标签:初始 color hat orm function afn dead ble 资料
由课上的讲解我们知道start_kernel是内核加载的起点,也是我们进行debug的起点。start_kernel中的最后一句为arch_call_rest_init(),其内部调用了课堂ppt上所说的rest_init()。通过rest_init()新建kernel_init、kthreadd内核线程。rest_init()最后调用cpu_idle() 演变成了idle进程。下面的截图展示了和课程主页所述不同部分的代码,其它相同的代码就不在这里重复粘贴了。
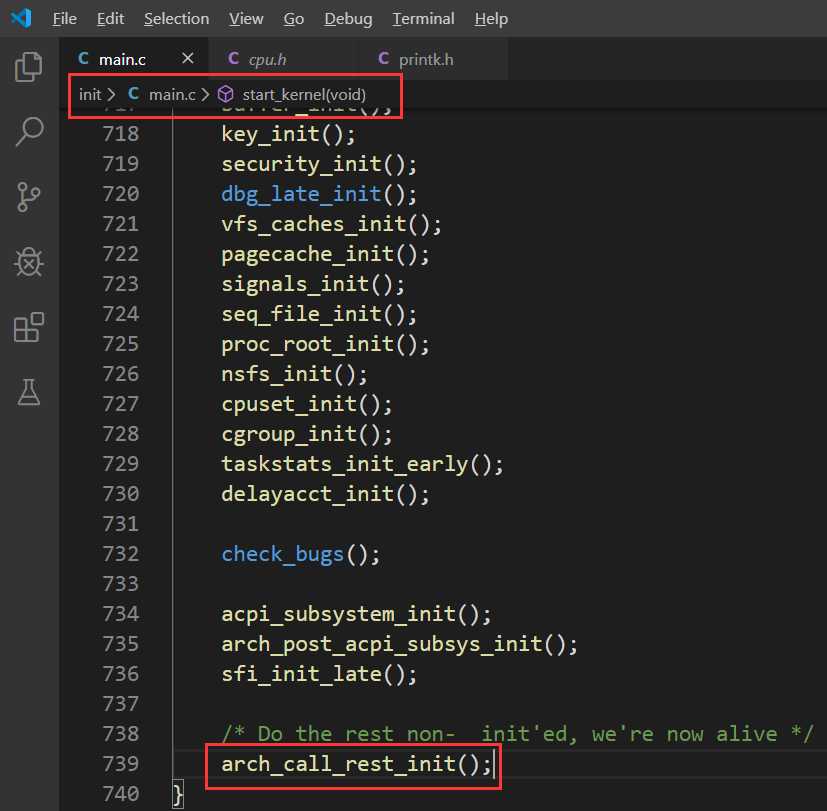
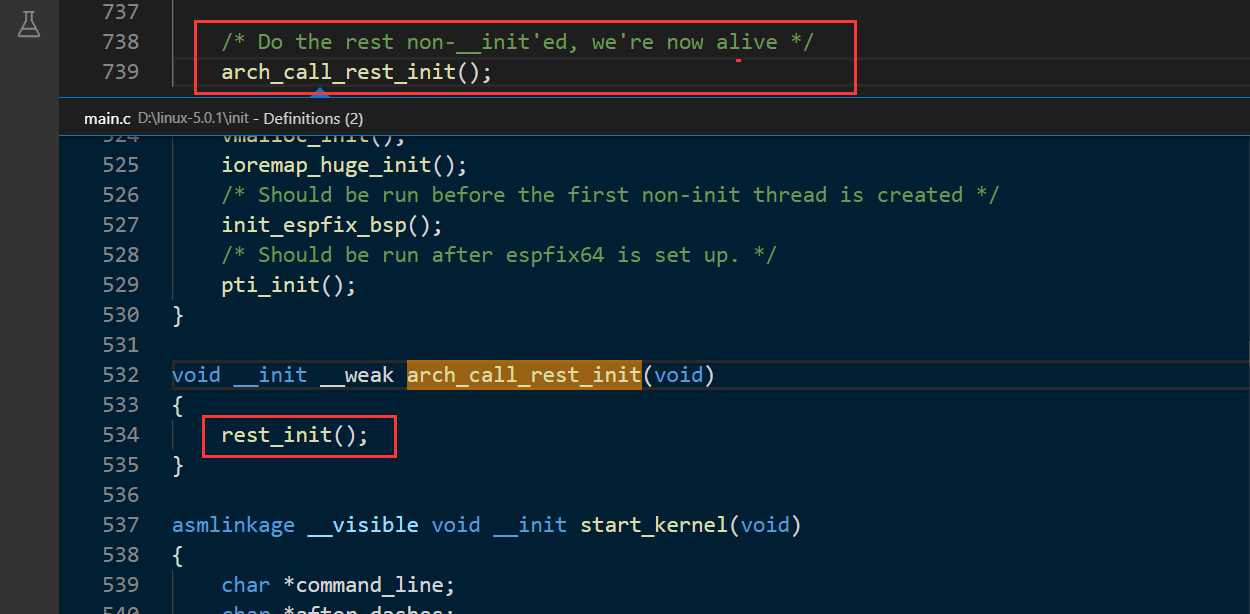
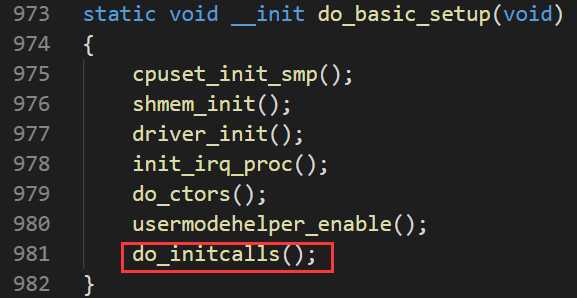
按照课程参考资料,kernel_init用来加载init用户程序,但是在加载init用户程序前通过kernel_init_freeable函数进一步做了一些初始化的工作。kernel_init_freeable函数做的一些初始化的工作与我们网络初始化有关的主要在do_basic_setup中,其中do_initcalls用一种巧妙的方式对一些子系统进行了初始化,其中包括TCP/IP网络协议栈的初始化。
do_initcalls是table驱动的,维护了一个initcalls的table,从而可以对每一个注册进来的初始化项目进行初始化,这个巧妙的机制可以理解成观察者模式,每一个协议子系统是一个观察者,将它的初始化入口注册进来,do_initcalls函数是被观察者负责统一调用每一个子系统的初始化函数指针。
以TCP/IP协议栈为例,inet_init是TCP/IP协议栈初始化的入口函数,通过fs_initcall(inet_init)将inet_init函数注册进initcalls的table。
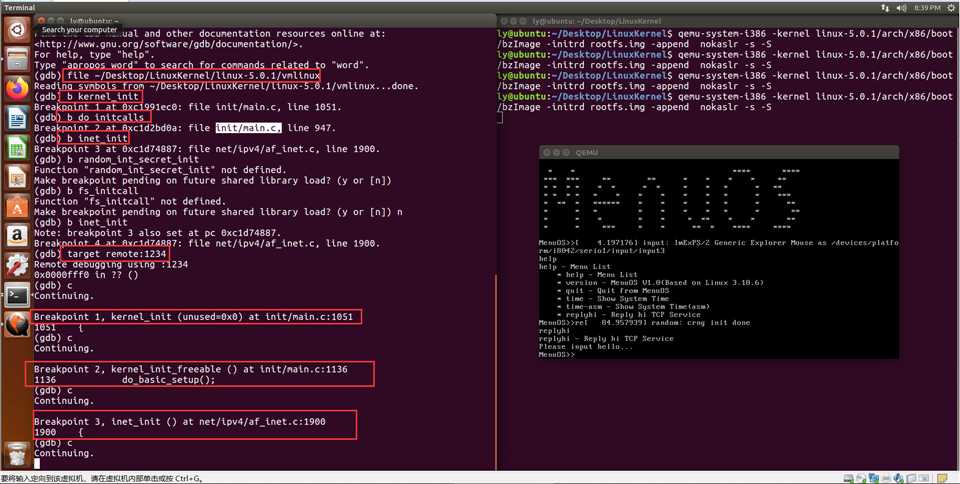
下面的我们对内核进行调试验证上述流程。我们首先将端点设在kernel_init、do_initcalls、inet_init以及do_initcalls后面的random_int_secret_init,预期这四个断点会依次触发,从而可以间接验证fs_initcall(inet_init)确实将inet_init注册进了do_initcalls并被do_initcalls调用执行了。这是课程资料的验证方法,不过5.0.1中do_inticalls()后面的random_int_secret_init删去了,我们就不验证了(无奈+摊手)。
如果你知道Linux系统中进程间通信的方式,就应该知道套接字也是其中一种。但套接字特别之处在于它不仅可以用来实现同一台主机上进程间的通信,还可以用来实现主机间的进程间的通信。通信的双方各自打开一个套接字,套接字之间通过通信链路相连。如果把两个套接字之间的‘连接’比喻成‘水管’,那么套接字就是‘水龙头’
Unix有一句格言:everything is a file,即‘万物皆文件’,套接字也不例外。那么如何把套接字和文件联系起来呢? 答案就是通过下面这张图。
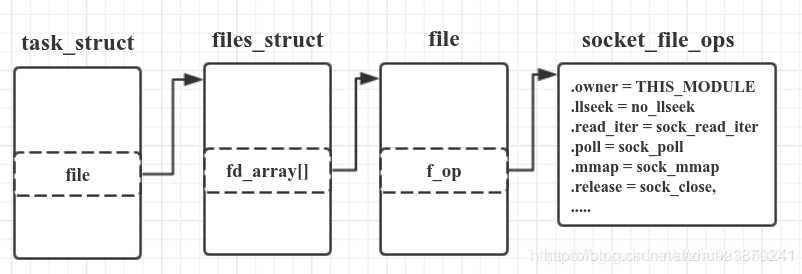
其中task_struct表示一个进程,files_struct中的fd_array[]表示该进程打开的所有描述符,对于套接字来说,与其他类型文件的区别就是最终f_op指向的是socket_file_ops。不过,可以看到,这里的socket_file_ops只有一些通用的操作,并没有send和recv。特有的操作通过 socketcall() 区分的。
struct socket { socket_state state; //socket的状态,比如CONNECTED short type;//类型,比如TCP下使用的流式套接字SOCK_STREAM unsigned long flags;//标志位,负责一些特殊的设置,比如SOCK_ASYNC_NOSPACE struct socket_wq __rcu *wq;//等待队列 struct file *file;//与socket相关的指针列表 struct sock *sk;//负责记录协议相关内容 const struct proto_ops *ops;//采用了和超级块设备操作表一样的逻辑,专门设置了一个数据结构来记录其允许的操作 };
