标签:qos 规则 国际 mac head 计算 mos 高通 大致
语音质量评估,就是通过人类或自动化的方法评价语音质量。在实践中,有很多主观和客观的方法评价语音质量。主观方法就是通过人类对语音进行打分,比如MOS、CMOS和ABX Test.客观方法即是通过算法评测语音质量,在实时语音通话领域,这一问题研究较多,出现了诸如如PESQ和P.563这样的有参考和无参考的语音质量评价标准。在语音合成领域,研究的比较少,论文中常常通过展示频谱细节,计算MCD(mel cepstral distortion)等方法作为客观评价。今年也出现了MOSNet等基于深度网络的自动语音质量评估方法。
以下简单总结常用的语音质量评测方法。
主观评价:MOS[1], CMOS, ABX Test
客观评价
此外,有部分的方法,其代码已开源:
speechmetrics:该仓库包括MOSNet, SRMR, BSSEval, PESQ, STOI的开源实现和对应的源仓库地址。
ITU组织已公布自己实现的P.563: P.563 Source Code。GitHub上面的qin/p.563微小修改版使其能够在Mac上编译。
在语音合成中会用到的计算MCD:MattShannon/mcd
此外,有一本书用来具体叙述评价语音质量:Quality of Synthetic Speech: Perceptual Dimensions, Influencing Factors, and Instrumental Assessment (T-Labs Series in Telecommunication Services)[13]。
[1] P.800.1 : Mean opinion score (MOS) terminology
[3] P.863 : Perceptual objective listening quality prediction
[4] An algorithm for predicting the intelligibility of speech masked by An algorithm for predicting the intelligibility of speech masked by modulated noise maskers
[5] Latent Variable Analysis and Signal Separation: 14th International Conference, LVA/ICA 2018, Surrey, UK
[7] Kim D S. ANIQUE: An auditory model for single-ended speech quality estimation[J]. IEEE Transactions on Speech and Audio Processing, 2005, 13(5): 821-831.
[8] G. Mittag and S. M?ller, "Non-intrusive Speech Quality Assessment for Super-wideband Speech Communication Networks,"ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 7125-7129.
[9] G.107 : The E-model: a computational model for use in transmission planning
[10] AutoMOS
[11] QualityNet
[12] MOSNet
MOS评测实际是一种很宽泛的说法。由于给出评测分数的是人类,因此可以灵活的测试语音的不同方面。比如在语音合成领域,常见的有自然度MOS(MOS of naturalness),相似度MOS(MOS of similarity)。在实时通讯领域,有收听质量(Listening Quality)评价和对话质量(Conversational Quality)评价。但是人类给出的评分结果受到的干扰因素特别多,一般不同论文给出的MOS不具有非常明确的可比性,同一篇文章中的MOS才可以比较不同系统的优劣。谷歌在SSW10发表的Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs对若干种多行文本合成语音的评估方法进行了比较,在评估较长文本中的单个句子时,音频样本的呈现形式会显著影响被测人员给出的结果。比如仅提供单个句子而不提供上下文,与相同句子给出语境相比,被测人员给出的评分结果差异显著。
在实时通讯领域,国际电信联盟(ITU)将语音质量的主观评价方法做了标准化处理,代号为ITU-T P.800.1。其中收听质量的绝对等级评分(Absolute Category Rating, ACR) 是目前比较广泛采用的一种主观评价方法。在使用ACR方法对语音质量评价时,参与评测的人员对语音整体质量进行打分,分值范围为1-5分,分数越大表示语音质量最好。
