
<port>9002</port>
</replica>
<replica>
<host>gawh203</host>
<port>9003</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh203</host>
<port>9002</port>
</replica>
<replica>
<host>gawh201</host>
<port>9003</port>
</replica>
</shard>
<!-- </perftest_3shards_2replicas> -->
</cluster>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper-servers>
<node index="1">
<host>gawh201</host>
<port>2182</port>
</node>
<node index="2">
<host>gawh202</host>
<port>2182</port>
</node>
<node index="3">
<host>gawh203</host>
<port>2182</port>
</node>
</zookeeper-servers>
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>gawh201实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>其中layer是双级分片设置,这里是01;然后是shard表示分片编号;最后是replica是副本标识,这里使用了cluster{layer}-{shard}-{replica}的表示方式,比如cluster01-02-1表示cluster01集群的02分片下的1号副本,这样既非常直观的表示又唯一确定副本
gawh201实例2(config1.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-2</replica>
</macros>gawh202实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>gawh202实例2(config2.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-2</replica>
</macros>gawh203实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-1</replica>
</macros>gawh203实例2(config1.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>说明:这其中的规律显而易见,这里不再说明
在三个节点上都执行如下脚本:
$: /etc/init.d/clickhouse-server start
$: /etc/init.d/clickhouse-server1 start启动无误后客户端进入每个服务进行验证:
gawh201上:
$:clickhouse-client --host gawh201 --port 9002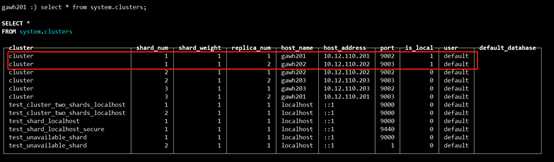
$: clickhouse-client --host gawh201 --port 9003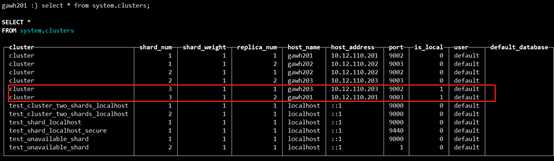
gawh202上:
$:clickhouse-client --host gawh202 --port 9002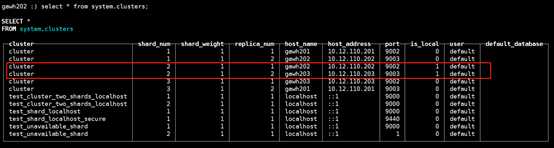
$:clickhouse-client --host gawh202 --port 9003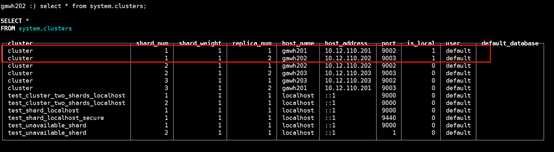
gawh203上:
$:clickhouse-client --host gawh203 --port 9002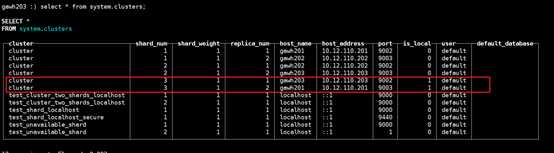
$:clickhouse-client --host gawh203 --port 9003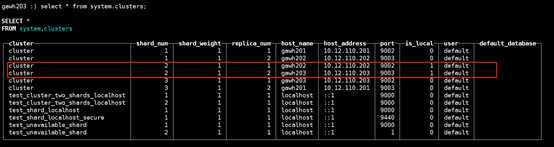
说明:仔细对比发现和之前的设计规划是完全吻合的,证明高可用clickhouse集群是部署成功的
zookeeper+ReplicatedMergeTree(复制表)+Distributed(分布式表)
ReplicatedMergeTree引擎表,以实例航班数据为例CREATE TABLE `ontime`( `Year` UInt16, `Quarter` UInt8, `Month` UInt8, `DayofMonth` UInt8, `DayOfWeek` UInt8, `FlightDate` Date, `UniqueCarrier` FixedString(7), `AirlineID` Int32, `Carrier` FixedString(2), `TailNum` String, `FlightNum` String, `OriginAirportID` Int32, `OriginAirportSeqID` Int32, `OriginCityMarketID` Int32, `Origin` FixedString(5), `OriginCityName` String, `OriginState` FixedString(2), `OriginStateFips` String, `OriginStateName` String, `OriginWac` Int32, `DestAirportID` Int32, `DestAirportSeqID` Int32, `DestCityMarketID` Int32, `Dest` FixedString(5), `DestCityName` String, `DestState` FixedString(2), `DestStateFips` String, `DestStateName` String, `DestWac` Int32, `CRSDepTime` Int32, `DepTime` Int32, `DepDelay` Int32, `DepDelayMinutes` Int32, `DepDel15` Int32, `DepartureDelayGroups` String, `DepTimeBlk` String, `TaxiOut` Int32, `WheelsOff` Int32, `WheelsOn` Int32, `TaxiIn` Int32, `CRSArrTime` Int32, `ArrTime` Int32, `ArrDelay` Int32, `ArrDelayMinutes` Int32, `ArrDel15` Int32, `ArrivalDelayGroups` Int32, `ArrTimeBlk` String, `Cancelled` UInt8, `CancellationCode` FixedString(1), `Diverted` UInt8, `CRSElapsedTime` Int32, `ActualElapsedTime` Int32, `AirTime` Int32, `Flights` Int32, `Distance` Int32, `DistanceGroup` UInt8, `CarrierDelay` Int32, `WeatherDelay` Int32, `NASDelay` Int32, `SecurityDelay` Int32, `LateAircraftDelay` Int32, `FirstDepTime` String, `TotalAddGTime` String, `LongestAddGTime` String, `DivAirportLandings` String, `DivReachedDest` String, `DivActualElapsedTime` String, `DivArrDelay` String, `DivDistance` String, `Div1Airport` String, `Div1AirportID` Int32, `Div1AirportSeqID` Int32, `Div1WheelsOn` String, `Div1TotalGTime` String, `Div1LongestGTime` String, `Div1WheelsOff` String, `Div1TailNum` String, `Div2Airport` String, `Div2AirportID` Int32, `Div2AirportSeqID` Int32, `Div2WheelsOn` String, `Div2TotalGTime` String, `Div2LongestGTime` String, `Div2WheelsOff` String, `Div2TailNum` String, `Div3Airport` String, `Div3AirportID` Int32, `Div3AirportSeqID` Int32, `Div3WheelsOn` String, `Div3TotalGTime` String, `Div3LongestGTime` String, `Div3WheelsOff` String, `Div3TailNum` String, `Div4Airport` String, `Div4AirportID` Int32, `Div4AirportSeqID` Int32, `Div4WheelsOn` String, `Div4TotalGTime` String, `Div4LongestGTime` String, `Div4WheelsOff` String, `Div4TailNum` String, `Div5Airport` String, `Div5AirportID` Int32, `Div5AirportSeqID` Int32, `Div5WheelsOn` String, `Div5TotalGTime` String, `Div5LongestGTime` String, `Div5WheelsOff` String, `Div5TailNum` String) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/ontime', 'cluster01-01-1') PARTITION BY toYYYYMM(FlightDate) ORDER BY (Year,FlightDate,intHash32(Year))注意:下面这种创ReplicatedMergeTree已经被弃用
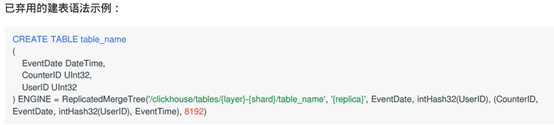
gawh201实例1(config.xml对应的)为:
