标签:计算 随机 合取 说明 fit 决策树 观测 存在 模式
心理学中对学习的解释是: 学习是指(人或动物)依靠经验的获得而使行为持久变化的过程。人工智能和机器学习领域的几位著名学者也对学习提出了各自的说法。 如Simon认为:如果一个系统能够通过执行某种过程而改进它的性能, 这就是学习。Minsky认为: 学习是在人们头脑中(心理内部)进行有用的变化。Tom M. Mitchell在《机器学习》一书中对学习的定义是: 对于某类任务T和性能度P, 如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善, 那么, 我们称这个计算机程序从经验E中学习。
2 机器学习的原理
从以上对于学习的解释可以看出:
(1) 学习与经验有关。
(2) 学习可以改善系统性能。
(3) 学习是一个有反馈的信息处理与控制过程。因为经验是在系统与环境的交互过程中产生的,而经验中应该包含系统输入、响应和效果等信息。因此经验的积累、性能的完善正是通过重复这一过程而实现的。
于是,我们将机器学习原理图示如下:
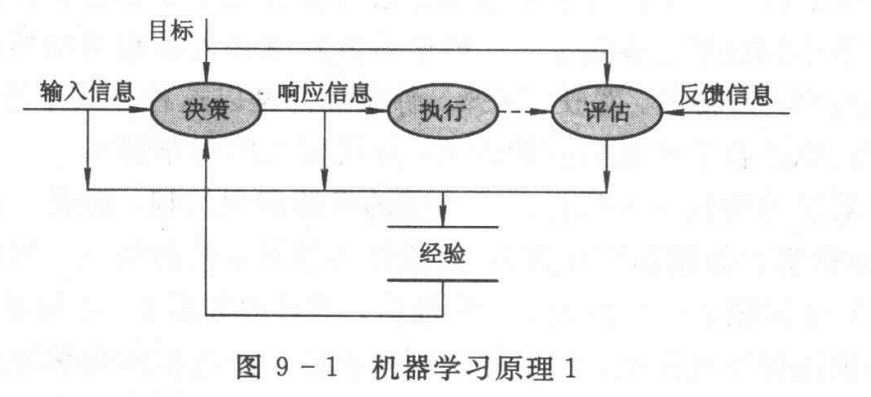
这里的输入信息是指系统在完成某任务时, 接收到的环境信息; 响应信息是指对输入信息做出的回应;执行是指根据响应信息实施相应的动作或行为。
按图9-1, 机器学习的流程就是:
① 对于输入信息, 系统根据目标和经验做出决策予以响应, 即执行相应动作;
② 对目标的实现或任务的完成情况进行评估;
③ 将本次的输入、响应和评价作为经验予以存储记录。可以看出, 第一次决策时系统中还无任何经验, 但从第二次决策开始, 经验便开始积累。
这样, 随着经验的丰富, 系统的性能自然就会不断改善和提高。
图9-1所示的学习方式现在一般称为记忆学习。例如, Samuel的跳棋程序就采用这种记忆学习方法。还有,基于范例的学习也可以看作是这种记忆学习的一个特例。记忆学习实际上也是人类和动物的一种基本学习方式。然而, 这种依靠经验来提高性能的记忆学习存在严重不足。其一,由于经验积累是一个缓慢过程, 所以系统性能的改善也很缓慢; 其二,由于经验毕竟不是规律, 故仅凭经验对系统性能的改善是有限的, 有时甚至是靠不住的。
所以, 学习方式需要延伸和发展。可想而知,如果能在积累的经验中进一步发现规律, 然后利用所发现的规律即知识来指导系统行为,那么,系统的性能将会得到更大的改善和提高,于是, 我们有图9-2所示的机器学习原理2。 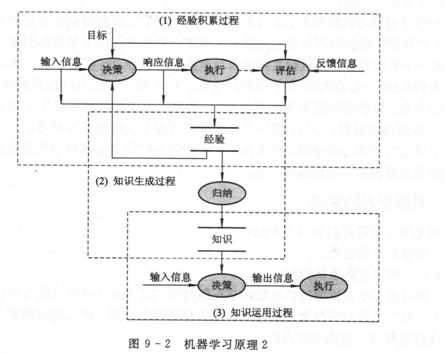
可以看出,这才是一个完整的学习过程。它可分为三个子过程, 即经验积累过程、知识生成过程和知识运用过程。事实上,这种学习方式就是人类和动物的技能训练或者更一般的适应性训练过程, 如骑车、驾驶、体操、游泳等都是以这种方式学习的。所以, 图9-2所示这种学习方式也适合于机器的技能训练, 如机器人的驾车训练。
但现在的机器学习研究一般都省去了上面的经验积累过程, 而是一开始就把事先组织好的经验数据(包括实验数据和统计数据)直接作为学习系统的输入, 然后对其归纳推导而得出知识, 再用所得知识去指导行为、改善性能, 其过程如图9-3所示。在这里把组织好的经验数据称为训练样本或样例, 把由样例到知识的转换过程称为学习或训练。 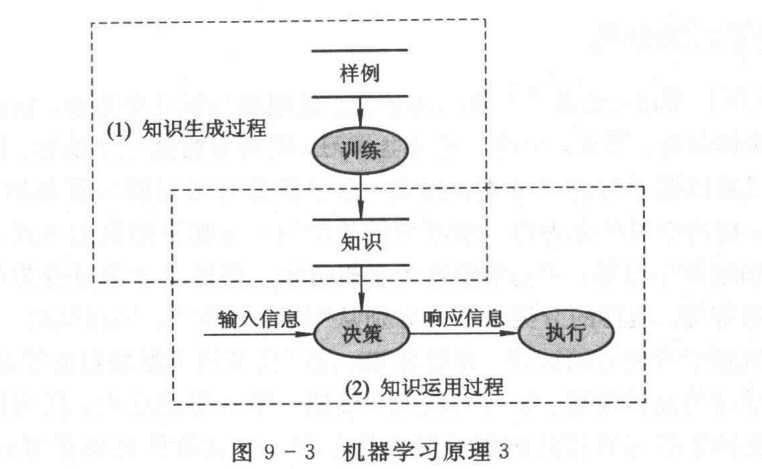
