标签:proc tran rally tput ant 技术 any eccv rest
With the deep learning method being applied to image super-resolution (SR), SR methods based on deep learning have achieved better reconstruction results than traditional SR methods. This paper briefly summarizes SR methods based on deep learning, analyzes the characteristics and deficiencies of different network models and compares various deep learning network models on mainstream data set.
Keyword: Image super-resolution reconstruction; deep learning; convolutional neural network
Image super-resolution reconstruction is to recover a corresponding high-resolution image from a low-resolution image. For SR can repair the damage caused to the image by the imaging equipment or the environment, SR is widely used in medical[1], satellite imagery, security monitoring[2] and other fields. The early traditional SR methods mainly focus on interpolation methods. Such methods are relatively easier to implement, but the reconstruction effect is not good. In recent years, with strong capabilities of feature extraction, deep learning has led to a dramatic leap in Super-Resolution (SR) performance in the past few years. Many end-to-end networks have been proposed to learns mapping relations between low-resolution images and high-resolution and then use it to reconstruct the image.
Since deep learning was first applied to super-resolution, dozens of network models have been proposed for SR, which can be divided into convolutional neural network models, residual learning models, densely connected residual network models and generative adversarial network models.
Super-Resolution models based on the convolutional neural network are different from general convolutional neural network models, which generally do not include pooling layers and fully connected layers. SRCNN4] is the first deep learning model proposed for super-resolution reconstruction The models ESPCN5] and FSRCNN[6] improve SRCNN in the reconstruction method and computing efficiency. ESPCN efficiently completes the reconstruction by introducing a sub-pixel convolutional layer. Convolutional neural network models generally have a shallow network structure. Simply deepening the depth of a convolutional neural network often makes it more difficult to converge the networks. Among them, SRCNN only includes three convolutional layers, and the size of the receptive field of the network is 13. Small receptive fields use a smaller part of low-resolution image information to reconstruct images, which is largely constrain the effect of reconstruction.
Shallow network models generally have small receptive fields, which restricts the reconstruction effect and deep convolutional neural networks are difficult to train. The residual network has the ability to resist degradation, so the model based on residual learning makes full use of these characteristics. The network only needs to learn the residual mapping relationship between low-resolution images and high-resolution images. Because it directly learns the mapping relationship between low-resolution images and high-resolution images, it reduces the complexity of network parameters and reduces the learning difficulty to a certain extent. Therefore, the model based on residual learning [7, 8] is generally a deeper network structure.
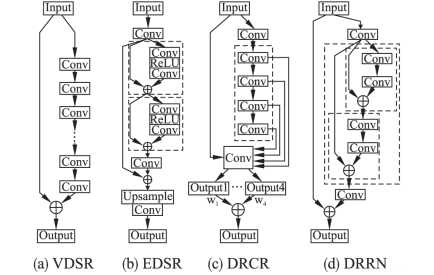
The network structure proposed by VDSR [9] introduces global residual learning, and successfully deepens the network layer to 20 layers and increased its receptive field to 41 × 41 (compared to SRCNN‘s 13 x 13). EDSR[10] deepens the network by only overlapping multiple residual units and introducing global residual learning in the network, and finally builds a network model for a particular reconstructed magnification scale. In addition, DRCN[11] and DRRN[12] deepen the network by adding recursive residual units, This method can make the network deepen without increasing network parameters. DRCN includes 16 recursive layers, and the receptive field of the entire network reaches 41 × 41. DRRN deepens the network structure to 52 layers by add recursive the residual network block.
The low-resolution images lost a lot of high-frequency information compared to the high-resolution images, and every pixel should be repaired with the information from its surroundings. So when reconstructing high-resolution images, we expect to provide as much low-resolution image information as possible. This requires not only the network to have a larger receptive field, but also to make full use of the hierarchical feature information extracted by the network. The hierarchical feature combination model introduces dense-skip-connection in the network to fully utilize the hierarchical feature information in the network, providing more and richer feature information for reconstructing high-resolution images, which helps the network performs more accurate image reconstruction.
MenNet[13] uses Memory Block as the network unit to densely jump-connect the Memory block in the network. The purpose is to make the network adaptively learn the ability of continuous memory. Similarly, each residual unit is connected to the end in the memory block——Gate Unit, which combines hierarchical features with the output of the previous Memory block. SRDenseNet[14] uses dense blocks as the basic unit of the network, and the output of every dense unit is connected to the last convolutional layer to combine the hierarchical feature. RDN13] introduces residual learning to dense blocks——residual block as the basic unit of the network and connects the jumps of each residual dense network unit to a 1 * 1 convolution layer at the end of the model for feature combination. The models based on hierarchical feature combination make full use of local and global feature information so that the feature information of each layer in the deep network is fully integrated and utilized, providing the network with better reconstruction results.
With general deep learning neural network models, non-linear mapping relationship is built between the low-resolution image and the high-resolution image. However, general networks with mean square error (MSE) loss function often predict results with smoother texture and lose some details and high-frequency information in real high-resolution images. Although good results have been obtained in the evaluation of PSNR indicators, they may not achieve good human visual perception. Through the game between the generator and the discriminator, the image generated by the generator can be made closer to the real high-resolution image, and the high-frequency details of the image can be reconstructed more accurately.
