标签:tail font sql ext scala bec res prope exp
一 编译
以spark2.4 hadoop2.8.4为例
1,spark 项目根pom文件修改
pom文件新增
<profile>
<id>hadoop-2.8</id>
<properties>
<hadoop.version>2.8.4</hadoop.version>
</properties>
</profile>
2,在spark home 目录下执行
mvn -T 4 -Pyarn -Phadoop-2.8 -Dhadoop.version=2.8.4 -DskipTests clean package
为了加快执行
编译 dev目录下
vi make-distribution.sh 修改 #VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null# | grep -v "INFO"# | grep -v "WARNING"# | tail -n 1) #SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null# | grep -v "INFO"# | grep -v "WARNING"# | tail -n 1) #SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null# | grep -v "INFO"# | grep -v "WARNING"# | tail -n 1) SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null | grep -v "INFO" | grep -v "WARNING" | fgrep --count "<id>hive</id>"; # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing # because we use "set -o pipefail" echo -n) VERSION=2.4.0 SCALA_VERSION=2.11.8 SPARK_HADOOP_VERSION=2.8.4
3, 完成 maven编译 进行打包
在spark根目录下执行
./dev/make-distribution.sh --name hadoop2.8 --tgz -PR -Phadoop-2.8.4 -Phive -Phive-thriftserver -Pyarn
问了加快编译 修改dev目录下
执行完毕在spark_home 根目录下 即生成相应版本的jar包
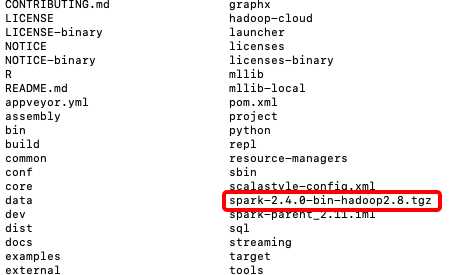
二 远程Debug
1. 编译远程spark项目下的文件
spark-2.4.0-bin-hadoop2.8/conf/spark-defaults.conf
增加内容如下 这个用来调试spark driver端代码
spark.driver.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=n,address=你本机的ip:5007,suspend=y
同样调试 excutor也可以如此 只需要 在spark.executor.extraJavaOptions 新增内容即可
2 我们将spark源码import到idea中
配置远程debug
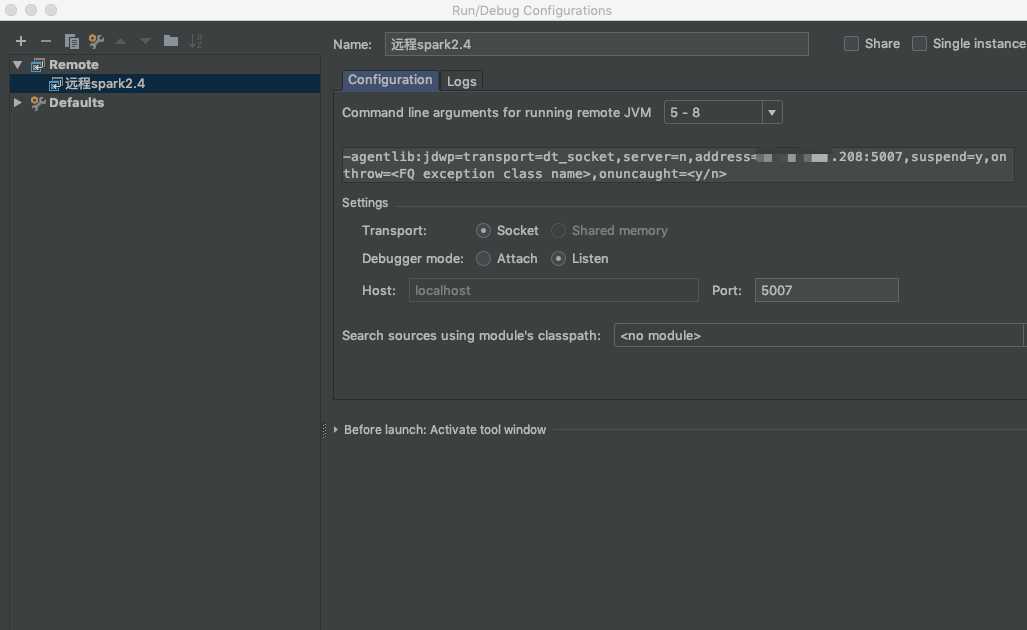
这里因本地网跟远程不通 所以采用listen模式
先启动本地 idea spark项目 debug 再启动远程的spark任务
如图
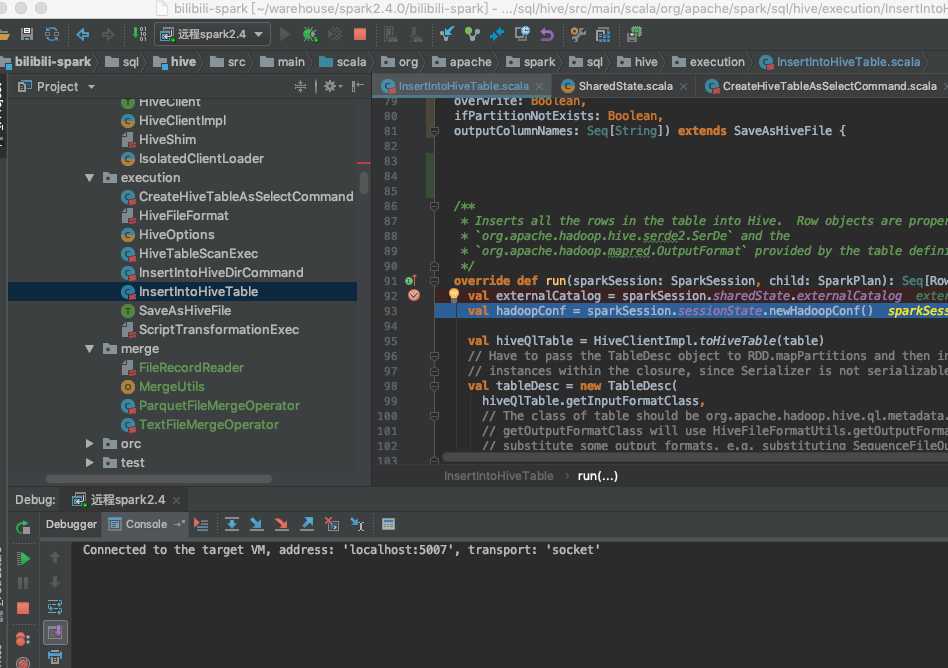
下面就是 injoy yourself
标签:tail font sql ext scala bec res prope exp
原文地址:https://www.cnblogs.com/songchaolin/p/12028356.html