标签:核心 处理 结合 超出 pid 访问 code upload 服务
一、vmstat 可对操作系统的虚拟内存、进程、CPU活动进行监控

Procs(进程) r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1) b: 等待IO的进程数量。 Memory(内存) swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 free: 空闲物理内存大小。 buff: 用作缓冲的内存大小。 cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。 Swap si: 每秒从交换区写到内存的大小,由磁盘调入内存。 so: 每秒写入交换区的内存大小,由内存调入磁盘。 注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,
不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(现在的Linux版本块的大小为1kb) bi: 每秒读取的块数 bo: 每秒写入的块数 注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。 system(系统) in: 每秒中断数,包括时钟中断。 cs: 每秒上下文切换数。 注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。 CPU(以百分比表示) us: 用户进程执行时间百分比(user time),us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 sy: 内核系统进程执行时间百分比(system time),sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 wa: IO等待时间百分比,wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 id: 空闲时间百分比
st:来自于一个虚拟机偷取的CPU时间的百分比
二、统计CPU各个核心的工作情况 mpstat -P ALL
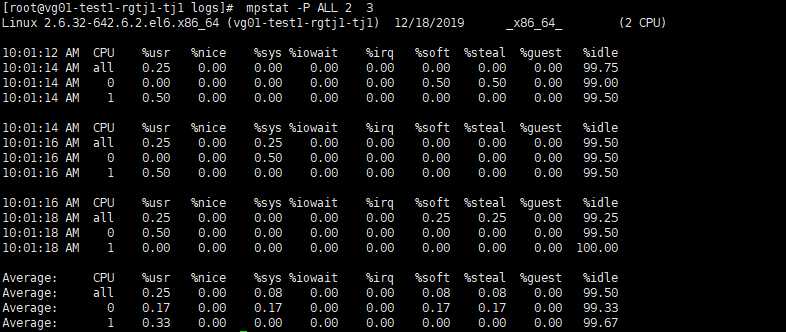
%user:表示处理用户进程所使用CPU的百分比。用户进程是用于应用程序(如JAVA进程)的非内核进程;
%nice:表示使用nice命令对进程进行降级时CPU的百分比;
%system:表示内核进程使用的CPU百分比;
%iowait:表示等待进行I/O所使用的CPU时间百分比;
%irq:表示用于处理系统中断的CPU百分比;
%soft:表示用于软件中断的CPU百分比;
%steal :显示虚拟机管理器在服务另一个虚拟处理器时虚拟CPU处在非自愿等待下花费时间的百分比
%guest :显示运行虚拟处理器时CPU花费时间的百分比
%idle:显示CPU的空闲时间;
%intr/s:显示每秒CPU接收的中断总数;
三、查看某个进程的CPU情况 pidstat -u
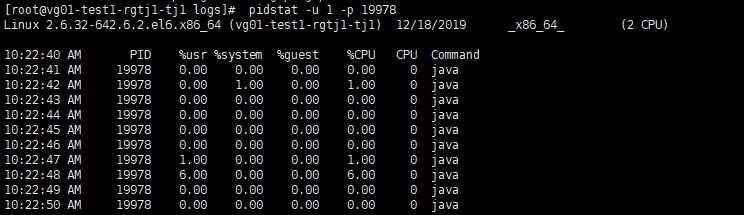
PID:进程ID
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令

标签:核心 处理 结合 超出 pid 访问 code upload 服务
原文地址:https://www.cnblogs.com/jalja/p/12058354.html