考察上面的图9-1、 图9-2和图9-3可以发现, 从经验数据中发现知识才是机器学习的关键环节。所以, 在机器学习中, 人们就进一步把图9-3所示的机器学习过程简化为只有知识生成一个过程(如图9-4 所示), 即只要从经验数据归纳推导出知识就算是完成了学习。
可以看出, 图9-4所示的这类机器学习已经与机器学习的本来含义不一致了, 实际上似乎已变成纯粹的知识发现了。 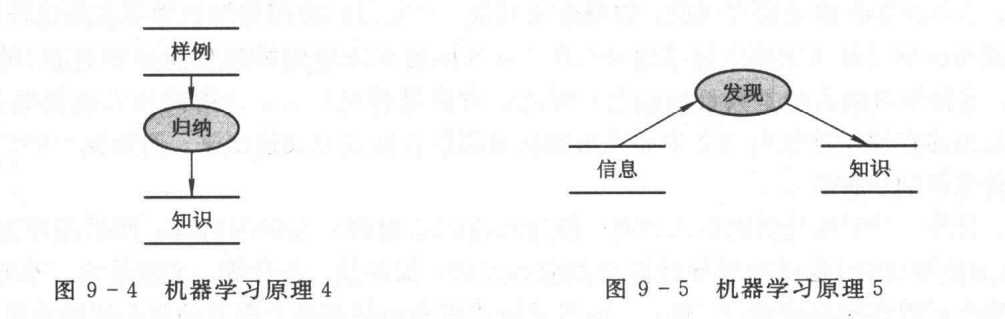
如果把训练样例再进一步扩充为更一般的数据信息,把归纳推导过程扩充为更一般的规律发现过程,会得到图9-5所示的更一般的机器学习原理图。实际上,当前的机器学习领域的主要研究的正是这类机器学习。也就是说,虽然从概念上讲,学习是系统基于经验的自我完善过程,但实际上现在的机器学习领域的主要内容已经转变为机器知识的发现了。
从图9-5可以看出, 机器学习可分为信息、发现和知识三个要素, 它们分别是机器学习的对象、方法和目标。那么, 谈论一种机器学习, 就要考察这三个要素。而分别基于这三个要素, 就可以对机器学习进行分类。例如,由于信息有语言符号型与数值数据型之分, 因此基于信息,机器学习可分为符号学习和数值学习; 而基于知识的形式,机器学习又可分为规则学习和函数学习等; 若基于发现的逻辑方法, 则机器学习可分为归纳学习、演绎学习和类比学习等等。 这样的分类也就是分别从“从哪儿学?”、“怎样学?” 和“学什么?”这三个着眼点对机器学习进行的分类。
1) 模拟人脑的机器学习
(1) 符号学习: 模拟人脑的宏观心理级学习过程, 以认知心理学原理为基础, 以符号数据为输入, 以符号运算为方法, 用推理过程在图或状态空间中搜索, 学习的目标为概念或规则等。符号学习的典型方法有记忆学习、示例学习、演绎学习、 类比学习、解释学习等。
(2) 神经网络学习(或连接学习):模拟人脑的微观生理级学习过程, 以脑和神经科学原理为基础,以人工神经网络为函数结构模型, 以数值数据为输入, 以数值运算为方法,用迭代过程在系数向量空间中搜索,学习的目标为函数。典型的连接学习有权值修正学习、拓扑结构学习等。
2) 直接采用数学方法的机器学习
这种机器学习方法主要有统计机器学习。而统计机器学习又有广义和狭义之分。
广义统计机器学习指以样本数据为依据,以概率统计理论为基础,以数值运算为方法的一类机器学习。在这个意义下, 神经网络学习也可划归为统计学习范畴。 统计学习又可分为以概率表达式函数为目标和以代数表达式函数为目标两大类。 前者的典型有贝叶斯学习、贝叶斯网络学习等, 后者的典型有几何分类学习方法和支持向量机(SVM)。
2. 基于学习方法的分类
1) 归纳学习
(1) 符号归纳学习: 典型的符号归纳学习有示例学习、 决策树学习等。
(2) 函数归纳学习(发现学习): 典型的函数归纳学习有神经网络学习、示例学习、发现学习、 统计学习等。
2) 演绎学习
3) 类比学习
典型的类比学习有案例(范例)学习。
4) 分析学习
典型的分析学习有案例(范例)学习和解释学习等。
3. 基于学习方式的分类
