标签:OLE ppa pil llb 地方 subject 防止 nbsp -o
上一篇博客因为写的比较急,个人原因,导致很多地方不完善,具体功能也没有进行说明,这一篇
算是对上一篇的完善,以及对静态网页爬取的一个总结。
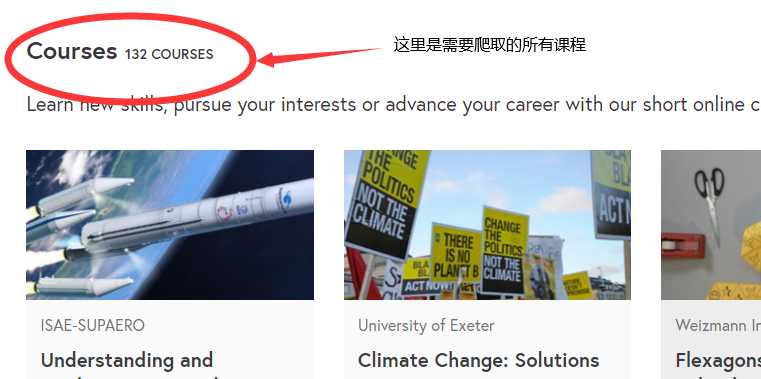
爬取futurelearn课程网中subjects类别中science-engineering-and-maths-courses课程中全部课程,
其中,每个课程需要爬取‘课程名‘, ‘课程性质与阶段学习‘, ‘介绍‘, ‘话题‘, ‘开始时间‘, ‘服务对象‘, ‘老师‘,
‘课程创作人‘等具体内容
初始URL:https://www.futurelearn.com/subjects/science-engineering-and-maths-courses
爬取要求:
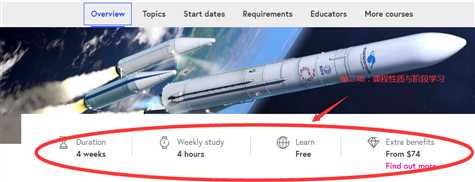
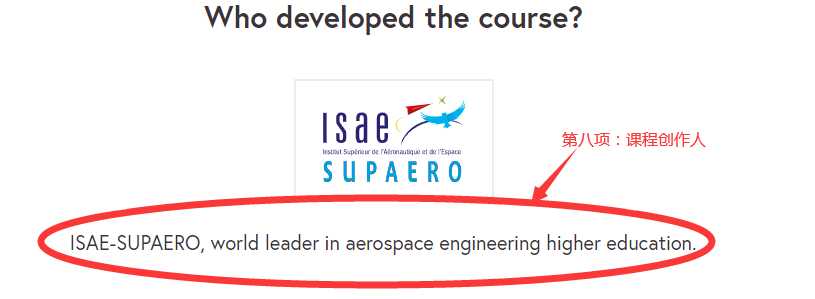
点开一个课程查看需要爬取的具体内容:

(1)通过requests请求网页。
(2)解析首页内容,将首页所有课程的URL爬取下来,并保存在列表中。
(3)遍历所有的URL,解析每个课程页面,获取里面的内容,并将每个课程的内容放入单独的列表中,
最后将所有列表存在一个大列表中,此时列表为两层。
(4)将列表里的内容存入CSV文件中。
示意图:
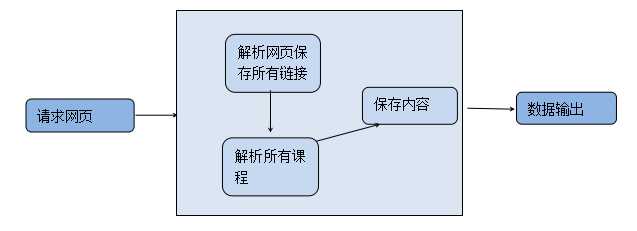
整个项目包括四大块:
(一)请求
1 def getHTMLText(url, code =‘utf-8‘): 2 try: 3 r = requests.get(url, timeout=30) 4 r.raise_for_status() 5 r.encoding = r.apparent_encoding 6 return r.text 7 except: 8 print("获取失败")
(二)获得所有课程URL
遇到的重大问题:请求得到URL多于要求的课程URL,并且爬取到的链接有多于的内容,导致部分
链接不能解析。
要得到的是courses里面的课程
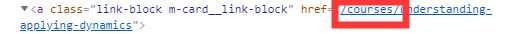
多于的不合要求的
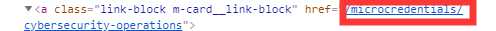
解决方案:遍历子网页,剔除多于的链接,并且将有多余内容链接里的内容替换为null
1 def getCourseList(lst, html): 2 soup = BeautifulSoup(html, ‘html.parser‘) 3 div_href = soup.find_all(‘div‘, class_=‘m-grid-of-cards m-grid-of-cards--compact‘) 4 cop = re.compile(‘href="(.*?)">‘) 5 href_get = re.findall(cop, str(div_href)) 6 z = "" 7 # print(href_get) 8 # print(type(href_get)) 9 for i in href_get: 10 j = ‘courses‘ 11 m = r‘" role="button‘ 12 if j in i: 13 if m in i: 14 i = i.replace(m, z) 15 # print("https://www.futurelearn.com"+i) 16 else: 17 pass 18 # print("https://www.futurelearn.com"+i) 19 i = "https://www.futurelearn.com" + i 20 lst.append(i) 21 22 else: 23 pass 24 # print(lst) 25 return lst
(三)获得课程信息
遇到的重大问题:(1)测试过程中有的内容只有属于自己的标签,有的内容用同一个标签,循环爬取时没有
