标签:保存 瓶颈 cto 优点 equal another 序列 替代 reserve
对spark程序来说,可能会产生的瓶颈包括:cpu,网络带宽,内存
在任何分布式应用中数据序列化都非常重要,数据序列化带来的作用是什么?第一减少内存占用,第二减小网络传输带宽消耗。spark提供了两种序列化方式:
默认情况下,spark序列化对象使用java的ObjectOutputStream框架,只需要我们在创建类的时候实现 java.io.Serializable
你也可以通过继承java.io.Externalizable来实现更好的性能,java序列化比较灵活但是相对较慢,性能不够好。
第二种方式就是目前应用比较多的Kryo序列化,
Kryo比Java序列化快很多,并且序列化之后的结果也更小(基本上是java序列的10倍左右),但是不支持所有的序列化类型,需要在程序中对要使用的类提前注册,以获得最佳性能。
使用kryo序列化只需要在spark程序中设置sparkConf,conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"),这样一来,shuffle时候,在各个节点进行数据传输时就会生效。同理,将RDD序列化到磁盘时候也一样。spark之所以没有把kryo序列化作为默认的序列化方式主要原因就是需要自定义的注册。但是还是墙裂推荐使用kryo序列化的方式,尤其那些网络密集型的应用。从spark2.0.0开始,当shuffle那些基本数据类型,数组或者string类型的RDD时候,已经默认使用kryo序列化了。
对于自定义的类使用kryo序列化:
val conf = new SparkConf().setMaster(...).setAppName(...) conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) val sc = new SparkContext(conf)
java版
conf.registerKryoClasses(new Class[]{Class1.class,Class2.class});
另外,如果你要序列化的对象比较大的话,可能还需要增加spark.kryoserializer.buffer参数值。
如果没有注册自定义类,Kryo也可以使用,但是在序列化时候必须将完整的类名保存在每个对象中,这是一个比较大的开销。
序列化也同样可以应用在缓存数据时候(persist级别),比如MEMORY_ONLY_SER 但是如果内存足够,也可以不使用序列化存储,因为序列化虽然在内存占用上减少了,但是在访问该数据时候,需要进行反序列化。
谈内存优化之前先了解一下java对象在内存中占用的情况以及spark的内存管理模型
在保存java对象到内存中时候,一般会比对象中原始的字段多占用3-5倍的空间,原因如下:
以下内容是基于spark2.3版本