(1) 有导师学习(监督学习,supervised learning):利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。正如人们通过已知病例学习诊断技术那样,计算机要通过学习才能具有识别各种事物和现象的能力。用来进行学习的材料就是与被识别对象属于同类的有限数量样本。监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的类别。若所给的学习样本不带有类别信息,就是无监督学习。任何一种学习都有一定的目的,对于模式识别来说,就是要通过有限数量样本的学习,使分类器在对无限多个模式进行分类时所产生的错误概率最小。
(2) 无导师学习(无监督学习,unsupervised learning):设计分类器时候,用于处理未被分类标记的样本集。输入数据中无导师信号, 采用聚类方法,学习结果为类别。典型的无导师学习有发现学习、聚类学习、竞争学习等。
(3) 强化学习(增强学习): 以环境反馈(奖/惩信号)作为输入, 以统计和动态规划技术为指导的一种学习方法。
4. 基于数据形式的分类
(1) 结构化学习: 以结构化数据为输入,以数值计算或符号推演为方法。典型的结构化学习有神经网络学习、统计学习、决策树学习和规则学习。
(2) 非结构化学习:以非结构化数据为输入, 典型的非结构化学习有类比学习、案例学习、解释学习、文本挖掘、图像挖掘、 Web挖掘等。
5. 基于学习目标的分类
(1) 概念学习: 即学习的目标和结果为概念, 或者说是为了获得概念的一种学习。典型的概念学习有示例学习。
(2) 规则学习: 即学习的目标和结果为规则, 或者说是为了获得规则的一种学习。典型的规则学习有决策树学习。
(3) 函数学习: 即学习的目标和结果为函数, 或者说是为了获得函数的一种学习。典型的函数学习有神经网络学习。
(4) 类别学习: 即学习的目标和结果为对象类, 或者说是为了获得类别的一种学习。 典型的类别学习有聚类分析。
(5) 贝叶斯网络学习: 即学习的目标和结果是贝叶斯网络, 或者说是为了获得贝叶斯网络的一种学习。其又可分为结构学习和参数学习。
当然, 以上仅是机器学习的一些分类而并非全面分类。 事实上,除了以上分类外, 还有许多其他分法。 例如, 有些机器学习还需要背景知识作指导, 这就又有了基于知识的机器学习类型。 如解释学习就是一种基于知识的机器学习。
记忆学习也称死记硬背学习或机械学习。这种学习方法不要求系统具有对复杂问题求解的能力, 也就是没有推理能力, 系统的学习方法就是直接记录与问题有关的信息, 然后检索并利用这些存储的信息来解决问题。例如, 对于某个数据x, 经过某种计算过程得到的结果是y, 那么系统就把(x, y)作为联想对存储起来, 以后再要对x 作同样的计算时,就可通过查询(而不是计算)直接得到y。又如,对于某个事实A, 经过某种推理而得到结论B, 那么就可把序对(A, B)作为一条规则而记录下来, 以后就可以由A直接得到B。