| 音频级别 | MOS值 | 评价标准 |
|---|---|---|
| 优 | 4.0~5.0 | 很好,听得清楚;延迟小,交流流畅 |
| 良 | 3.5~4.0 | 稍差,听得清楚;延迟小,交流欠流畅,有点杂音 |
| 中 | 3.0~3.5 | 还可以,听不太清;有一定延迟,可以交流 |
| 差 | 1.5~3.0 | 勉强,听不太清;延迟较大,交流需要重复多遍 |
| 劣 | 0~1.5 | 极差,听不懂;延迟大,交流不通畅 |
一般MOS应为4或者更高,这可以被认为是比较好的语音质量,若MOS低于3.6,则表示大部分被测不太满意这个语音质量。
MOS测试一般要求:
足够多样化的样本(即试听者和句子数量)以确保结果在统计上的显著;
控制每个试听者的实验环境和设备保持一致;
每个试听者遵循同样的评估标准。
除了绝对等级评分,其它常用的语音质量主观评价有失真等级评分(Degradation Category Rating, DCR)和相对等级评分(Comparative Category Rating, CCR),这两种方式不仅需要提供失真语音信号还需要原始语音信号,通过比较失真信号和原始信号获得评价结果(类似于ABX Test),比较适合于评估背景噪音对语音质量的影响,或者不同算法之间的直接较量。附语音合成论文中计算MOS的小脚本,其不仅强调MOS值,并且要求95%的置信区间内的分数:
# -*- coding: utf-8 -*-
# @Time : 2019/4/30 13:56
# @Author : MengnanChen
# @FileName: caculate_MOS.py
# @Software: PyCharm
import math
import numpy as np
import pandas as pd
from scipy.linalg import solve
from scipy.stats import t
def calc_mos(data_path: str):
'''
计算MOS,数据格式:MxN,M个句子,N个试听人,data_path为MOS得分文件,内容都是数字,为每个试听的得分
:param data_path:
:return:
'''
data = pd.read_csv(data_path)
mu = np.mean(data.values)
var_uw = (data.std(axis=1) ** 2).mean()
var_su = (data.std(axis=0) ** 2).mean()
mos_data = np.asarray([x for x in data.values.flatten() if not math.isnan(x)])
var_swu = mos_data.std() ** 2
x = np.asarray([[0, 1, 1], [1, 0, 1], [1, 1, 1]])
y = np.asarray([var_uw, var_su, var_swu])
[var_s, var_w, var_u] = solve(x, y)
M = min(data.count(axis=0))
N = min(data.count(axis=1))
var_mu = var_s / M + var_w / N + var_u / (M * N)
df = min(M, N) - 1 # 可以不减1
t_interval = t.ppf(0.975, df, loc=0, scale=1) # t分布的97.5%置信区间临界值
interval = t_interval * np.sqrt(var_mu)
print('{} 的MOS95%的置信区间为:{} +—{} '.format(data_path, round(float(mu), 3), round(interval, 3)))
if __name__ == '__main__':
data_path = ''
calc_mos(data_path)PESQ在国际电信联盟的标注化代号为ITU-T P.862。总的想法是:
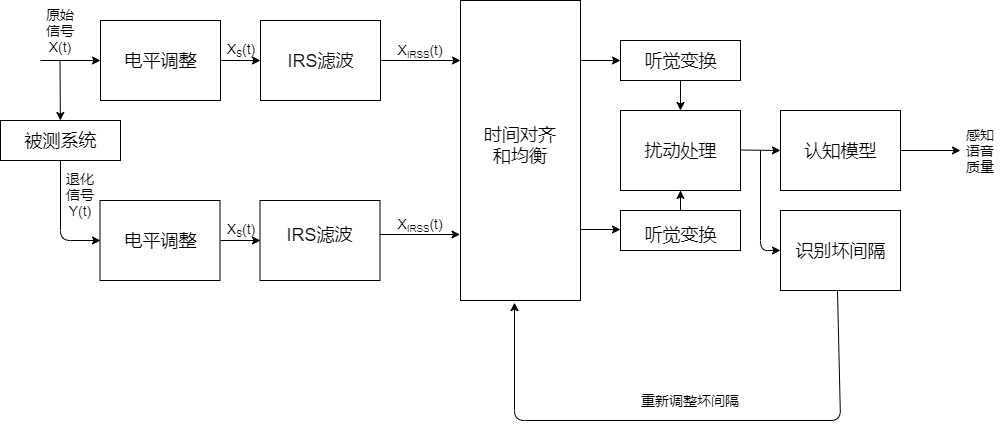
电平调整
由于各个系统的增益不同,因此需要将原信号和被测信号二者调整到统一、恒定的响度。
令\(X(t)\)是原始信号的时域表示,而\(Y(t)\)是\(X(t)\)通过被测系统后的输出信号,两者首先进行电平调整,将其统一到76 dB SPL(Sound Pressure Level)的能量水平。电平调整的流程:
IRS滤波
听觉测试需要使用IRS(Intermeiate Reference System, 中间参考系统)滤波来对参考语音信号和退化信号进行滤波,这种滤波主要是模拟典型的电话手柄听筒的频率响应特性。仿IRS滤波的实现过程为:
通过IRS滤波系统后得到\(X_{IRSS}(t)\)和\(Y_{IRSS}(t)\).
