出现应用程序读取XML文件乱码的场景:
加入xml文件以<?xml version="1.0" encoding="utf-8" ?> 格式的;如果对xml文件进行修改了,其中包含中文字符的内容,另存为其他格式化时(比如unicod,ANSI)等等格式,则新保存的配置文件,程序读取时候将会出现乱码,不能正常的读取。
验证如下方法:
(1)、可以将XML文件拖放在IE浏览器上,会出现XML文件无法正常的在浏览器上面渲染。
(2)、通过Visual studio 打开该XML文件,会出现加载格式错误!




参看地址:http://blog.csdn.net/dinglang_2009/article/details/6895355
在日常开发工作中,我们经常会使用到XML,早已成为了一种标准。它的用途非常的广泛,但这些不是本文所重点讨论的。
相信大家在做开始时候经常碰到过“乱码”的问题,这是中国程序员非常头疼的问题。我一直很想深入研究关于“编码”的原理,无奈水平有限,那些枯燥的理论(二进制,ASCII,Unicode,UTF-8,gb2312,ISO ...光这些就让我看的两眼发黑了),实在看不下去,也很难真正搞懂搞明白。望各位网友多指点......
我将用工作中遇到的一个“XML文件乱码”的简单问题,解决问题,分析其背后的原理。
首先,我们在本地新建一个文本文件,将后缀名改为".XML”, 然后用用记事本打开,往里面添加一些符合XML文档规范的内容。如图所示:
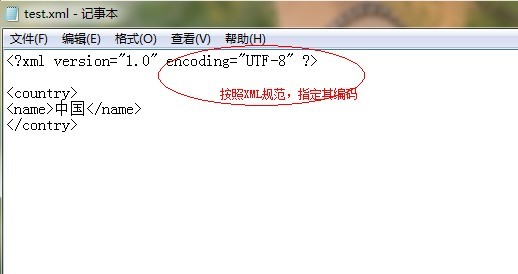
写好之后,按“ctrl+s”保存,然后使用IE浏览器打开该XML文件,验证该XML文档的规范及正确性。不料,居然解析出错了,如下:

这是咋回事呢?我的XML文档定义的格式好像没问题啊。无效字符?这肯定是典型的“编码”问题了。聪明的我第一就想到了,调整IE浏览器的“编码”嘛。
可是打开“查看”“编码”,发现那些编码格式全是灰色的,好像不能选择哦。这是因为,在定义XML文档的时候,指定了编码格式为"UTF-8",这就相当于告诉了浏览器(XML解析引擎):你必须使用"UTF-8"编码去解析我,所以无法使用其他的编码格式去查看了。
这是因为,我们在使用记事本保存该文档的时候,没有选择编码格式,默认使用的是操作系统编码(中文版的系统),也就是对应的"GB2312”编码。当我们的IE浏览器,再使用我们指定的UTF-8编码去解析该XML文档的时候,出现了乱码,所以造成了上面的错误。(Windows中的文件保存在硬盘上,默认使用操作系统编码。比如我们XML文档中定义的“中国”这两个字,保存好后,假如其对应的GB2312可能是"10001",而在UTF-8编码中的,“10001”对应的就不是“中国”了,要么找不到,要么是乱码,所以IE就拒绝显示了)。那我们应该怎么办呢?有两种办法可以解决。
第一,我们在xml文档定义时,指定其编码为gb2312,如下图所示:
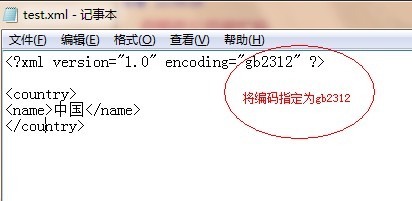
保存之后,我们再使用IE浏览器打开,结果如图:
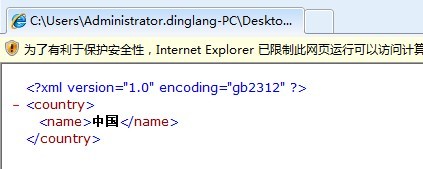
恭喜,这个问题解决了。但是这种方法不推荐使用。因为我们在定义XML文档时候,为了文档的通用性,我们一般使用UTF-8编码。
第二种方法:
我们再用记事本打开该文档,点击“另存为”,发现下面会有“编码”选项,选择“UTF-8”之后再试。
其实,我们在使用诸如 Eclipse 或者Microsoft Visual Studio之类的开发工具来定义XML文档,并不会碰到上面的问题。原因是这些IDE都非常“聪明”,你的XML文档指定的是那种编码格式,IDE在将XML文档保存到硬盘的时候,就自动使用那种格式。所以,很多局限于使用某种IDE开发的程序员,其实并不明白这些知识及其背后的原理,但他们做开发起来一样很顺手。早年据笔者了解,国内有很多大牛,写代码都是用EditPlus之类的文本编辑器,而那些在Linux/unix上面的大牛,很多都是用VI/VIM来编码。大概这就是差距吧。(呵呵。当然这不是本文讨论的重点)
从XML文件乱码问题,探寻其背后的原理,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/zfanlong1314/p/3730922.html