struct sock:它是网络层的socket;对应有TCP、UDP、RAW三种,面向内核驱动;
其状态相比socket结构更精细:
struct inet_sock:它是INET域的socket表示,是对struct sock的一个扩展,提供INET域的一些属性,如TTL,组播列表,IP地址,端口等;
struct raw_socket:它是RAW协议的一个socket表示,是对struct inet_sock的扩展,它要处理与ICMP相关的内容;
sturct udp_sock:它是UDP协议的socket表示,是对struct inet_sock的扩展;
struct inet_connection_sock:它是所有面向连接的socket表示,是对struct inet_sock的扩展;
struct tcp_sock:它是TCP协议的socket表示,是对struct inet_connection_sock的扩展,主要增加滑动窗口,拥塞控制一些TCP专用属性;
struct inet_timewait_sock:它是网络层用于超时控制的socket表示;
struct tcp_timewait_sock:它是TCP协议用于超时控制的socket表示;
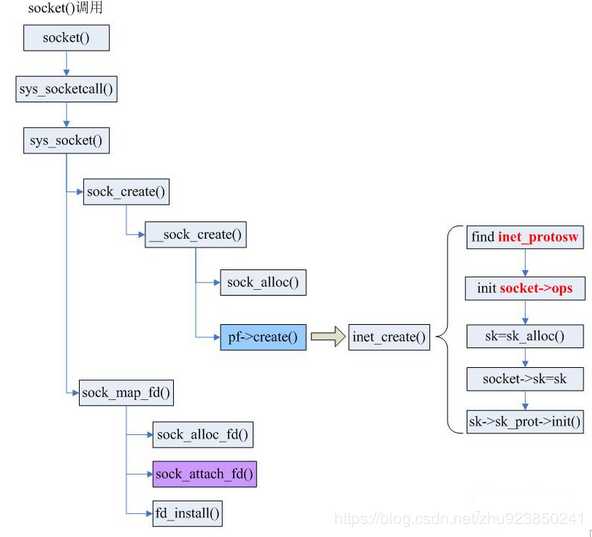
socket()本质上是一个 glibc中的函数,执行实际上是是调用sys_socketcall()系统调用。sys_socketcall()是几乎所有socket相关函数的入口,即是说,bind,connect等等函数都需要sys_socketcall()作为入口。该系统调用代码如下:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) { unsigned long a[AUDITSC_ARGS]; unsigned long a0, a1; int err; unsigned int len; if (call < 1 || call > SYS_SENDMMSG) return -EINVAL; call = array_index_nospec(call, SYS_SENDMMSG + 1); len = nargs[call]; if (len > sizeof(a)) return -EINVAL; /* copy_from_user should be SMP safe. */ if (copy_from_user(a, args, len)) return -EFAULT; err = audit_socketcall(nargs[call] / sizeof(unsigned long), a); if (err) return err; a0 = a[0]; a1 = a[1]; switch (call) { case SYS_SOCKET: err = __sys_socket(a0, a1, a[2]); break; case SYS_BIND: err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_LISTEN: err = __sys_listen(a0, a1); break; case SYS_ACCEPT: err = __sys_accept4(a0, (struct sockaddr __user *)a1, (int __user *)a[2], 0); break; ... ... default: err = -EINVAL; break; } return err; }
省略号省略掉的是各种网络编程用得到的函数,全部都在这个系统调用中,再次证明前文所说,sys_socketcall()是系统所有socket相关函数的大门。
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; /* * Check protocol is in range */ if (family < 0 || family >= NPROTO) return -EAFNOSUPPORT; if (type < 0 || type >= SOCK_MAX) return -EINVAL; /* Compatibility. This uglymoron is moved from INET layer to here to avoid deadlock in module load. (避免模块加载死锁) */ if (family == PF_INET && type == SOCK_PACKET) { pr_info_once("%s uses obsolete (PF_INET,SOCK_PACKET)\n", current->comm); family = PF_PACKET; } /*检查权限,并考虑协议集、类型、协议,以及 socket 是在内核中创建还是在用户空间中创建*/ err = security_socket_create(family, type, protocol, kern); if (err) return err; /* * Allocate the socket and allow the family to set things up. if * the protocol is 0, the family is instructed to select an appropriate * default. */ sock = sock_alloc(); if (!sock) { net_warn_ratelimited("socket: no more sockets\n"); return -ENFILE; /* Not exactly a match, but its the closest posix thing */ } sock->type = type; #ifdef CONFIG_MODULES /* Attempt to load a protocol module if the find failed. * * 12/09/1996 Marcin: But! this makes REALLY only sense, if the user * requested real, full-featured networking support upon configuration. * Otherwise module support will break! */ if (rcu_access_pointer(net_families[family]) == NULL) request_module("net-pf-%d", family); #endif rcu_read_lock(); pf = rcu_dereference(net_families[family]); err = -EAFNOSUPPORT; if (!pf) goto out_release; /* * We will call the ->create function, that possibly is in a loadable * module, so we have to bump that loadable module refcnt first. */ if (!try_module_get(pf->owner)) goto out_release; /* Now protected by module ref count */ rcu_read_unlock(); err = pf->create(net, sock, protocol, kern); if (err < 0) goto out_module_put; /* * Now to bump the refcnt of the [loadable] module that owns this * socket at sock_release time we decrement its refcnt. */ if (!try_module_get(sock->ops->owner)) goto out_module_busy; /* * Now that we‘re done with the ->create function, the [loadable] * module can have its refcnt decremented */ module_put(pf->owner); err = security_socket_post_create(sock, family, type, protocol, kern); if (err) goto out_sock_release; *res = sock; return 0; out_module_busy: err = -EAFNOSUPPORT; out_module_put: sock->ops = NULL; module_put(pf->owner); out_sock_release: sock_release(sock); return err; out_release: rcu_read_unlock(); goto out_sock_release; }