听觉变换时利用快速傅里叶变换逐帧进行频谱计算,然后再映射到感觉频域和响度,计算PESQ得分需要的参数也是逐帧计算得到的。PESQ算法的时间对齐是对在原始输入信号和退化输出语音之间的一系列延时进行计算,每一个时间间隔内的延时与前一个具有明显不同的时延值。在每一个时间间隔内,计算相应的起点和终点之间的时延,时间校准的原理就是,假设在同一个时间间隔内,原始语音和退化语音在相应的间隔内应该具有确定的时延值。PESQ算法采用了一种新的时间对齐算法,这种算法是基于包络的延迟估计方法。
感知模型在PESQ算法中用来计算PESQ得分,即原始信号和退化信号之间的差异。它是一个心理模型,能够对客观语音质量评估提供一个主观MOS的预测值。PESQ可以映射到MOS刻度范围,计算一般分为:听觉变换,计算干扰密度,计算不对称因子,扰动聚合,坏间隔重对齐,最终计算获得PESQ得分。对于正规的主观测试,得分在1.0~4.5之间。在退化严重时,得分可能会低于1.0,但这种情况很少见。
语音质量客观评价方法的性能优劣,一般用语音质量的客观MOS值和主观MOS值之间的相关程度和绝对误差作为评价的性能指标。两者的相关程度可以采用Pearson系数加以描述:
\[ \rho=\frac{\sum_{i=1}^N(MOS_o(i)-\overline{MOS_o})(MOS_s(i)-\overline{MOS_s})}{\sqrt{\sum_{i=1}^N(MOS_o(i)-\overline{MOS_o})^2\sum_{i=1}^N(MOS_s(i)-\overline{MOS_s})^2}} \]
其中,\(N\)为样本数,\(MOS_s(i)\)是第\(i\)个样本人类评判的MOS分值,\(MOS_o(i)\)是第\(i\)个样本用客观评估方法预测出的客观MOS值。\(\overline{MOS_s}\)和\(\overline{MOS_o}\)为两者的算术平均值。相关性系数描述了主客观评价的线性相关程度,相关系数越接近+1,客观评测算法越准确。绝对误差为:
\[
e_n=|MOS_o(i)-MOS_s(i)|
\]
其中,\(MOS_s(i)\)是第\(i\)个样本人类评判的MOS值,\(MOS_o(i)\)是第\(i\)个样本用客观评估方法预测出的客观MOS值。
P.563和PESQ最大的区别就是,P.563只需要经过音频引擎传输后的输出信号,不需要原始信号,直接可以输出该信号的流畅度。因此,P.563的可用性更高,但是其准确性要比PESQ低。
P.563算法主要由三个部分组成:
P.563将语音进行预处理后,首先计算出若干个最重要的特征参数,根据这些特征参数判断语音的失真类型,失真类型直接决定了感知映射模型的系数和所使用的特征。利用感知映射模型(其实就是线性方程)计算得到最终的评价结果。
类似的,语音信号首先进行电平校准和滤波。P.563假设所有语音信号的声压级都是76dB SPL,并将输入语音信号的电平值校准到-26dBov。P.563算法的所使用的滤波器分为两类,第一类滤波器的频率响应特性类似于上述的中间参考系统(IRS),第二类滤波器采用一个四阶巴特沃斯高通滤波器,其截止频率为100Hz且高频响应曲线较为平缓,通过这类滤波器的语音信号可用于基音同步提取、声道模型分析及信号电平和噪声电平的计算。信号预处理的最后一部分是语音活动检测(Voice Activity Detection, VAD),它以帧长4ms的信号功率为阈值,区分语音和噪声。高于该阈值的为语音,否则为噪声。该阈值时动态调整的,计算公式如下:
