标签:replace 左右 info 静态 出栈 子串 dash 执行 n+1
第一章
数据元素:是数据的基本单位
数据项:是最小单位,数据元素由数据项组成
数据对象:性质相同的数据元素的集合
数据结构:相互之间具有一种或多种特定的关系的数据元素的集合
数据元素有三种结构:集合、线性结构、非线性结构
(D,S):D是数据元素的有限集,S是D上关系的有限集
“关系”描述的是数据元素之间的逻辑关系,因此又叫逻辑结构
数据结构在计算机中的表示叫做存储结构
元素和结点是数据元素在计算机中 的映像
数据结构的存储方式:顺序存储结构和链式存储结构。顺序通过借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系;链式通过指针来表示数据元素之间的逻辑关系
数据类型:是一个值的集合和定义在该值集上的一组操作的总称。按值是否可分可将数据类型分为两类:原子类型和结构类型
抽象数据类型(ADT)是一个数学模型以及定义在该模型上的一组操作。“抽象”在于数据类型的数学抽象特性。(D,S,P):D是数据对象,S是D上的关系集,P是对D的基本操作集
基本操作有两种参数:1.赋值参数只为操作提供输入值,2.引用参数以&打头,除了可以提供输入值以为还能返回操作结果
异常结束语句:exit(异常代码)
算法是为了解决某个特定问题而规定的一个有限长的操作序列,是指令的有限序列:有5个重要特性——又穷性、确定性、可行性、输入、输出
算法的设计应该考虑:正确性、可读性、健壮性、效率与低存储量需求
同一个算法,实现它的语言越高级,执行效率越低
一个算法是由控制结构(顺序、分支、循环)和原操作(固有数据类型的操作)
我们应该尽可能选用多项式阶的算法,而不希望用指数阶的算法
算法的时间复杂度取决于:问题的规模和待处理的数据初态
第二章
线性表的链式存储:带头结点的结构中,头结点的作用:1.使得对空表和非空表的操作一致;2.插入和删除首元素的时候不必做特殊处理
静态链表:数组下标表示元素的地址。定义的时候是定义一个数据结构数组,数据结构包括存储的数据类型和表示下标的Int型变量名
循环链表:表中最后一个节点的指针域指向头结点,因此可从表中任意结点出发找到表中其他结点
双向链表:有prior和next两个指针域
第三章
栈:表尾叫做栈顶,表头叫做栈底。只能从栈顶进行插入和删除操作。
顺序栈:
typedef struct{
SElemType *base;
SElmType *top;
int stacksize;
}SqStack;
栈空的时候是top=base;栈不存在是base=NULL;
非空栈的栈顶指针始终在栈顶元素的下一个元素的位置。
*S.top++=e;//先在该位置放上e,然后指针上移
e=*--S.top;//先下移找到栈顶元素然后取值
链式栈:
队列:
链队列:
队列空的条件是:链的头指针和尾指针都指向头结点。
typedef struct QNode{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct{
QueuePtr front;
QueuePtr rear;
}LinkQueue;
Q.front->next是队头,Q.rear是队尾.一开始是Q.front=Q.rear=(...)malloc(...);后面的时候若是进队则先是Q.rear->next=e,然后Q.rear=e;而若是出栈则p=Q.front->next,Q.front->next=p->next,Q.front本身是不能动的!它是该栈的地址
顺序循环队列:对尾处的元素是一开始没有的,赋值之后再将其后移一位;但队头元素一开始就是有的,取值之后再后移
typedef struct{
QElemType *base;
int front;
int rear; //front和rear都是数字,代表着的是数组下标!
}SqQueue;
Status InitQueue(SqQueue &Q){
Q.base=(....)malloc(......);
Q.friont=Q.rear=0;
................
}
插入元素e:if((Q.rear+1)%MAXQSIZE==Q.front)return ERROR;//队列满了!!!队空的条件是:Q.front=Q.rear
Q.base[Q.rear]=e;
Q.rear=(Q.rear+1)%MAXSIZE;//因为是循环队列
删除队头元素:就是要使得Q.front=(Q.front+1)%MAXSIZE;
第四章:串
串是由多个或多个字符组成的有限序列
串的逻辑结构和线性表极为相似,区别仅在于串的数据对象约束为字符集。
基本操作:
Concat(&T,S1,S2)返回由S1,S2链接成的新串
SubString(&Sub,S,pos,len)用 Sub 返回串 S 的第 pos 个字符起 长度为 len 的子串
StrLength(S)求S的长度
Replace(&S,T,V)用V替换主串S中出现的所有与(模式串)T相等的不重叠的子串
Index(S,T,pos)返回T在S中第pos个字符之后第一次出现的位置
StrInsert(&S,pos,T)在串的第pos个字符之前插入串T
StrDelete(&S,pos,len)从串中删除第pos个字符起长度为len的字串
StrCompare(S,T)比较两个字符串的大小(是按照字符串的比较方法,不是看长度比的!)
StrAssign(&T,chars)生成一个其值为chars的串T
空格串不是空串,用符号Ø来表示空串。
串的定长存储 表示:规定好串的长度,超过部分会被截断。typedef unsigned char Sstring [MAXSTRLEN + 1];Sstring[0]里存储串的长度
串的堆分配存储 表示:地址连续,但是动态分配存储空间,因此不会有溢出的情况
串的块链式存储结构 表示:用链表表示串,每个结点里面可以放置多个字符,即块的大小。然后除了头指针还能设置一个尾指针,以及定义串的链表长
第五章 数组
二维数组A(b1, b2)表示该数组的行数是b1,列数是b2