sock_alloc函数式分配并初始化一个socket和一个inode,二者是捆绑在一起的,如果成功则返回socket,如果inode创建出问题,则返回NULL。
struct socket *sock_alloc(void) { struct inode *inode; struct socket *sock; inode = new_inode_pseudo(sock_mnt->mnt_sb); if (!inode) return NULL; sock = SOCKET_I(inode);//该宏根据返回的inode获取到分配的socket_alloc指针 inode->i_ino = get_next_ino(); inode->i_mode = S_IFSOCK | S_IRWXUGO; inode->i_uid = current_fsuid();//用户ID,在后面调用bind系统调用时会进行对比 inode->i_gid = current_fsgid();//组ID inode->i_op = &sockfs_inode_ops; return sock; }
new_inode_pseudo函数是分配一个新的inode结构体,但在实际分配过程中,分配了一个socket_alloc结构体,返回d的是inode地址
struct socket_alloc { struct socket socket; struct inode vfs_inode; };
该系统调用的源代码显示如果传进去的超级快表操作是alloc_inode的话,则执行之。可以看到,传进去的参数是sock_mnt->mnt_sb,再查找该参数发现这个参数是在初始化sock_init中进行kern_mount时赋值的,恰好使得传进去的参数是alloc_inode,所以,接下来执行超级快操作表中的alloc_inode,然后调用sock_alloc_inode系统调用。
该系统调用先是ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL);进行slab分配,尔后的代码也是进行inode的操作和slab的分配,到此为止,暂时不再继续深入,只是注意到经过这一系列地分配之后,socket处于未连接状态,即socket.state = SS_UNCONNECTED。
static inline struct socket *SOCKET_I(struct inode *inode) { return &container_of(inode, struct socket_alloc, vfs_inode)->socket; } #define container_of(ptr, type, member) ({ const typeof(((type *)0)->member)*__mptr = (ptr); (type *)((char *)__mptr - offsetof(type, member)); })
首先分析传入参数,ptr是指向返回对象的指针,有点绕,但前文说过,inode和socket是绑在一起的,此处其实就是inode指向socket的意思。然后是type,在SOCKET_I中传入的事socket_alloc结构体,只包含了socket结构体和在虚拟文件系统中的节点结构体,无甚复杂。宏container_of中还包含了另外一个宏offsetof:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
由此分析container_of的内容。首先是offsetof,是假设TYPE(即struct sock_alloc)的地址在0的时候其中MEMBER的地址,即是在计算MEMBER在结构体中的偏移地址,所以这个宏取名为offsetof也不为怪了。回过头看container_of,这个宏分两部分:
第一部分typeof( ((type *)0)->member ) *__mptr = (ptr),通过typeof定义一个struct sock_alloc->vfs_inode的指针__mptr,然后赋值为ptr的值,即是说现在vfs_inode的地址就是ptr(即inode)的地址。
第二部分 (type *)( (char *)__mptr - offsetof(type,member) ),用vfs_inode的地址去减去它在结构体中的偏移地址,自然得到结构体的首地址,又因为该结构体的第一个成员是struct socket socket,所以自然返回的是socket的地址,再通过(type *)进行强制类型转换,所以SOCKET_I就得到了新的socket的指针了。
