标签:设置 detail hid oca zed tin str ini hat
本文参考了Redis源码3.0分支和《Redis设计与实现》。
Redis基于下面提到的底层数据结构创建了一个对象系统,这个系统包括String、List、Set、Hash、Sorted Set这五种对象,每种对象都用到了至少一种底层数据结构。Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type、encoding和ptr。
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;SDS是二进制安全的。
typedef char *sds;
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the
* end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatlen(sds s, const void *t, size_t len) {
struct sdshdr *sh;
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
sh = (void*) (s-(sizeof(struct sdshdr)));
memcpy(s+curlen, t, len);
sh->len = curlen+len;
sh->free = sh->free-len;
s[curlen+len] = '\0';
return s;
}
/* Append the specified null termianted C string to the sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}就是大家都学过的链表,方法名也大多顾名思义。
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
/* Functions implemented as macros */
#define listLength(l) ((l)->len)
#define listFirst(l) ((l)->head)
#define listLast(l) ((l)->tail)
#define listPrevNode(n) ((n)->prev)
#define listNextNode(n) ((n)->next)
#define listNodeValue(n) ((n)->value)
#define listSetDupMethod(l,m) ((l)->dup = (m))
#define listSetFreeMethod(l,m) ((l)->free = (m))
#define listSetMatchMethod(l,m) ((l)->match = (m))
#define listGetDupMethod(l) ((l)->dup)
#define listGetFree(l) ((l)->free)
#define listGetMatchMethod(l) ((l)->match)
/* Prototypes */
list *listCreate(void);
void listRelease(list *list);
list *listAddNodeHead(list *list, void *value);
list *listAddNodeTail(list *list, void *value);
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
void listDelNode(list *list, listNode *node);
listIter *listGetIterator(list *list, int direction);
listNode *listNext(listIter *iter);
void listReleaseIterator(listIter *iter);
list *listDup(list *orig);
listNode *listSearchKey(list *list, void *key);
listNode *listIndex(list *list, long index);
void listRewind(list *list, listIter *li);
void listRewindTail(list *list, listIter *li);
void listRotate(list *list);Dict的核心就是Separate Chaining Hash Table。
随着操作的不断进行,哈希表保存的键值对会逐渐地增多或减少,为了让哈希表的负载因子(USED/BUCKETS)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或太少时,程序需要对哈希表的大小进行相应的扩展或收缩。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。跳跃表的实现比平衡树更简单。
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplist *zslCreate(void);
void zslFree(zskiplist *zsl);
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj);
int zslDelete(zskiplist *zsl, double score, robj *obj);
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range);
zskiplistNode *zslLastInRange(zskiplist *zsl, zrangespec *range);
unsigned int zsetLength(robj *zobj);
void zsetConvert(robj *zobj, int encoding);
unsigned long zslGetRank(zskiplist *zsl, double score, robj *o);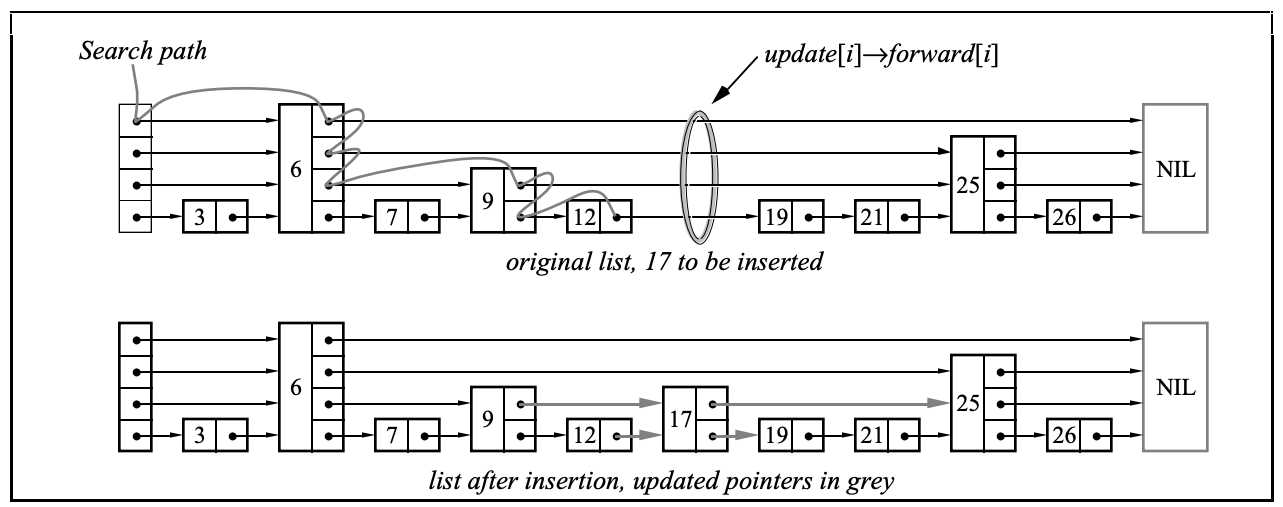
插入时的核心逻辑:
删除时的核心逻辑:
下面这个题可以使用平衡树来解,这里为了练习使用跳跃表,注意根据题意特殊处理。
SPOJ ORDERSET
其他底层数据结构还包括了压缩列表(Ziplist)和整数集合(Intset)等。
Redis对象通过encoding属性来设定对象所使用的编码,而不是为特定类型的对象关联一种特定的编码。Redis可以根据不同的使用场景来为一个对象设置不同的编码,从而优化对象在某一场景下的效率。Redis对象还会根据不同的条件,从一种编码转换成另一种编码。
不同类型和编码的对象:
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典实现的哈希对象 |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象 |
Set的编码可以是intset或hashtable。
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是字符串对象,字典的值则全部为NULL。
Sorted Set的编码可以是ziplist或skiplist。
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;底层数据结构编码为skiplist时,redisObject.ptr指向zset类型。
skiplist本身不支持通过key查value,zset使用dict字典为有序集合维护了一个从成员到分值的映射。
标签:设置 detail hid oca zed tin str ini hat
原文地址:https://www.cnblogs.com/ToRapture/p/12043897.html