压缩存储:为多个值相同的元只分配一个存储空间,为零单元不分配空间
对称矩阵:
存储单元从n^2缩小到n(n+1)/2.

这式子里面的-1是因为S的下标从0开始,因此求到的值需要减去1
如果遇到了i<j,则直接访问aji,即要根据aji确定k然后找到S[k]。
三角矩阵:
跟对称矩阵类似,只是对角线上方的元素全部为常数c或0,因此所需存储空间为n(n+1)/2+1,多出来的那个地方,就是S[n(n+1)/2]的值为常数c或0。
对角矩阵:
在这种矩阵中,除了对角线上和直接在对角线上、下方若干条对角线上的元素外,所有其他的元素皆为0。
稀疏矩阵:有很多个0的矩阵,可用三元组表示非零元素,如(1,2,18)表示的是1行2列的非零元18
系数矩阵存储方式:三元组顺序表、行逻辑链接的顺序表、十字链表
三元组顺序表:将三元组按行优先,同一行列号从小到大的规律排成一个线性表。采用顺序存储方法存储该表
转置算法:将M的行和列对换然后用T表示(M,T都是三元组顺序存储表)
for (col=1;col <=M.nu; ++col) num[col]=0;//先初始都是0
for (t=1;t<=M.tu; ++t) ++num[M.data[t].j];//求M中每一列含非零元个数
cpot[1] = 1;//求第col列中第一个非零元在b.data中的序号
for (col=2; col<=M.nu; ++col) cpot[col] = cpot[col-1] + num[col-1];//求col列第一非零元位置

注意红色部分:cpot[col]始终存的是col列下一个要存的元素在T中的位置!!
这个算法的时间复杂度为: O(M.nu+M.tu)
行逻辑链接的顺序表:
将指示行信息的辅助数组cpot固定在 稀疏矩阵的存储结构中

两个稀疏矩阵相乘:
十字链表:
每行和每列的非零元链成循环链表,每个非零元用一个含五个域的结点表示:

广义表:是n(n≥0)个数据元素a1, a2, …, an的有序序列,记做LS(a1,a2,a3......an)
当广义表非空的时候,将a1称为表头,(a2,a3......an)组成的表称为LS的表尾
广义表的长度定义为最外层所包含的元素个数(所以最好的方法就是根据最外层的逗号来数)
广义表的深度定义为所含括弧的重数; 注意:“原子”的深度为 0 , “空表”的深度为 1
基本操作:取表头操作(GetHead)和取表尾操作(GetTail)
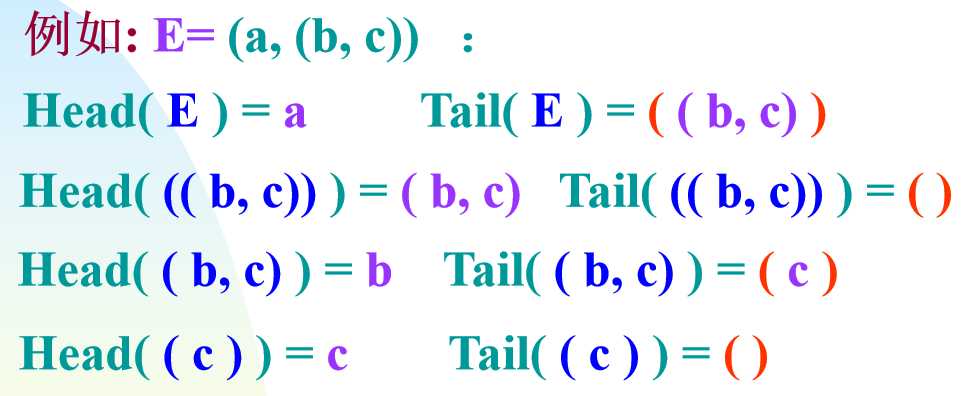
小窍门:写表尾的时候就先放个()然后把第一个逗号之后的东西照搬进去就好
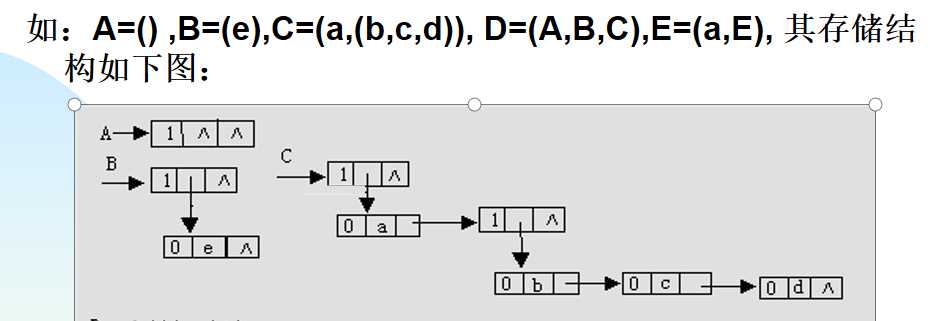
广义表的链式存储结构可以分为:头尾表示法和孩子兄弟表示法
头尾表示法:表结点和原子节点分别表示列表和原子
表结点中:tag是标志域,hp是指向表头的,tp是指向表尾的
原子结点中:tag是标志域,atom是值域
tag=1是表结点,=0是原子结点