\[ threshold=\overline{x_{noise}}-x\times \sqrt{\sum_{n=1}^N\frac{(x_{noise}(n)-\overline{x_{noise}})^2}{N}} \]
其中,
\[
\overline{x_{noise}}=\sum_{n=1}^N\frac{x_{noise}(n)}{N}
\]
表示第\(n\)帧噪声信号的功率,N为噪声帧的帧数。
阈值的初始值为所有帧长为4ms信号的平均功率。为了提高VAD的精度,对VAD的结果进行后处理:如果某一段话大于阈值但是长度小于等于12ms(3帧),则将信号判定为噪声;如果两段已经被判定为语音,但是它们的间隔小于200ms,则将这两段语音合并为一整段语音。
P.563算法在特征提取过程中利用人类的发声和听觉感知原理,不需要考虑通讯网络相关的信息。P.563算法利用三个相互独立的参数分析模块对预处理后的语音信号提取特征:
P.563算法共提取43个不同的特征参数,其中8个被称作关键参数(Key Parameters)用于判断语音的失真类型。
优先级最高的失真类型是背景噪音,它根据信号的信噪比(SNR)决定,背景噪音会严重影响语音质量,大部分含有背景噪音的语音MOS值一般在1~3范围内。语音信号的间断失真是指语音信号有静音或中断,即信号的电平值发生突变。乘性噪声失真是指语音信号中与信号包络有关的噪声,该类失真仅出现在活动语音部分。语音的机械声与语音的音调密切相关。优先级最低的失真类型是语音整体的不自然度,由于语音编解码器的输出质量和性别有关,P.563基于基音频率将该失真类型分为男声和女声两种情况。如下图:
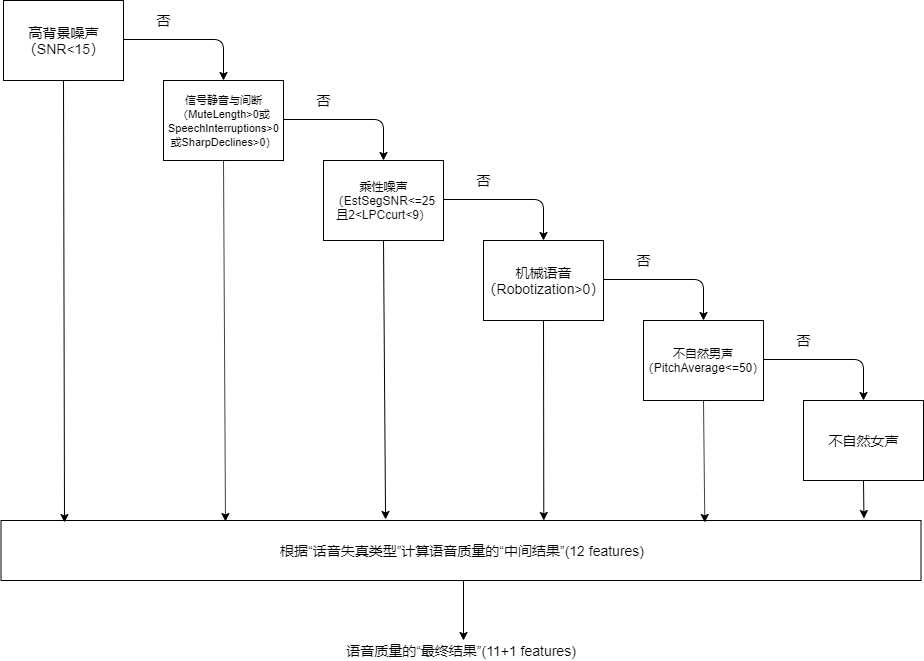
在P.563中映射模型就是一个线性模型。P.563算法根据上述求出的失真类型对线性方程的系数设置了不同的值。每一种失真类型包括12个不同的语音特征,P.563首先根据待测语音的失真类型对这12个语音特征线性组合得到评价结果的中间值,再将中间值结合另外的11个特征参数得到最终的结果。
E-Model和P.563一样,不需要原始语音就可以给出当前的语音质量。但是E-Model连退化语音都不需要,只是根据当前的传输网络,比如丢包率、延迟等给出当前的语音评估结果。
原始的E-Model(ITU-T G.107标准)定义十分繁杂,很难实现,因此出现了一批简化的E-Model用于实际落地,如Monitoring VoIP call quality using improved simplified E-model。
通过ITU-T G.107定义的E-Model,组合所有对语音质量有影响的因子计算出单一的指标R值,它可以直接映射为MOS值,因此E-Model已经成为工业和学术界评测语音质量的标准工具之一。
简化版E-Model
主要考虑的是编解码器的质量和网络情况。
