标签:因此 style map ash 结果 工作 一个 文件加载 关联
大表和小表关联查询可以采用mapjoin优化查询速度。
那什么是mapjoin呢?
理解MapJoin之前先介绍另一种Join方式,CommonJoin。
我们知道Hive编写SQL语句,Hive会将SQL解析成MapReduce任务。
对于一个简单的关联查询,CommonJoin任务设计Map阶段和Reduce阶段。
Mapper 从连接表中读取数据并将连接的 key 和连接的 value 键值对输出到中间文件中。Hadoop 在所谓的 shuffle 阶段对这些键值对进行排序和合并。Reducer 将排序结果作为输入,并进行实Join。Shuffle 阶段代价非常昂贵,因为它需要排序和合并。
因此减少 Shuffle 和 Reduce 阶段的代价可以提高任务性能。
MapJoin 的目的是减少 Shuffle和 educer阶段的代价,并仅在 Map 阶段进行Join。
MapJoin的工作机制如图:
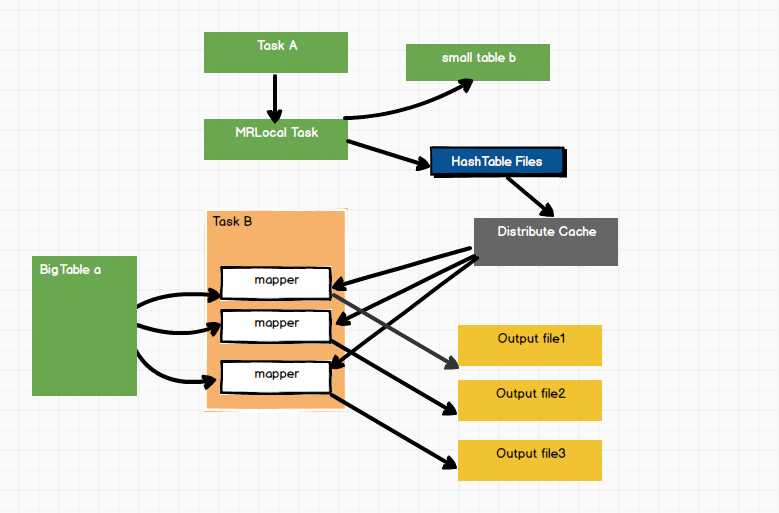
1)Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到分布式缓存DistributeCache中。
2)Task B,该任务是一个没有Reduce的MR,启动MapReduce扫描大表。在Map阶段,根据a的每一条记录去和DistributeCache中的b对应的HashTable关联,并直接输出结果。
3)由于MapJoin没有Reduce,所以Map直接输出结果文件,有多少MapTask,就有多少个结果文件。
在命令行开启MapJoin功能:
set hive.auto.convert.join=true;
Hivev0.7之前,需要使用hint提示/*+mapjoin(table)*/才会执行MapJoin。
0.7之后默认值为true,默认开启MapJoin。
Hive能自动判断哪个表是小表,那么多小的表才是小表呢?
由参数hive.mapjoin.smalltable.filesize=25000000决定,默认是25M。
因此小表在jion的前面和后面,效果都是一样的,因为Hive自动判断谁是小表,将其加载到内存。
select b.* from bigtable b join smalltable s on s.id = b.id;
select b.* from smalltable s join bigtable b on s.id = b.id;
标签:因此 style map ash 结果 工作 一个 文件加载 关联
原文地址:https://www.cnblogs.com/lucas-zhao/p/12025000.html