默认情况下,spark只使用堆内内存,如下:

executor 端的堆内内存大致可以分为以下四大块:
● Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
● Storage 内存:主要用于存储spark的cache数据,例如RDD的缓存、unroll数据;
● 用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。
● 预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。
如下图:
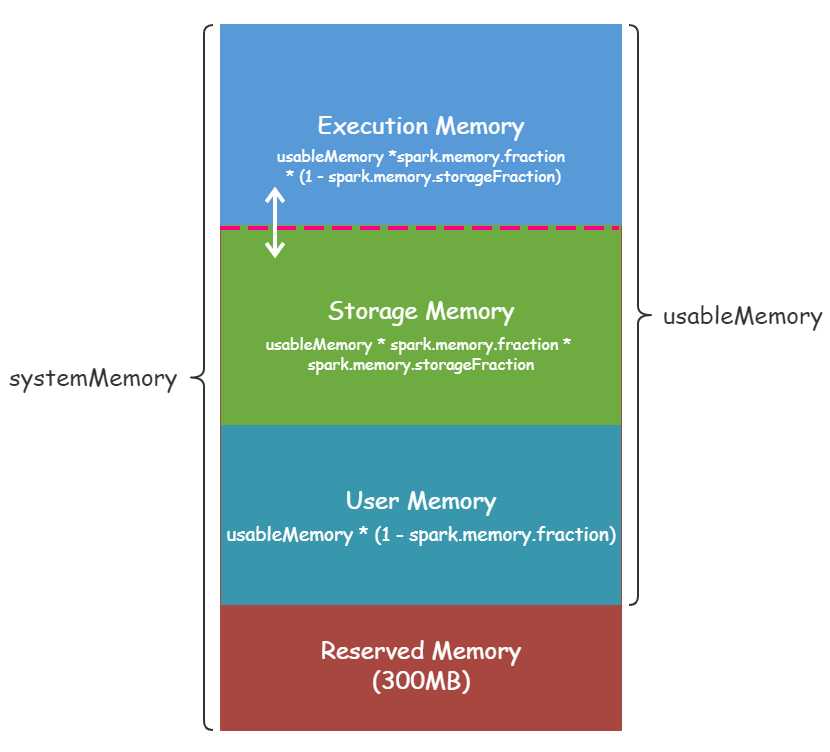
systemMemry也就是通过--executor-memory 配置的,Reserverd Memory是写死的300M(可以参考官网对该处的描述),usable Memory等于systemMemry减去Reserverd Memory。

usable Memory乘于spark.memory.fraction比例才等于execution和storage可用的内存,该版本比例为0.6。
举个例子:
启动一个任务,executor内存分配为8G
[etluser@master01 kong]$ spark2-shell --master yarn --executor-memory 8g --num-executors 2
在spark web ui界面查看executor内存:
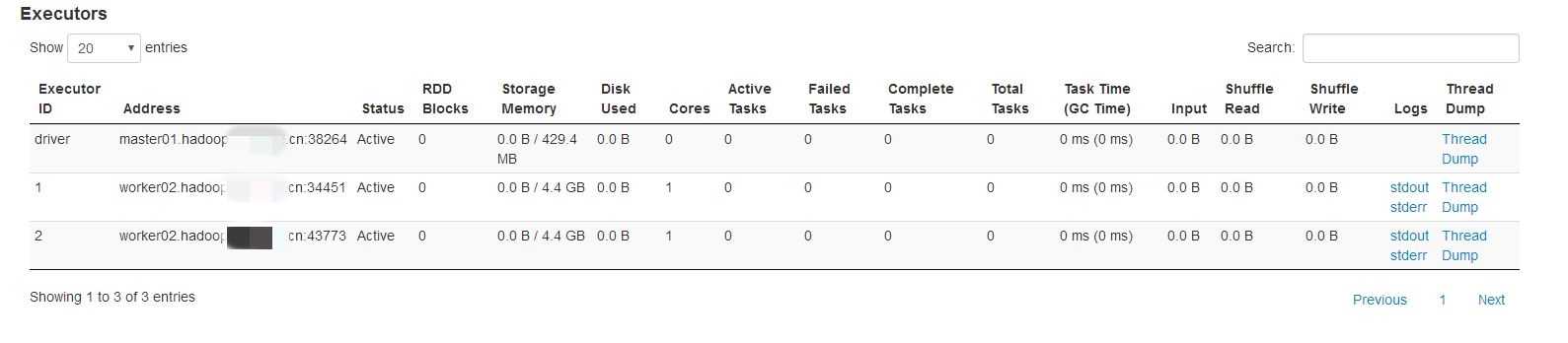
在stroage memory那一项4.4G,这个值指的是execution和storage内存之和。根据上面描述计算如下:
Memory = (8 *1024-300)*0.6 = 4735M = 4.62G,为什么比界面显示的4.4G大??
虽然我们设置的--executor-memory为 8g,但是 Spark 的 Executor 端通过 Runtime.getRuntime.maxMemory 拿到的内存其实没这么大,其值会比实际配置的executor内存的值小。
这是因为内存分配池的堆部分分为 Eden,Survivor 和 Tenured 三部分空间,而这里面一共包含了两个 Survivor 区域,而这两个 Survivor 区域在任何时候我们只能用到其中一个,
所以我们可以使用下面的公式进行描述:
ExecutorMemory = Eden + 2 * Survivor + Tenured
Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured
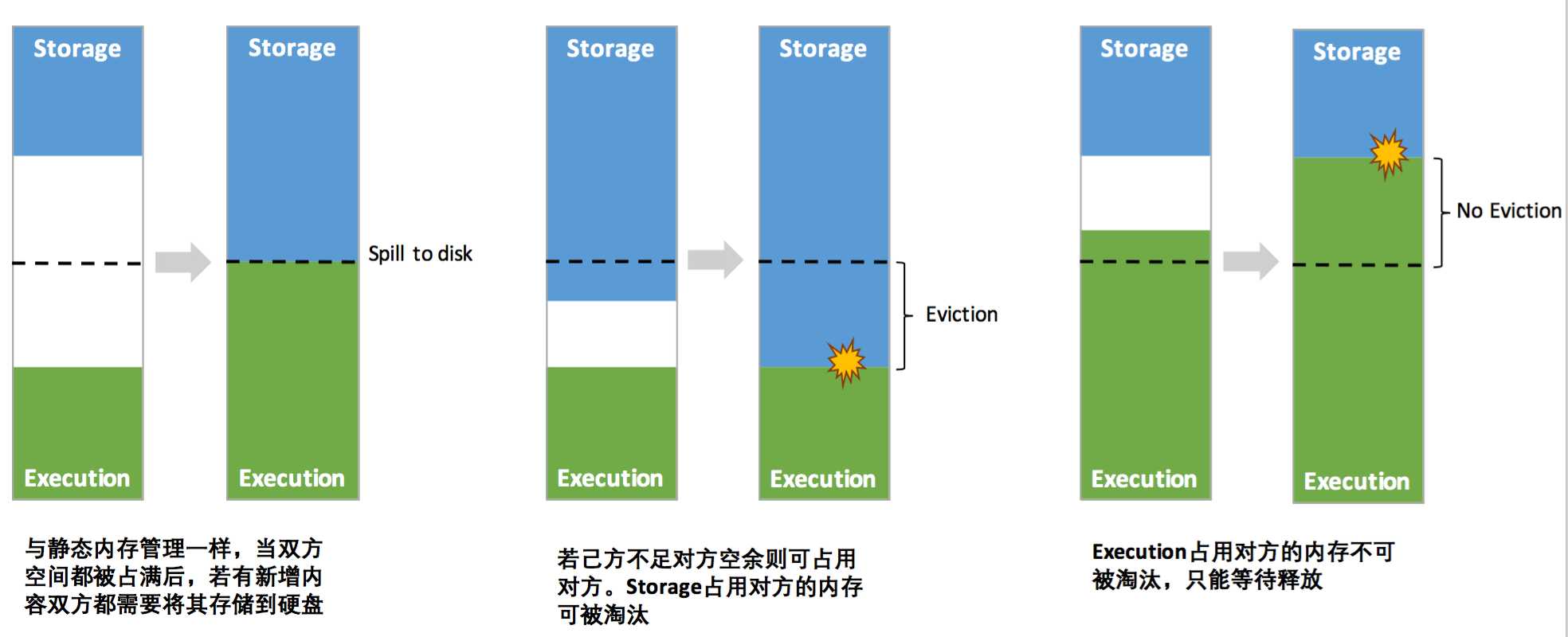