使用记忆学习方法的一个成功例子是Samuel的跳棋程序(1959年开发), 这个程序是靠记住每一个经过评估的棋局势态, 来改进弈棋的水平。程序采用极小—极大分析的搜索策略来估计可能的未来棋盘局势, 学习环节只存储这些棋盘势态估值及相应的索引, 以备以后弈棋使用。 例如某一个势态A轮到程序走步, 这时程序考虑向前搜索三步, 根据假设的端节点静态值, 用极小—极大法可求得A的倒推值Av。这时系统记住了该棋局及其倒推值[A,Av]。现在假定以后弈棋中, 棋局E的搜索树端节点中出现了A,这时就可以检索已存的Av来使用, 而不必再去计算其静态估值。这不仅提高了搜索效率,更重要的是A的倒推值比A的静态值更准确。用了所记忆的A倒推值,对棋局E来说, 相当于局部搜索深度加大到6, 因而E的结果得到了改善。根据文献报道,Samuel程序由于有机械学习机制, 最后竟能战胜跳棋冠军。
机械学习是基于记忆和检索的办法, 学习方法很简单, 但学习系统需要几种能力。
(1) 能实现有组织的存储信息。为了使利用一个已存的信息比重新计算该值来得快, 必须有一种快速存取的方法。如在Samuel的程序中,通过对棋子位置的布局上加几个重要特征(如棋盘上棋子的数目)做为索引以利于检索。
(2) 能进行信息综合。通常存储对象的数目可能很大, 为了使其数目限制在便于管理的范围内, 需要有某种综合技术。 在Samuel程序中, 被存储的对象数目就是博弈中可能出现的各种棋局棋子位置数目, 该程序用简单的综合形式来减少这个数目, 例如只存储一方棋子位置, 就可使存储的棋子位置数目减少一半, 也可以利用对称关系进行综合。
(3) 能控制检索方向。 当存储对象愈多时, 其中可能有多个对象与给定的状态有关,这样就要求程序能从有关的存储对象中进行选择, 以便把注意力集中到有希望的方向上来。Samuel程序采用优先考虑相同评分下具有较少走步就能到达那个对象的方向。
示例学习也称实例学习, 它是一种归纳学习。示例学习是从若干实例(包括正例和反例)中归纳出一般概念或规则的学习方法。 例如学习程序要学习“狗”的概念, 可以先提供给程序以各种动物, 并告知程序哪些动物是“狗”, 哪些不是“狗”, 系统学习后便概括出“狗”的概念模型或类型定义, 利用这个类型定义就可作为动物世界中识别“狗”的分类的准则。 这种构造类型定义的任务称为概念学习, 当然这个任务所使用的技术必须依赖于描述类型(概念)的方法。 下面我们使用Winston(1975年开发) 提出的结构化概念学习程序的例子作为模型来说明示例学习的过程。
Winston的程序是在简单的积木世界领域中运行,其目的是要建立积木世界中物体概念定义的结构化表示,例如学习房子、帐篷和拱的概念,构造出这些概念定义的结构化描述。
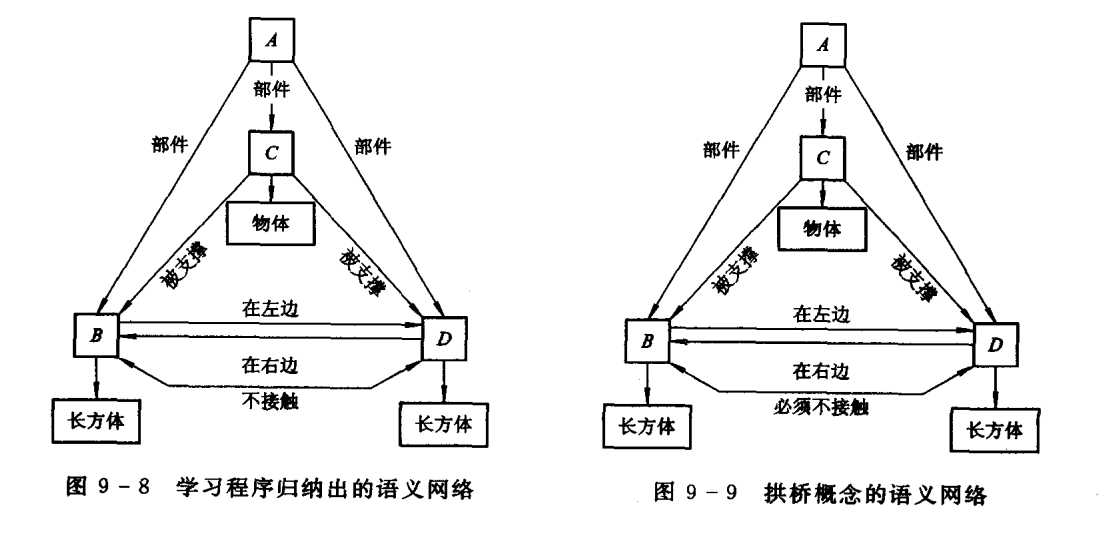
系统的输入是积木世界某物体(或景象)的线条图, 使用语义网络来表示该物体结构化的描述。例如系统要学习拱桥概念, 就给学习程序输入第一个拱桥示例,得到的描述如图 9-6所示,这个结构化的描述就是拱桥概念的定义。接着再向程序输入第二个拱桥示例, 其描述如图 9-7所示。这时学习程序可归纳出如图 9-8所示的描述。 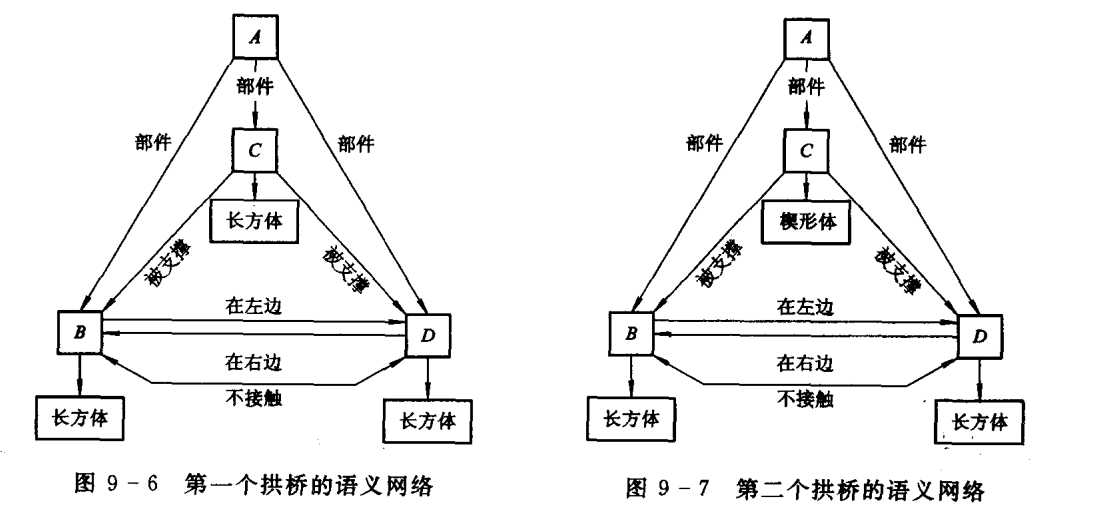
例9.1 假设示例空间中有桥牌中“同花”概念的两个示例:
示例1:
花色(c1,梅花)∧花色(c2,梅花)∧花色(c3,梅花)∧花色(c4,梅花)→同花(c1,c2,c3,c4)
示例2:
花色(c1,红桃)∧花色(c2,红桃)∧花色(c3,红桃)∧花色(c4,红桃)→同花(c1,c2,c3,c4)
