标签:表示 efi 重要性 bash 词频统计 targe strong ice hmm
概括:朴素贝叶斯分类器(Naïve Bayes classifier)是一种相当简单常见但是又相当有效的分类算法,在监督学习领域有着很重要的应用。朴素贝叶斯是建立在“全概率公式”的基础下的,由已知的尽可能多的事件A、B求得的P(A|B)来推断未知P(B|A),是的有点玄学的意思,敲黑板!!!
优点:
缺点:
tf-idf经常被用于提取文章的关键词(Aoutomatic Keyphrase extraction),完全不加任何的人工干预,就可以达到很好的效果,而且它简单到都不需要高等数学,普通人10分种就可以理解,那我们首先来介绍下TF-IDF算法。
TF-IDF
例如,假定现在有一篇比较长的文章《致全世界儿童的一封公开信》我们准备用计算机提取它的关键词。一个简单的思路,就是找到出现次数最多的词。如果这个词很重要,它应该在这篇文章中出现很多次。于是,我们进行“词频”(Term Frequency,缩写为TF)统计,不过你可能会猜到,出现最多的词是---“的”、“是”、“在”----这一类最常用的词。它们叫做“停用词”(stop words)表示对提取结果毫无帮助、必须要过滤掉的词,这是你可能会问,从“文章”到“词”你是怎么转换的,如果你知道中文分词,就应该不会问这个问题了,中文分词有很多模式,通常是采用HMM(隐马尔科夫模型 ),一个好的分词系统非常复杂,想要理接可以点击HMM的进行了解,不过现在也有很多系统使用深度学习的方法NER(lstm+crf)来做物品词识别,这里就不一一介绍了;ok,回到之前所说的,我们可能发现“儿童”、“权力”、“心理健康”、“隐私”、“人口流动”、“冲突”、“贫困”、“疾病”、“食物”、“饮用水”、“联合国”这几个词出现的次数一样多。这是不是意味着,作为关键词,他们的重要性是一样的?
显然不是这样。因为“联合国”是很常见的词,相对而言“心理健康”、“人口流动”、“冲突”不那么常见。如果这四个词出现的次数一样多,有理由认为,“心理健康”、“人口流动”、“冲突”的重要程度要大于“联合国”,在关键词排序上“心理健康”、“人口流动”、“冲突”应该排在“联合国”的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是很常见。如果这个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。这个调整系数就是在词频统计的基础上,要对每个词分配一个“重要性”权重。这个权重叫做“逆文档频率”(Inverse Document Frequency,缩写为“IDF”),它的大小与一个词的常见程度成反比。
知道了“词频”(TF)和“逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词;如果应用到文本分类中,把一类中所有的tf-idf值高的词和tf-idf值 提取出并来,这就是此类的特征模型。
总结一下:
TF = (某个词在文档中出现的次数) / (文档中的总词数)IDF = log(语料中文档总数 / 包含该词的文档数+1) 分母加1 避免分母为0TF-IDF = TF*IDF朴素贝叶斯推断
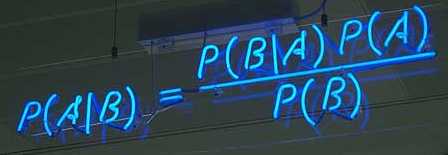
朴素贝叶斯理论看起来很高大上,但实际上并没有运用很高深的数学知识,即便没有学习过高数也完全可以理解,给我的感觉就是简单但有些绕,接下来我将用尽可能直白的话解释下朴素贝叶斯理论。
贝叶斯推断是一种统计学方法,用来估计统计量的某种性质,与其他的统计学推断不同,它建立在主观判断的基础上,也就是说,你可以不需要客观证据,先估计一个值,然后根据实际结果不断修正。
这里可能有人会问,tf-idf就能用来做分类了,为什么还要朴素贝叶斯?是的,问得好,tf-idf确实可以进行分类,但朴素贝叶斯会有效增强准确率削弱错误率(如果你之前了解过深度学习,朴素贝叶斯起到的效果有点像softmax),朴素贝叶斯是建立在“全概率公式”的基础下的,由已知的尽可能多的事件A、B求得的P(A|B)来推断未知P(B|A),是的有点玄学的意思,敲黑板!!! 这也就决定了它和tf-idf这种统计学的概率的本质区别。
贝叶斯定理:要理解贝叶斯推断,首先要知道贝叶斯定理。后者实际上是计算“条件概率”的公式。
所谓“条件概率”(Conditional probability),就是指事件B发生的情况下,事件A发生的概率,用P(A|B)来表示,嗯,没错就是上图哪个公式。上学那会老师这公式都要背熟的,不然数学第二个简答题就只能写个解了,但是我们今天来看一下这个公式的推理过程:
标签:表示 efi 重要性 bash 词频统计 targe strong ice hmm
原文地址:https://www.cnblogs.com/go-ahead-wsg/p/11669042.html