标签:一个 重要 RKE src alt 随机 系统 存储引擎 png
分布式环境下如何保证ID的不重复呢?一般我们可能会想到用UUID来实现嘛。但是UUID一般可以获取当前时间的毫秒数再加点随机数,但是在高并发下仍然可能重复。最重要的是,如果我要用这种UUID来生成分表的唯一ID的话,重复不谈,这种随机的字符串对于我们的innodb存储引擎的插入效率是很低的。所以我们生成的ID如果作为主键,最好有两种特性:分布式唯一和有序。
唯一性就不用说了,有序保证了对索引字段的插入的高效性。我们来具体看看ShardingJDBC的分布式ID生成策略是如何保证。

sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID)。
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如MySQL的Innodb存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
大专栏 分布式ID生成策略 · fossi雪花算法主键的详细结构见下图。
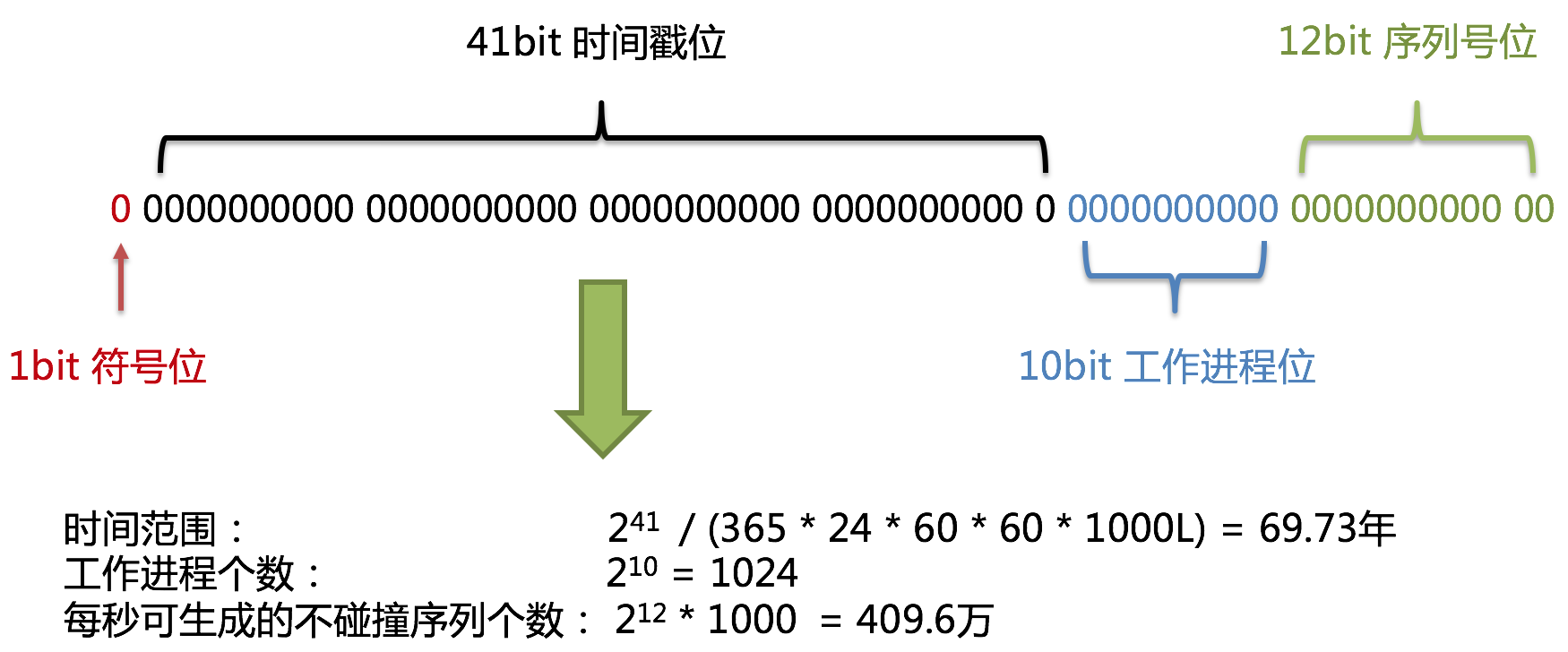
预留的符号位,恒为零。
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
1 | Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); |
结果约等于69.73年。ShardingSphere的雪花算法的时间纪元从2016年11月1日零点开始,可以使用到2086年,相信能满足绝大部分系统的要求。
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过调用静态方法DefaultKeyGenerator.setWorkerId()设置。
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为0,可通过调用静态方法DefaultKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds()设置。
标签:一个 重要 RKE src alt 随机 系统 存储引擎 png
原文地址:https://www.cnblogs.com/lijianming180/p/12041145.html