‘/clickhouse/tables/01-01/ontime‘, ‘cluster01-01-1‘
gawh201实例2(config1.xml对应的)为:
‘/clickhouse/tables/01-03/ontime‘, ‘cluster01-03-2‘
gawh202实例1(config.xml对应的)为:
‘/clickhouse/tables/01-02/ontime‘, ‘cluster01-02-1‘
gawh202实例2(config1.xml对应的)为:
‘/clickhouse/tables/01-01/ontime‘, ‘cluster01-01-2‘
gawh203实例1(config.xml对应的)为:
‘/clickhouse/tables/01-03/ontime‘, ‘cluster01-03-1‘
gawh203实例2(config1.xml对应的)为:
‘/clickhouse/tables/01-02/ontime‘, ‘cluster01-02-2‘
解释:
ReplicatedMergeTree(‘/clickhouse/tables/01-01/ontime‘, ‘cluster01-01-1‘)
第一个参数为ZooKeeper 中该表的路
第二个参数为ZooKeeper 中的该表的副本名称
注意:
这里的配置要和每个clickhouse实例的metrika*.xml的macros标签对应,如果仔细看可以发现规律
CREATE TABLE ontime_all AS ontime ENGINE = Distributed(cluster, qwrenzixing, ontime, rand())在下载的航班数据目录,执行以下脚本:
for i in *.zip; do echo $i; unzip -cq $i '*.csv' | sed 's/\.00//g' | clickhouse-client --host=gawh201 –port=9002 --query="INSERT INTO qwrenzixing.ontime_all FORMAT CSVWithNames"; doneselect count(1) from qwrenzixing.ontime;节点 实例1(9002) shard 实例2(9002) replica
gawh201 59667255 59673242
gawh202 59670658 59667255
gawh203 59673242 59670658
结果已经非常明显了
select count(1) from qwrenzixing.ontime_all;数据总量:179011155
在gawh202节点上
$: /etc/init.d/clickhouse-server stop
$: /etc/init.d/clickhouse-server1 stop$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;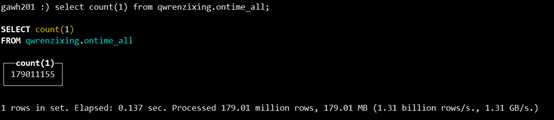
总量仍然没有变,证明对于查询单节点宕机数据一致性得到了保证,当然,当只有gawh203宕机,其他节点不宕机,结果和gawh202宕机是一样的
在gawh202,gawh203上均执行:
$: /etc/init.d/clickhouse-server stop
$: /etc/init.d/clickhouse-server1 stop$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;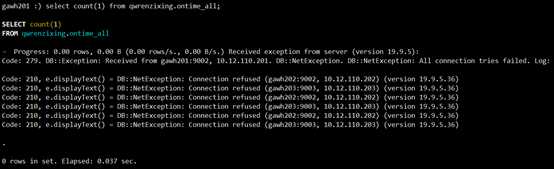
直接报错,可见在该方案中,gawh201作为主节点不能宕机,gawh202,gawh203只允许一个节点宕机。
drop table ontimedrop table ontime_all注意:
clickhouse不支持delete from table所以只能删表
按照3.2,3.3,,3.4步骤写入数据
这里写入实例航班数据(179011155)需要10分钟左右
参照3.6的a
$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;
可见数据写入一致性方案是成功的
从上面的步骤中可以看出基于zookeeper + ReplicatedMergeTree (复制表) + Distributed(分布式表)的高可用及数据一致性方案是非常繁琐的,包括配置,创复制表,这是因为clickhouse是对于集群和高可用时手动挡的,不像hadoop生态的数据库hive,hbase那样对分布式这块简单便捷。但集群越扩越大,该方案会带来配置和维护的巨大成本
这里因为机器少的原因,所以在每个节点都起两个clickhouse服务实例,如果机器充足,每个实例一个节点。在配置分片和备份的时候相互两两关联。但权衡来看,这样会,这不是一个很好的方案,因为在集权健壮的情况下。一个节点一个实例有点浪费资源。而且许多节点在集群健壮下都不会发挥作用
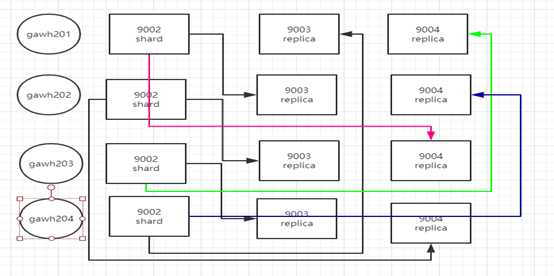
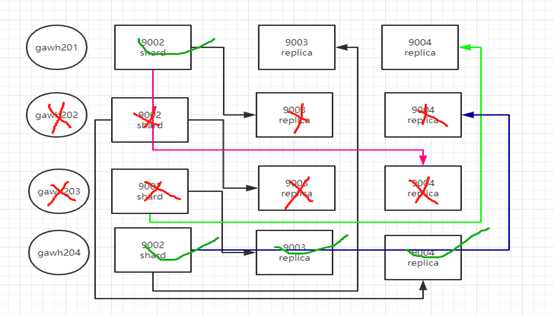
如上图实例,肯定是可以保证的,但是节点gawh204压力会加大,从这里也可以看出超大集群保证高可用和数据一致性会是比较简单但却繁琐的问题
标签:ica market 完成 distance str 生态 区分 情况下 ini
原文地址:https://www.cnblogs.com/jiashengmei/p/12015954.html