另外execution和storage之间的内存是可以互相动态调整的,(在spark1.5之前,两者的内存大小占比是定值),如下图:
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3}); broadcastVar.value(); // returns [1, 2, 3]
数据本地性对spark任务的性能有很大的影响的,如果数据和代码(task)在一块计算基本上是最快的。如果数据和代码(task)不在一块,那么必须有一项需要移动的,并且往往移动的是代码(task),因为大部分情况下它是相对较小的,移动它相对更快开销更小,
数据本地性分为几个级别:
PROCESS_LOCAL data is in the same JVM as the running code. This is the best locality possible NODE_LOCAL data is on the same node. Examples might be in HDFS on the same node, or in another executor on the same node. This is a little slower than PROCESS_LOCAL because the data has to travel between processes NO_PREF data is accessed equally quickly from anywhere and has no locality preference RACK_LOCAL data is on the same rack of servers. Data is on a different server on the same rack so needs to be sent over the network, typically through a single switch ANY data is elsewhere on the network and not in the same rack
PROCESS_LOCAL是最好的级别,也就是数据和代码是在同一JVM,但是并不是所有的task都可以达到这个级别。对于怎么对每个task都达到一个最理想的级别,spark有两种策略:
1.等,等到可以达到理想的数据本地性级别的cpu闲下来,然后自己顶上去。等待时间有个默认值。(这里也有一定的坑,比如数据不大或者执行逻辑简单,在刚达到或者还未达到该时间的时候,task就已执行完毕,这种情况下就会发现task扎堆执行,给人一种数据倾斜的错觉)
2.不管一切就是起任务,立即在非理想级别状态下执行。

标签:保存 瓶颈 cto 优点 equal another 序列 替代 reserve
原文地址:https://www.cnblogs.com/dtmobile-ksw/p/12034986.html