\[ R=R_0-I_{codec}-I_{packet\_loss}-I_{delay} \]
其中,\(R_0\)为基本信噪比,\(I_{delay}\)为端到端延迟,\(I_{delay}\)为编解码因素,\(I_{packet\_loss}\)为窗口期内的丢包率。
Chunlei Jiang and Peng Huang, “Research of Monitoring VoIP Voice QoS”, International Conference on Internet Computing and Information Services, 2011
改进简化版的E-Model
\[ R=R_y-I_d+A \]
其中,\(R_y\)为校正函数(由PESQ引入);\(I_d\)是指定时间内的平均时延参数;\(A\)是通信系统的预期优势因素。
PESQ分数添加的校正二阶函数:\[ R_y=aR_x^2+bR_x+c \]
其中,\(R_x\)为简化版E-Model的一部分:
\[ R_x=R_0-I_e-I_{p.l}\tag{1} \]
\(a、b、c\)依赖于编码格式(如G.711中,\(a=0.18;b=-27.09;c=1126.62\),详见Monitoring VoIP call quality using improved simplified E-model-TABEL I)。
在公式1中,\(R_0\)为基本信噪比,噪音源如环境或房间噪声,该参数难以计算,在ITU-T G.113提供了\(R_0\)的基本值,现实生活中最优信噪比为94.2,但是由于音频信号转换为网络报文前后会有信息损失,因此\(R_0\)设置为93.2;\(I_e\)为编解码因素,它表示编解码对语音信号的损伤,G.113给出了一些常量值,如G.729A的\(I_e\)值为11,详见Monitoring VoIP call quality using improved simplified E-model-TABLE II;\(I_{p.l}\)为特定时间内的丢包率。
A其实是修正系数,与通信终端使用的网络类型有关,如移动网络A为5。详见Monitoring VoIP call quality using improved simplified E-model-TABLE III
E-Model计算获得的R值分值范围为0~100,其可以更为细粒度的刻画语音质量,当然也可以直接和主观分数MOS单射:
\[ MOS= \left\{\begin{matrix} 1\quad R<0 & \\ 1+0.035R+7\times 10^{-6}R(R-60)(100-R)\quad 0\leq R\leq 100 & \\ 4.5\quad R>100 & \end{matrix}\right. \]
Assem H , Malone D , Dunne J , et al. Monitoring VoIP call quality using improved simplified E-model[C] Computing, Networking and Communications (ICNC), 2013 International Conference on. IEEE, 2013.