对于这两个示例,学习系统运用变量代换常量规则进行归纳推理,便得到一条关于同花的一般性规则:
花色(c1,x)∧花色(c2,x)∧花色(c3,x)∧花色(c4,x)→同花(c1,c2,c3,c4)
例9.2 假设示例空间存放有如下的三个示例:
示例1:(0,2,7) 示例2:(6,-1,10) 示例3:(-1,-5,-10)
这是三个3维向量,表示空间中的三个点。现要求求出过这三点的曲线。
对于这个问题可采用通常的曲线拟合技术,归纳出规则:
(x,y,2x+3y+1)
即 z=2x+3y+1
注:实际工作中,变量间未必都有线性关系,如服药后血药浓度与时间的关系;疾病疗效与疗程长短的关系;毒物剂量与致死率的关系等常呈曲线关系。曲线拟合(curve fitting)是指选择适当的曲线类型来拟合观测数据,并用拟合的曲线方程分析两变量间的关系。
决策树(decision tree)也称判定树,它是由对象的若干属性、属性值和有关决策组成的一棵树。其中的节点为属性(一般为语言变量),分枝为相应的属性值(一般为语言值)。从同一节点出发的各个分枝之间是逻辑“或”关系;根节点为对象的某一个属性;从根节点到每一个叶子节点的所有节点和边,按顺序串连成一条分枝路径,位于同一条分枝路径上的各个“属性-值”对之间是逻辑“与”关系,叶子节点为这个与关系的对应结果,即决策。例如图9-10就是一棵决策树。其中,A, B, C代表属性,ai, bj, ck代表属性值,dl代表对应的决策。处于同一层的属性(如图中的B, C)可能相同,也可能不相同,所有叶子节点(如图中的dl ,l=1,2,…, 6)所表示的决策中也可能有相同者。
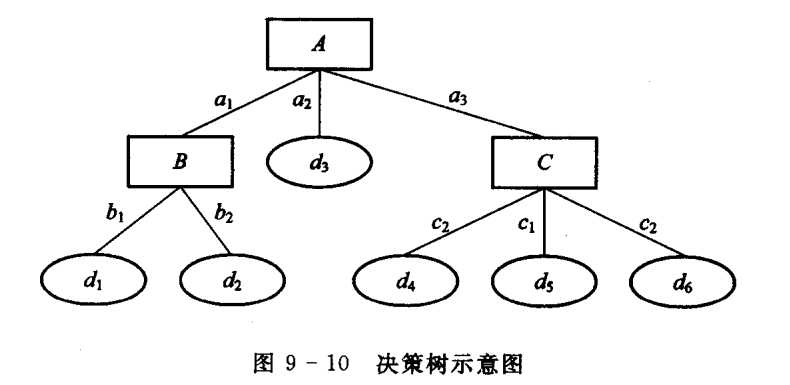
由图9-10不难看出,一棵决策树上从根节点到每一个叶子节点的分枝路径上的诸“属性-值”对和对应叶子节点的决策,刚好就构成一个产生式规则:诸“属性-值”对的合取构成规则的前提,叶子节点的决策就是规则的结论。例如,图9-10中从根节点A到叶子节点d2的这一条分枝路径就构成规则:
(A= a1)∧(B = b2) => d2
而不同分枝路径所表示的规则之间为析取关系。
例9.3 图9-11所示是机场指挥台关于飞机起飞的简单决策树。 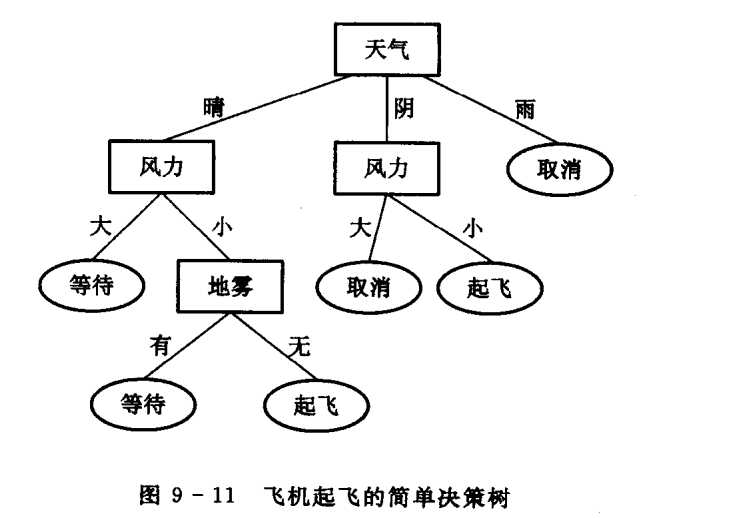
例9.4 图9-12所示是一个描述“兔子”概念的决策树。 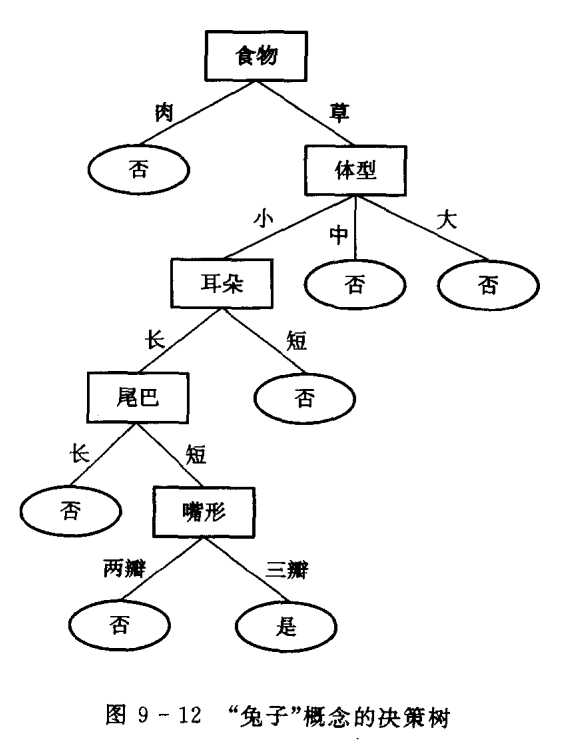
决策树是一种知识表示形式, 构造决策树可以由人来完成, 但也可以由机器从一些实例中总结、归纳出来, 即由机器学习而得。 机器学习决策树也就是所说的决策树学习。
决策树学习是一种归纳学习。由于一棵决策树就表示了一组产生式规则, 因此决策树学习也是一种规则学习。特别地, 当规则是某概念的判定规则时,这种决策树学习也就是一种概念学习。
决策树学习首先要有一个实例集。实例集中的实例都含有若干“属性-值”对和一个相应的决策、结果或结论。一个实例集中的实例要求应该是相容的, 即相同的前提不能有不同的结论(当然, 不同的前提可以有相同的结论)。对实例集的另一个要求是, 其中各实例的结论既不能完全相同也不能完全不同, 否则该实例集无学习意义。
决策树学习的基本方法和步骤是:
