标签:style http io color sp strong 数据 on bs
机器自动识别验证码的原理是怎么样的?
我自己写验证码识别模块的时候是这样的,当然不一定大家都这样写,肯定有更好的算法,我要识别的那个验证码是比较简单地那种,所以这样写就够了。
我用Windows的画图工具画了这个张图,用来举个例子: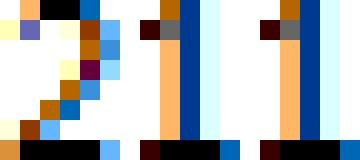
这是一张分辨率为19*7的图片
0 1 1 1 1 0 0
1 1 0 0 1 1 0
0 0 0 0 1 1 0
0 0 0 1 1 1 0
0 0 0 1 1 0 0
0 0 1 1 0 0 0
0 1 1 0 0 0 0
1 1 1 1 1 1 0
就像这样的数据,开了自动换行,应该比较好认了,摘掉眼镜快速滑动页面也可以比较清楚地看清这些数据的内容。
另外还有一种人肉分布式验证码识别”技术“,专门开发一个客户端软件给没事干的大学生打码赚些小钱。服务端获取到验证码后分发给在线的客户端,客户端人肉识别,返回结果。如果在线人数足够多,任务下达后几乎都是秒回的,效率也是不错的,进程等待验证码从人肉识别机上返回的时间就挂起,不怎么占用CPU时间。现在业界人肉打码机大概是这个价。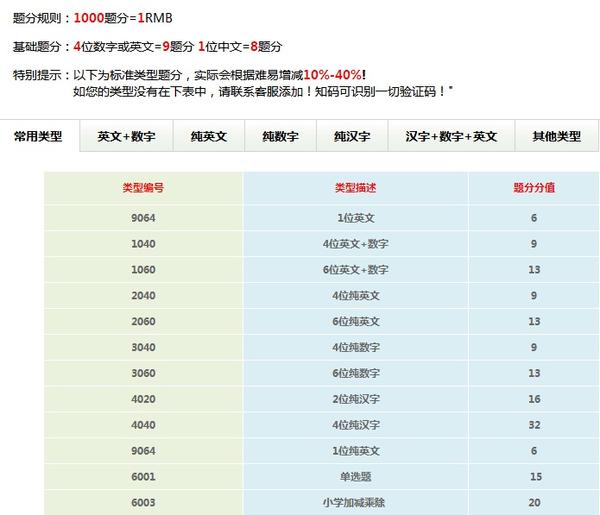
- 识别不同验证码也分难度等级吗?
根据上面的识别原理,可以确定识别难度肯定分等级。从步骤1和2看,噪点多、干扰线条多、背景颜色紊乱的肯定难识别,因为会在二值化那里遇到困难,最容易识别的肯定是噪点少、干扰线条少、背景颜色统一的验证码。
不过验证码要达到人可以识别的程度,肯定主体部分(验证码)的RGB值还是有一定的规律的,也就是可以通过一定的判断来二值化。像主体部分,一般颜色要比背景深,根据不同的情况设计算法是可以区分背景和正体的。
- 什么样的验证码识别起来简单?

这个是弱验证码的典型,2006年那时候我刚开始做网站开发时,当时最热门的那几个论坛程序就在用这种验证码,现在那几个论坛停更了好多,所以还有不少网站现在还在用这种验证码。
★★☆☆☆☆☆☆☆☆

这个也是弱验证码的典型,比上面那个好不了多少,虽然背景加入了大量干扰点,但是颜色偏淡,可以在二值化中直接设置一个阈值直接干掉,正确的做法应该是加入和验证码本体颜色一致的干扰线和干扰点,理论上说数量越多越好。
★★★☆☆☆☆☆☆☆