这个选项是用于linux的模块编写的,如果在模块编写时用上了CONFIG_MODULES,是会在makemenuconfig中出现该模块选项的。该处如果有CONFIG_MODULES但是却没有找到对应的下属选项则会装载一个default的模块。
if (rcu_access_pointer(net_families[family]) == NULL) request_module("net-pf-%d", family);
这两句检查对应协议族的操作表是否已经安装,如果没有安装则使用request_module进行安装。现在都是在TCP/IP协议下进行分析,所以family是AF_INET,也就是2,所以实际检查的是全局变量net_families[2]。这个全局变量是在系统初始化时由net/ipv4/af_inet.c文件进行安装,具体代码是:fs_initcall(inet_init);而fs_initcall是个宏,具体实现是:
#define fs_initcall(fn) __define_initcall(fn, 5)
即是把inet_init装载在init_call中,所以在系统启动时自然会初始化。
static int __init inet_init(void) { .............. /*把各种proto注册到全局链表中去*/ rc = proto_register(&tcp_prot, 1); if (rc) goto out; rc = proto_register(&udp_prot, 1); if (rc) goto out_unregister_tcp_proto; rc = proto_register(&raw_prot, 1); if (rc) goto out_unregister_udp_proto; rc = proto_register(&ping_prot, 1); if (rc) goto out_unregister_raw_proto; /* * Tell SOCKET that we are alive... */ (void)sock_register(&inet_family_ops); #ifdef CONFIG_SYSCTL ip_static_sysctl_init(); #endif /* * Add all the base protocols. */ if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol\n", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol\n", __func__); #ifdef CONFIG_IP_MULTICAST if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0) pr_crit("%s: Cannot add IGMP protocol\n", __func__); #endif /* Register the socket-side information for inet_create. */ for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r) INIT_LIST_HEAD(r); /*把inetsw_array[]注册进基础原型(base protocol)的数组链表中*/ for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q) inet_register_protosw(q); ........ }
至此回到__socket_create()的分析。pf = rcu_dereference(net_families[family]);是在RCU锁的保护下取得指定处的内容。if (!try_module_get(pf->owner))是模块检查。因为之后要调用->create,这个恰好有可能存在于某个可装载的模块中,所以先检查是否在模块中,不在的话继续执行下去。
标签:初始 color hat orm function afn dead ble 资料
原文地址:https://www.cnblogs.com/luoyang712/p/12070367.html