首先,选取一个属性, 按这个属性的不同取值对实例集进行分类; 并以该属性作为根节点,以这个属性的诸取值作为根节点的分枝, 进行画树。
然后,考察所得的每一个子类, 看其中的实例的结论是否完全相同。如果完全相同, 则以这个相同的结论作为相应分枝路径末端的叶子节点; 否则, 选取一个非父节点的属性, 按这个属性的不同取值对该子集进行分类, 并以该属性作为节点, 以这个属性的诸取值作为节点的分枝, 继续进行画树。 如此继续,直到所分的子集全都满足: 实例结论完全相同, 而得到所有的叶子节点为止。这样, 一棵决策树就被生成。下面我们进一步举例说明。
表9.1 汽车驾驶保险类别划分实例集 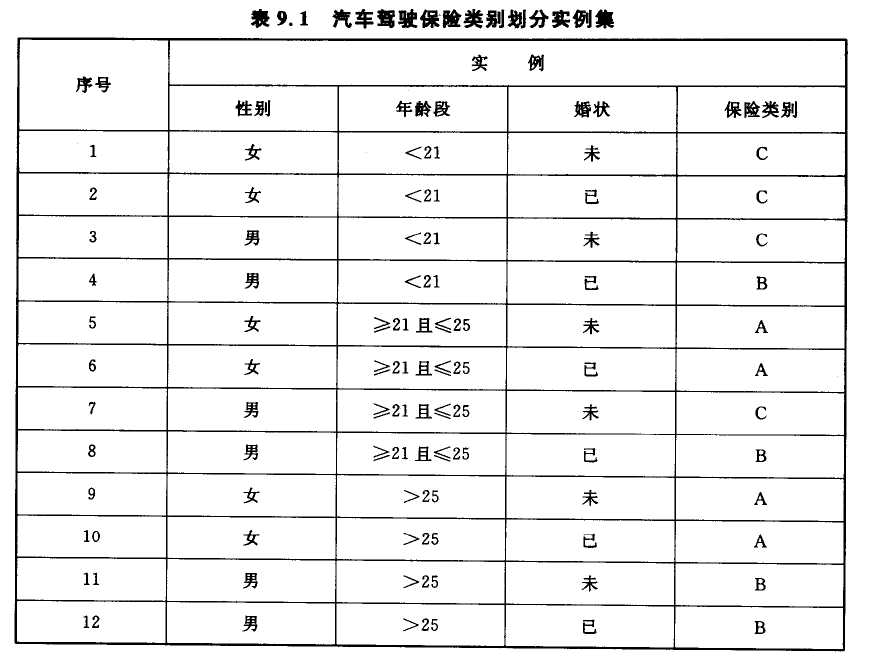
可以看出,该实例集中共有12个实例,实例中的性别、年龄段和婚状为3个属性, 保险类别就是相应的决策项。为表述方便起见, 我们将这个实例集简记为
S={(1,C), (2,C), (3,C), (4,B), (5,A), (6,A), (7,C), (8,B), (9,A), (10,A), (11,B), (12,B)}
其中每个元组表示一个实例, 前面的数字为实例序号, 后面的字母为实例的决策项保险类别(下同)。另外, 为了简洁, 在下面的决策树中我们用“小”、“中”、“大”分别代表“<21”、 “≥21且≤25”、 “>25”这三个年龄段。
显然, S中各实例的保险类别取值不完全一样, 所以需要将S分类。对于S, 我们按属性“性别”的不同取值将其分类。 由表9.1可见, 这时S应被分类为两个子集:
S1= {(3,C), (4,B), (7,C), (8,B), (11,B), (12,B)}
S2={(1,C), (2,C), (5,A), (6,A), (9,A), (10,A)}
于是, 我们得到以性别作为根节点的部分决策树(见图9-13(a))。

考察S1和S2,可以看出,在这两个子集中,各实例的保险类别也不完全相同。这就是说,还需要对S1和S2进行分类。对于子集S1,我们按“年龄段”将其分类;同样,对于子集S2,也按“年龄段”对其进行分类(注意:对于子集S2,也可按属性“婚状”分类)。分别得到子集S11, S12, S13和S21, S22, S23。于是,我们进一步得到含有两层节点的部分决策树(如图9-13(b)所示)。
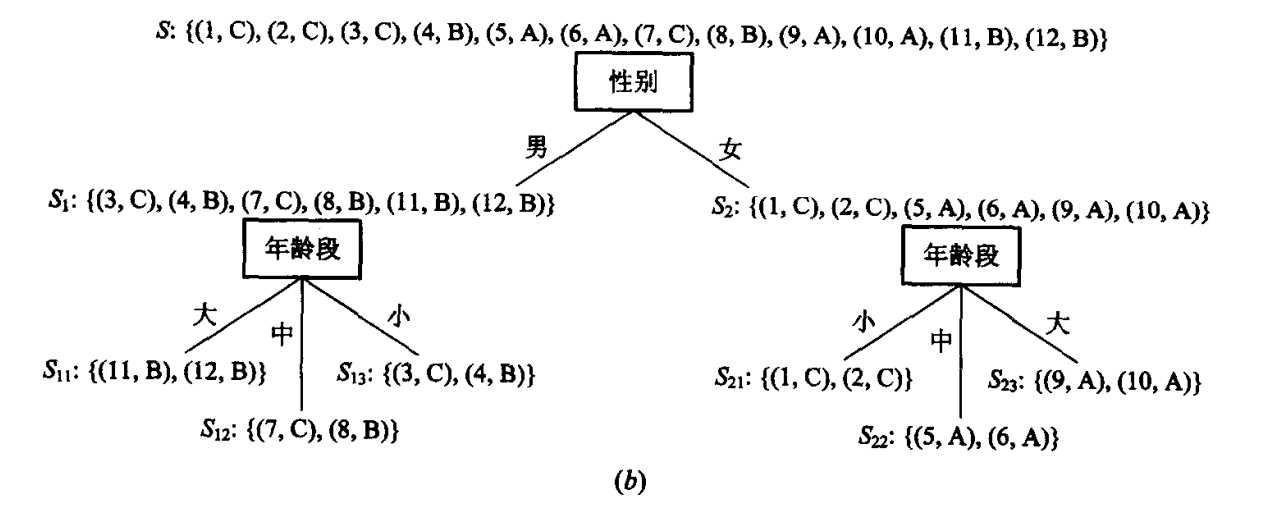
注意到,这时除了S12和S13外,其余子集中各实例的保险类别已完全相同。所以,不需再对其进行分类,而每一个子集中那个相同的保险类别值就可作为相应分枝的叶子节点。添上这些叶子节点,我们又进一步得到发展了的部分决策树(如图9-13(c)所示)。
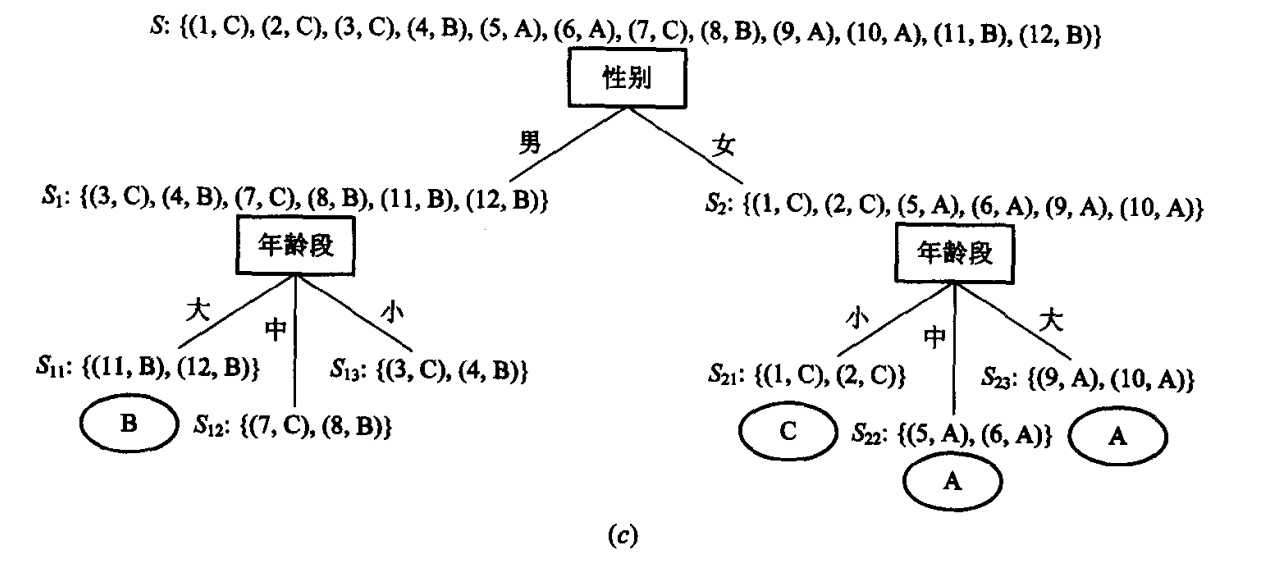
接着对S12和S13,按属性“婚状”进行分类(也只能按“婚状”进行分类)。由于所得子集S121, S121和S131, S132中再都只含有一个实例,因此无需对它们再进行分类。这时这4个子集中各自唯一的保险类别值也就是相应分枝的叶子节点。添上这两个叶子节点,就得到如图9-13(d)所示的决策树。 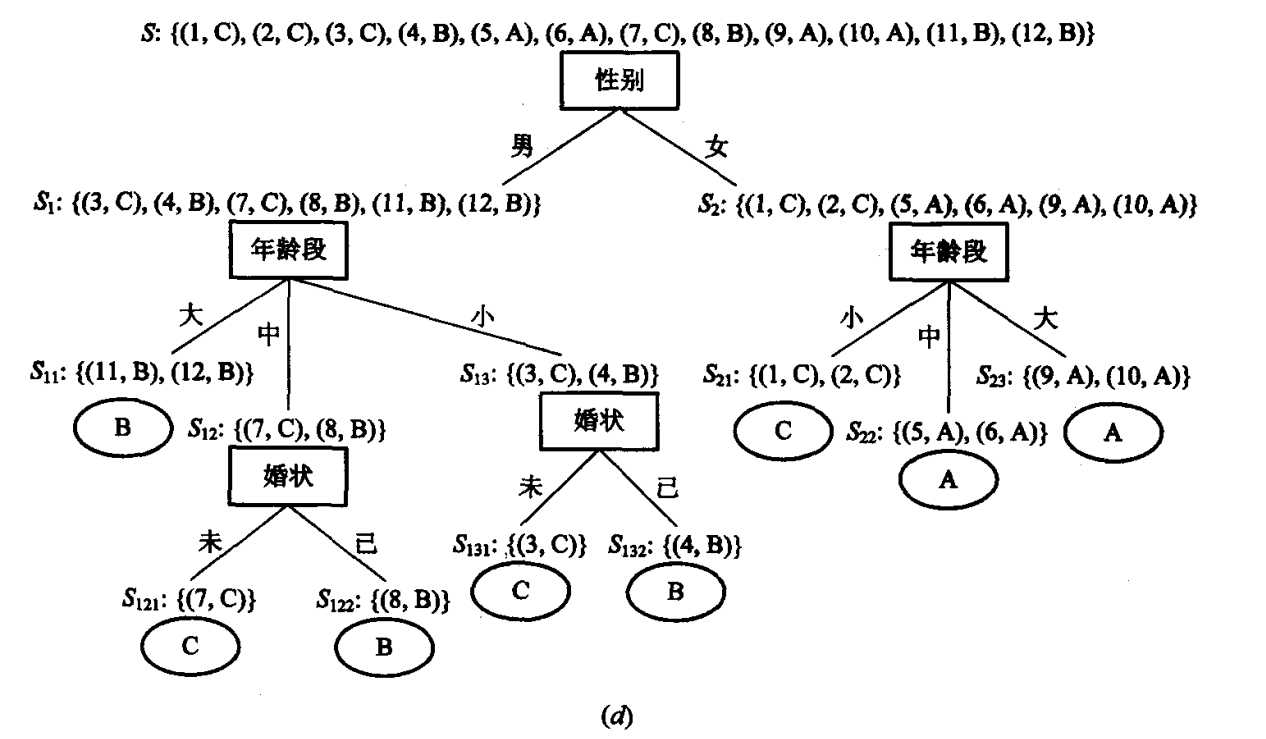