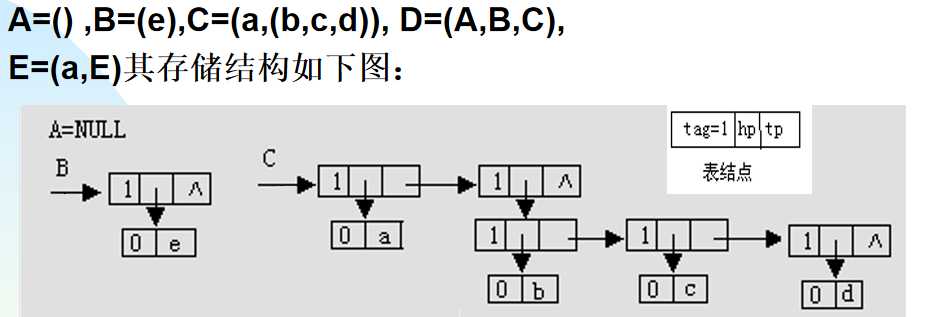
孩子兄弟表示法:
其中原子的tp是指向跟它同级的第一个元素,可能是表节点也可能是原子结点

第六章:树和二叉树
专业术语:
结点的度数:表示它有几个子树
树的度:表示结点度数的最大值
结点的层数:默认将根的层次设为1
树的深度:树种结点最大的层次
森林:对树的每个结点而言,其子树的集合就是森林
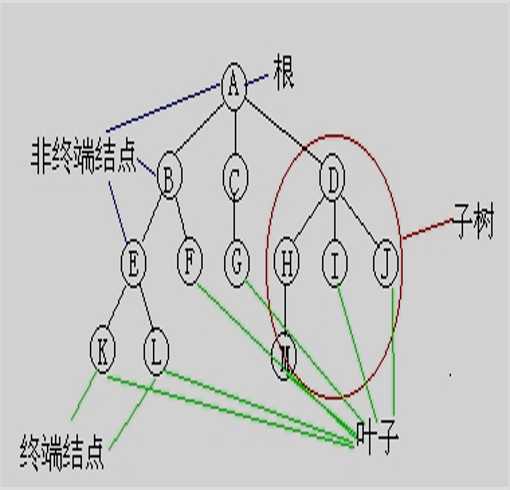
二叉树:二叉树每个结点至多有两棵子树,且有左右之分,次序不能颠倒。
满二叉树:每层结点都满了,深度为K的话那么结点总数为(2^K-1)。
完全二叉树:深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应,称为完全二叉树,其特点是: 叶子结点只可能在层次最大的两层上出现,即最下层和次最下层; 对任一结点,若其右分支下的子孙的最大层次为 L,则起左分支下的子孙的最大层次必为 L 或 L+1 ,即最下层的 叶子结点集中在树的左部。
二叉树的性质:
在二叉数的第i层上至多 有2i-1个结点(i>=1);
深度为k的二叉树至多有2k-1个结点(k>=1);
对任何一棵二叉树T,如果其终端结点数为n0,度为2的 结点数为n2,则n0=n2+1(树中,终端结点出度为0,树的总入度为总结点数-1,非终端结点出度为1或2)
具有n个结点的完全二叉树的深度为|_log2n_| +1
个
二叉树的表示方法:
链式存储表示 :
对结点有二个指针域的存储方式有以下表示方法:
typedef struct BiTNode{
TElemType data;
struct BitNode *lchild, *rchild; //左右孩子指针
} BiTNode,*BiTree;
二叉树的遍历:
可以用栈来实现非递归遍历算法。
以中序为例:

标签:replace 左右 info 静态 出栈 子串 dash 执行 n+1
原文地址:https://www.cnblogs.com/xxikwonxjlxi/p/12051598.html