由于深度学习的火热,也有部分人利用深度网络评估语音质量。这类方法都比较简单,由于使用的深度网络可以自动进行特征提取,因此这类方法直接将梅尔频谱系数或者MFCC直接送入模型即可。以NISQA为例。
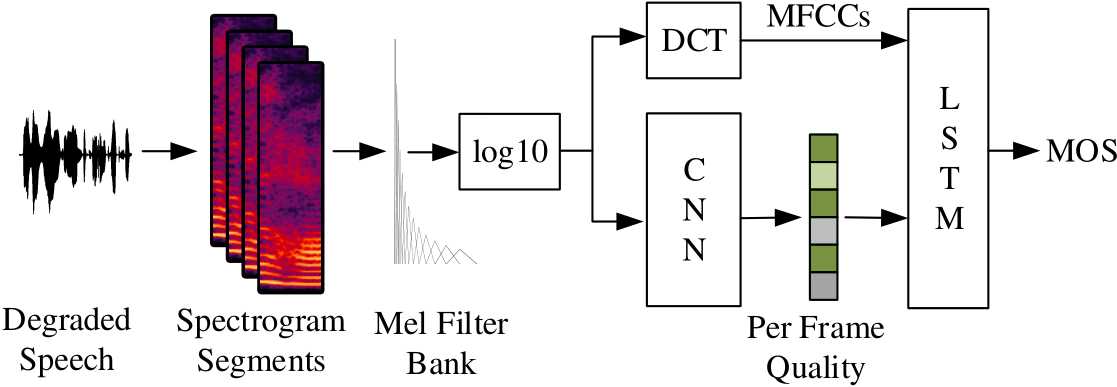
如上图,整个网络结构十分简单,对数梅尔系数分别送入CNN和计算MFCC,CNN实际输出了帧级别的语音质量。为了使整个模型能够对语音的整体质量进行评估,CNN输出的结果和MFCC连接起来送入LSTM,以得到最终的MOS分。
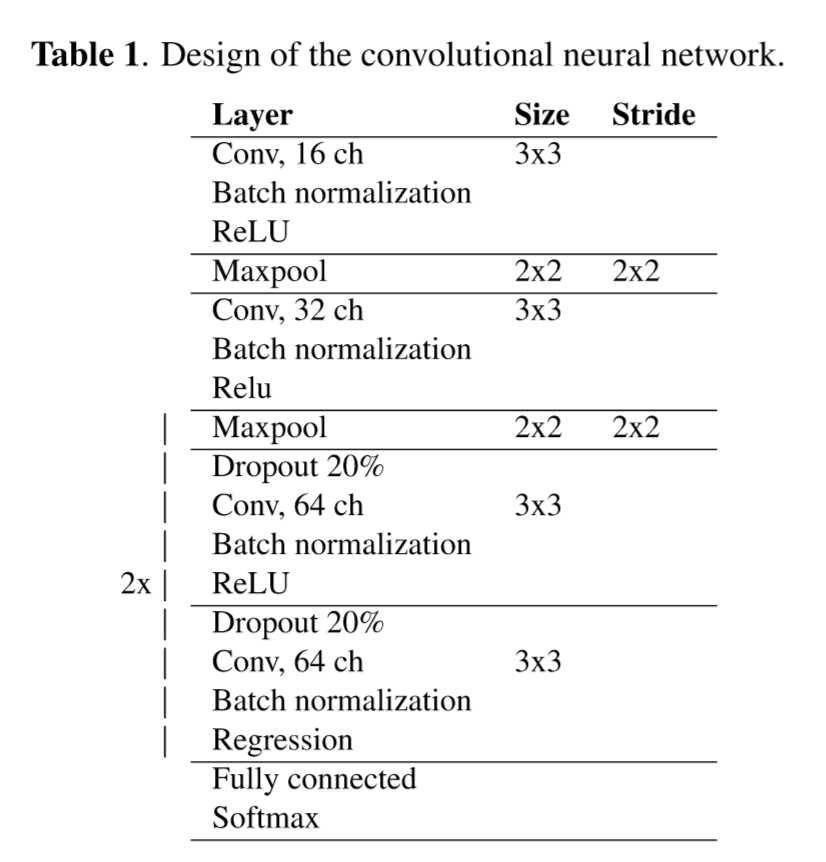
其中,CNN的设计细节:
语音质量评估对给予了语音一个定量指标,对语音质量的评价(Audio Quality Assessment)其实是一个多年以来得到了深入研究的问题。大致可以分为需要标准信号的无参考(Non-intrusive)和有参考(instrusive)方法。无参考语音质量评估在实时通讯领域出现了许多传统和深度学习方法,但是在语音合成领域,成果其实是寥寥无几的。有利用P.563做合成语音质量评估的尝试:
Kraljevski I, Chungurski S, Stojanovic I, et al. Synthesized speech quality evaluation using itu-t p. 563[J]. 2010.
标签:qos 规则 国际 mac head 计算 mos 高通 大致
原文地址:https://www.cnblogs.com/mengnan/p/12046332.html