至此,全部分类工作宣告完成。现在将上图中所有的实例集去掉,我们就得到了关于保险类别划分问题的一颗完整的决策树如图9-13(e)
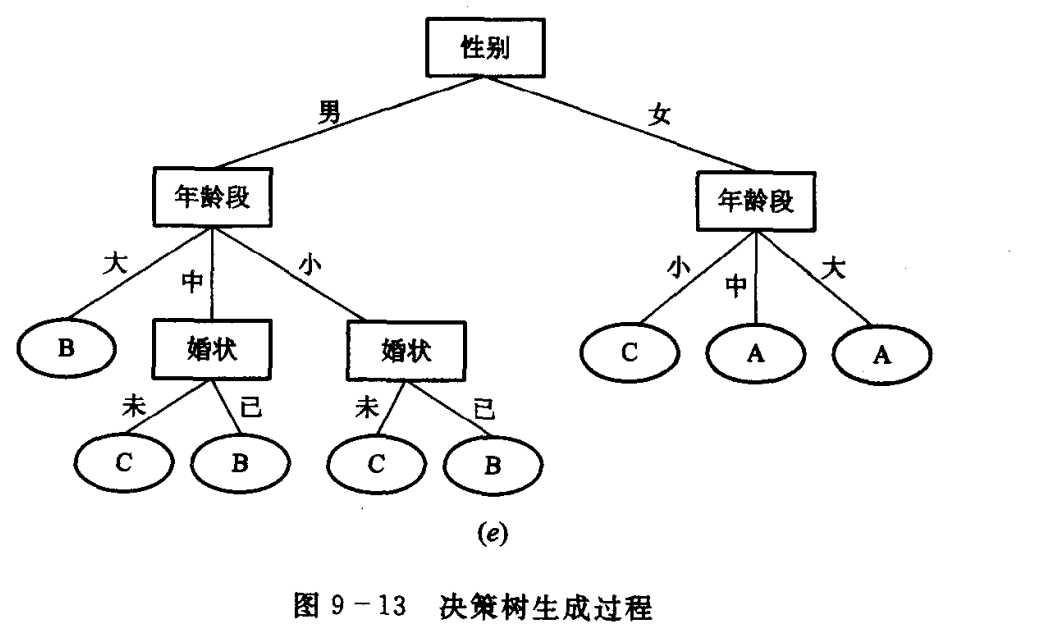
由这个决策树即得下面的规则集:
① 女性且年龄在25岁以上, 则给予A类保险。
② 女性且年龄在21岁到25岁之间, 则给予A类保险。
③ 女性且年龄在21岁以下, 则给予C类保险。
④ 男性且年龄在25岁以上, 则给予B类保险。
⑤ 男性且年龄在21岁到25岁之间且未婚, 则给予C类保险。
⑥ 男性且年龄在21岁到25岁之间且已婚, 则给予B类保险。
⑦ 男性且年龄在21岁以下且未婚, 则给予C类保险。
⑧ 男性且年龄在21岁以下且已婚, 则给予B类保险。
由上面的例子我们看到,决策树的构造是基于实例集的分类进行的,也就是说,决策树的构造过程就是对实例集的分类过程。
我们在上面的例子中,作为根节点和其他子节点的属性我们都是随意选取的。显而易见,不同的属性选择会得到不同决策树。而不同的决策树意味着不同的学习效率和学习效果。自然,我们更希望得到最简的决策树,于是就出现一个问题:怎样选取属性才能使得决策树最简?对于这个问题,下面ID3算法会给出一个回答。
ID3算法是一个经典的决策树学习算法, 由Quinlan于1979年提出。 ID3算法的基本思想是, 以信息熵为度量, 用于决策树节点的属性选择, 每次优先选取信息量最多的属性或者说能使熵值变成最小的属性, 以构造一棵熵值下降最快的决策树, 到叶子节点处的熵值为0。 此时, 每个叶子节点对应的实例集中的实例属于同一类。
1) 信息熵和条件熵
ID3算法将实例集视为一个离散的信息系统,用信息熵(entropy of information)表示其信息量。实例集中实例的结论视为随机事件, 而将诸属性看做是加入的信息源。
设S是一个实例集(S也可以是子实例集),A为S中实例的一个属性。H(S)和H(S|A)分别称为实例集S的信息熵和条件熵, 其计算公式如下: 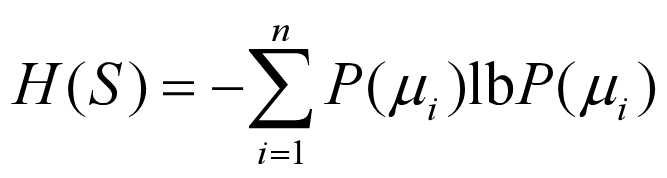
其中,μi(i=1, 2, …, n)为S中各实例所有可能的结论;lb即log2。 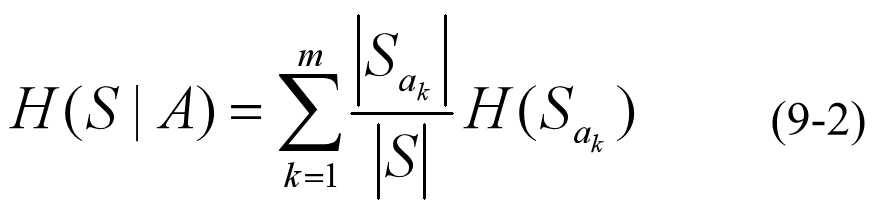
其中,ak(k=1, 2, …, m)为属性A的取值, Sak为按属性A对实例集S进行分类时所得诸子类中与属性值ak对应的那个子类。
2) 基于条件熵的属性选择
下面就是ID3算法中用条件熵指导属性选择的具体做法。
对于一个待分类的实例集S,先分别计算各可取属性Aj(j=1, 2, …,l)的条件熵H(S|Aj), 然后取其中条件熵最小的属性As作为当前节点。
例如对于上例, 当第一次对实例集S进行分类时, 可选取的属性有: 性别、年龄段和婚状。 先分别计算S的条件熵。
按性别划分, 实例集S被分为两个子类:
S男 ={(3,C), (4,B), (7,C), (8,B), (11,B), (12,B)}
S女 ={(1,C), (2,C), (5,A), (6,A), (9,A), (10,A)}
从而, 对子集S男而言,
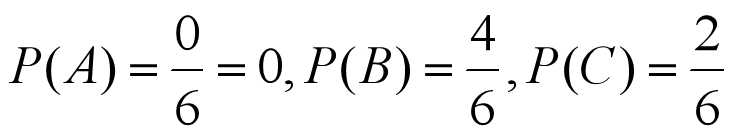
对子集S女而言,