这个又比上面那个好一些了,干扰点和验证码正文颜色都非常随意,遗憾的都是非常分散的点,很容易被识别出来并过滤掉。如果换成若干条和正文颜色相同、并且与正文交叉的细线会好一些。
★★★★☆☆☆☆☆☆
- 什么样的验证码识别起来难?
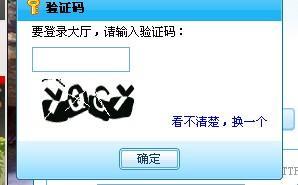
难以识别的验证码1:大量背景、线、点干扰,而且字体有一定程度的旋转,连人眼都难以识别的验证码(影响第1、2步的识别),线的干扰在这里起作用比较明显。★★★★★★☆☆☆☆
最难以识别是每个字符都粘连在一起的,这些会在第3步(切割字符)和第4步匹配已有数据(每次的字体扭曲程度都是不同的,难以匹配)时遇到困难。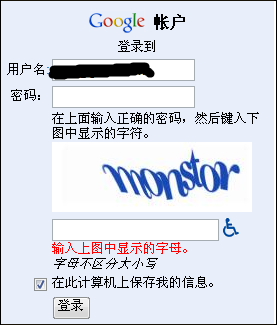
难以识别的验证码2:没有干扰点、背景也很干净、也没有干扰线,就靠不规则每次都不同的字体和字符粘连,就可以让写验证码识别的人头疼好久。(影响第3、4步的识别)
★★★★★★★★☆☆
另外英文还是比较Naive的,中文识别难度不知道要比英文高到哪里去,以百度贴吧为例: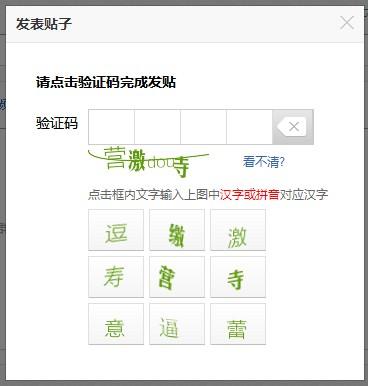
难以识别的验证码3:
1、干扰线
2、加粗不加粗混用
3、采用了中文常用字。中文常用字大概有5000个,笔画繁复,形似字多,比起26个字母不知道高到那里去!
4、不同的字体混用,比如楷体、宋体、幼圆混用
5、形近字:”缴“和”激“、”寿“和”寺“等等
6、拼音,又是一大杀器
7、扭曲字体(”营“字有比较明显的扭曲)
8、需要准确识别13位汉字,增加了失败概率
(全面影响所有识别步骤)
汉字粘连后识别度不如英语高,所以一般汉字验证码都不粘连。
★★★★★★★★★☆
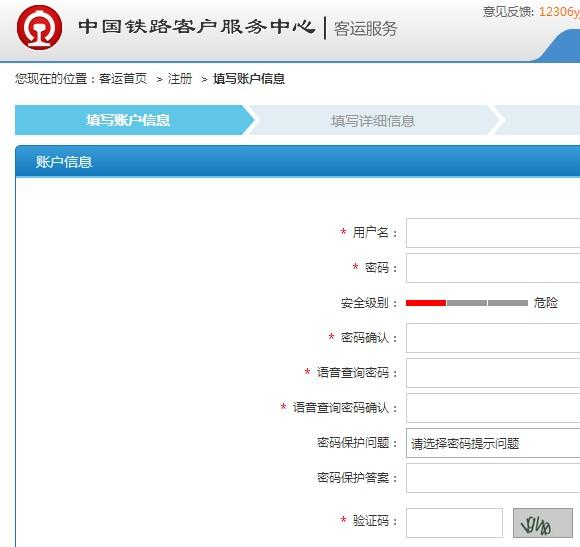
如果把旋转和粘连程度调得非常高的话,机器识别错误率就会很高了(甚至连人的识别错误率都会很高)。好在现代网页大都配备了Ajax验证码检测的判断,因此可以通过网站预留的接口多次尝试判断来获取验证码,1次失败,就试上20次,总有1次能成功的。
★★★★★★★★★★
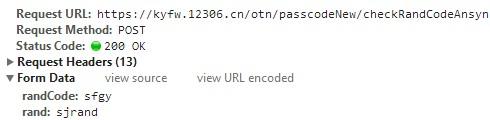
因此像这种网站应该做的改变就是通过该Ajax判断接口查询验证码是否正确,如果错误,则清除session中的验证码数据,重新获取验证码。(验证码在登陆页是必须存在的,防止暴力破解弱口令,如果是生日类的8位数字密码,要暴力破解出来实在是太容易了)
标签:style http io color sp strong 数据 on bs
原文地址:http://www.cnblogs.com/shiddong/p/4063620.html