In SRGAN[15], deep generative networks are built by stacking multiple residual blocks, and discriminative networks consisting of 8 convolution layers are also constructed. The entire network is optimized by the game of the generator and the discriminator and Nash equilibrium Balance finally attained by these 2 networks.
Train the generation model so that the images it generates can cheat the discrimination model, making it difficult for the discrimination model to distinguish whether the image is a real image or a generated image. The purpose of training a discrimination model is to make it possible to distinguish as much as possible whether the image is a real image. In addition, the author optimized the loss function of the generator. The perceptual loss function is proposed. It consists of three parts: content loss, adversarial loss, and regularization loss. This makes the image generated by the entire generative adversarial model much closer to the real image.
Image super-resolution reconstruction is important in the field of computer vision. Because it can promote other work in the field of computer vision, such as image recognition, image segmentation, etc., which is of considerable significance. Super-resolution reconstruction based on deep learning has made great progress, however, there are still many problems we need to study.
1) Deeper and more combinational network structure. For SR networks, greater depth means larger receptive fields. The residual information is used to reconstruct the characteristic information of each layer in the combination network. It can provide more reference information for SR, and the SR effect of the network will be improved accordingly.
2) Improve the loss function. The current common loss functions are basically based on MSE. The results show that this loss function can make the network achieve better PSNR. However, it often makes the reconstructed image too smooth and loses details of high-frequency information. The degradation model of real low-resolution images still needs to be studied to improve the loss function, so that the network can produce SR result closer to the real image.
3) Optimize generative adversarial networks. Through adversarial learning, generative adversarial networks can make the SR images of the network have more high-frequency details and closer to real images. However, there are still many problems with generative adversarial networks, such as difficult training, instability, etc. So optimizing generative adversarial networks will be the next research hotspot.
4) More scientific and accurate evaluation standards. At present, the main indicators for evaluating the effect of image reconstruction are PSNR and SSIM, but some images with high PSNR and SSIM values are not necessarily high quality. Therefore, PSNR and SSIMare not scientific and accurate enough to evaluate the quality of images, and the existing subjective evaluation is complicated, requires a lot of manpower and is difficult to operate. More accurate image evaluation standards should be obtained by studying the structural characteristics of real high-resolution images, which also will be a hotspot in the research of image super-resolution reconstruction.
[1] Shi w,Caballero J,Ledig C,et al. Cardiac image super-resolution with global correspondence using multi-atlas patchmatch [J] . Med Image Comput Comput Assist Interv,2013,16(3) :9-16.
[2] Zou W W w , Yuen P C. Very low resolution face recognition prob- lem [J] . IEEE Transactions on Image Processing, 2012, 21 ( 1) :35-340.
[3] Sun J,Sun J,Xu Z,et al. Image super-resolution using gradient profile prior [C] //IEEE Conference on Computer Vision and Pat- tem Recognition,2008:1-8.
[4] Dong C,Loy C C,He K,et al. Image super-resolution using deep convolutional networks [m . IEEE Trans Pattem Anal Mach Intell, 2014,38(2):295-307.
[5] Shi W,Caballero J,Huszor F,et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network [C] //IEEE Conference on Computer Vision and Pattern Recognition,2016:1874-1883.
[6] Dong C,Chen C L,Tang X.Accelerating the super-resolution con- volutional neural network [C] //European Conference on Computer Vision(ECCV),2016:391-407.
[7] Kang E, Yoo J,Ye J C.Wavelet residual network for low-tose CT via deep convolutional framelets [J] . IEEE Transactions on Medi- cal Imaging ,2017,37(6) :1358-1369.
[8] Zhong Z,Zhang X Y,Yin F,et al. Handwritten Chinese character recognition with spatial transformer and deep residual netw orks [C]//Intemational Conference on Pattem Recognition, 2017: 1140-3445.
[9] Kim ],Lee J K,Lee K M.Accurate image super-esolution using very deep convolutional networks [C] //IEEE Conference on Com- puter Vision and Pattem Recognition,2016:1646-1654.
[10] Wang Y,Wang L,Wang H,et al. End-to-end image super-resolu- tion via deep and shallow convolutional networks [i] .2016:arXiv:1607.07680.
[11] Kim J,Lee J K,Lee K M.Deeply-recursive convolutional network for image super-resolution [C] //IEEE Conference on Computer Vision and Pattern Recognition,2016:1637-4645.
[12] Tai Y,Yang J,Liu X. Image super-resolution via deep recursive re- sidual network [C] //IEEE Conference on Computer Vision and Pattem Recognition,2017:590-598.
[13] Tai Y,Yang J,Liu X,et al. MemNet:a persistent memory network for image restoration [C] //IEEE Intemational Conference on Computer Vision(ICCV),2017:4549-4557.
[14] Tong T,Li G,Liu X,et al. Image super-resolution using dense skip connections [C] //IEEE Intemational Conference on Computer Vi- sion,2017:4809-4817.
[15] Ledig C,Theis L,Huszar F,et al.Photo-realistic single image su- per-resolution using a generative advensarial network [J] . arXiv:1609.04802,2016.
Review of Image Super-resolution Reconstruction Based on Deep Learning
标签:proc tran rally tput ant 技术 any eccv rest
原文地址:https://www.cnblogs.com/hercules-chung/p/12041484.html