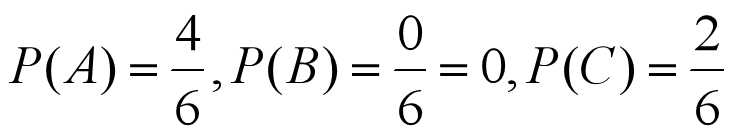
于是, 由公式(9-1)有: 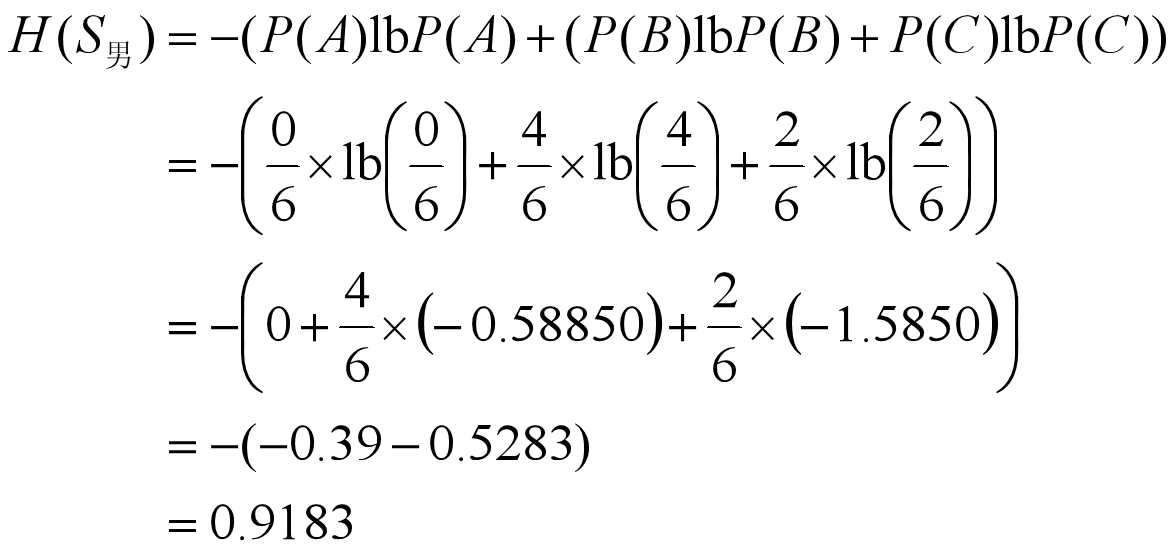
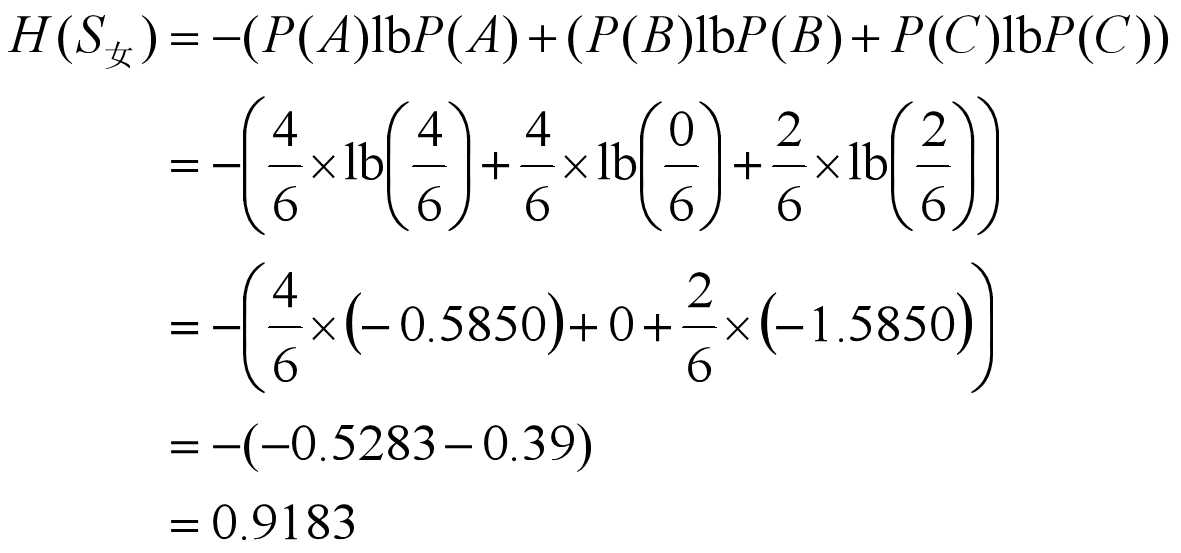
又
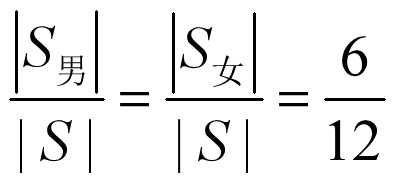
将以上3式代入公式(9-2)得: 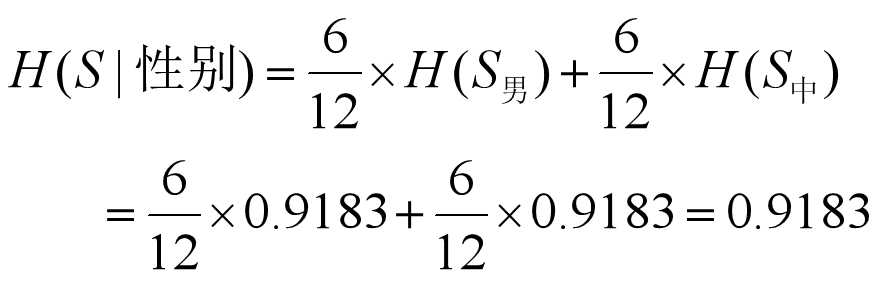
用同样的方法可求得: 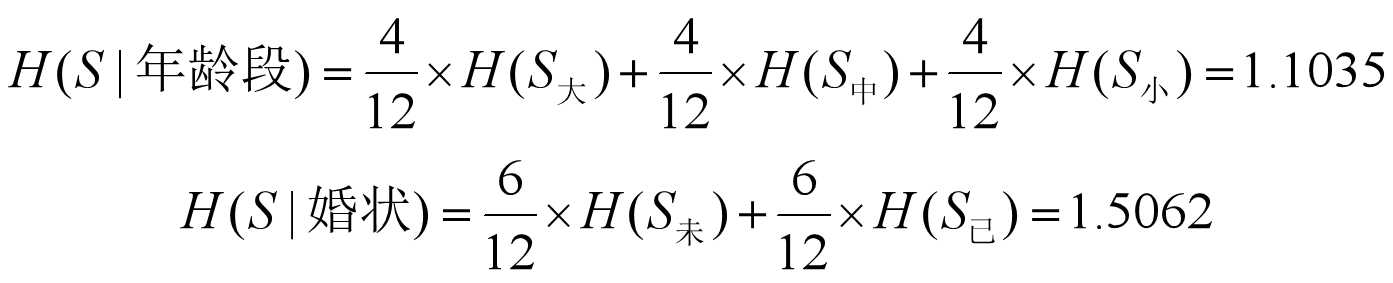
可见, 条件熵H(S|性别)为最小,所以,应取“性别”这一属性对实例集进行分类, 即以“性别”作为决策树的根节点。
3) 决策树学习的发展
决策树学习是一种很早就出现的归纳学习方法, 至今仍然在不断发展。据文献记载, 20世纪60年代初的“基本的感知器”(Elementary Perceiver and Memorizer, EPAM)中就使用了决策树学习。 稍后的概念学习系统CLS则使用启发式的前瞻方法来构造决策树。 继1979年的ID3算法之后, 人们又于1986、 1988年相继提出了ID4和ID5算法。1993年J. R. Quinlan则进一步将ID3发展成C4.5算法。另一类著名的决策树学习算法称为CART(Classification and Regression Trees)。
演绎学习是基于演绎推理的一种学习。 演绎推理是一种保真变换, 即若前提真则推出的结论也真。 在演绎学习中, 学习系统由给定的知识进行演绎的保真推理, 并存储有用的结论。 例如, 当系统能证明A→B且B→C, 则可得到规则A→C, 那么以后再要求证C, 就不必再通过规则A→B和B→C去证明, 而直接应用规则A→C即可。 演绎学习包括知识改造、 [JP3]知识编译、 产生宏操作、 保持等价的操作和其他保真变换。 演绎学习及几年才作为独立的学习策略。
这是一种基于类比推理的学习方法。 具体来讲, 就是寻找和利用事物间可类比的关系, 而从已有的知识推导出未知的知识。例如, 学生在做练习时, 往往在例题和习题之间进行对比, 企图发现相似之处, 然后利用这种相似关系解决习题中的问题。
类比学习的过程包括以下主要步骤:
(1) 回忆与联想, 即当遇到新情况或新问题时,先通过回忆与联想, 找出与之相似的已经解决了的有关问题, 以获得有关知识。
(2) 建立对应关系, 即建立相似问题知识和求解问题之间的对应关系, 以获得求解问题的知识。
(3) 验证与归纳, 即检验所获知识的有效性, 如发现有错, 就重复上述步骤进行修正, 直到获得正确的知识。对于正确的知识, 经过推广、 归纳等过程取得一般性知识。
例如, 设对象的知识是用框架集来表示, 则类比学习可描述为把原框架中若干个槽的值传递给另一个目标框架的一些槽中, 这种传递分两步进行:
(1) 利用原框架产生若干个候选的槽, 这些槽值准备传递到目标框架中。
(2) 利用目标框架中现有的信息来筛选第一步提出来的某些相似性。
标签:计算 随机 合取 说明 fit 决策树 观测 存在 模式
原文地址:https://www.cnblogs.com/wkfvawl/p/12076365.html