将同一标签的内容柔和在一起。(比如课程性质与阶段学习里面有四个相同标签需要爬取)
解决方案:在for循环外定义空字符串,循环依次添加到一个字符串中
(2)爬取所有课程同一标签内容时,存在有的课程没有这项内容,导致产生异常
解决方案:通过try—except方法解决异常,并将一串“********”的字符填进去,防止某些在某些课程列表中
缺少数据,导致存入数据异常。
1 def CourseList(lst, list_1): 2 3 for i in lst: 4 list_ = [] 5 url = i 6 r = requests.get(url, timeout=30) 7 8 r.encoding = r.apparent_encoding 9 html = r.text 10 x = BeautifulSoup(html, ‘html.parser‘) 11 12 for i in x.find_all(‘h1‘, class_=‘m-dual-billboard__heading‘) : 13 list_.append(i.text) 14 # print(list_) 15 16 a_1 = ‘‘ 17 for a in x.find_all(‘span‘, class_=‘m-key-info__content‘): 18 a_1 += a.text 19 list_.append(a_1) 20 # print(list_1) 21 22 b_1 = ‘‘ 23 for b in x.find(‘div‘, class_="a-content a-content--tight").find_all(‘p‘): 24 b_1 += b.text 25 list_.append(b_1) 26 # print(list_) 27 28 c = x.find(‘section‘, class_=‘a-section a-section--alt-adjacent‘).find(‘div‘, class_=‘a-content‘) 29 list_.append(c.text) 30 # print(list_) 31 32 d = x.find(‘section‘, class_=‘a-section‘, id=‘section-dates‘).find(‘p‘, class_=‘u-responsive-alignment‘) 33 list_.append(d.text) 34 # print(list_) 35 36 e = x.find(‘section‘, class_=‘a-section‘, id=‘section-requirements‘).find(‘p‘) 37 list_.append(e.text) 38 # print(list_) 39 40 f_1 = ‘‘ 41 try: 42 43 for f in x.find(‘section‘, class_=‘a-section‘, id=‘section-educators‘).find_all(‘p‘): 44 f_1 += f.text 45 list_.append(f_1) 46 except: 47 48 list_.append(‘********‘) 49 # print(list_) 50 51 for g in x.find(‘div‘, class_="a-content a-content--contiguous-top").find(‘p‘): 52 list_.append(g) 53 list_1.append(list_) 54 # print(list_1) 55 return list_1
(四)将数据存入CSV文件
1 def write_dictionary_to_csv(list_1): 2 # print(list_1) 3 name = [‘课程名‘, ‘课程性质与阶段学习‘, ‘介绍‘, ‘话题‘, ‘开始时间‘, ‘服务对象‘, ‘老师‘, ‘课程创作人‘] 4 test = pd.DataFrame(columns=name, data=list_1) 5 test.to_csv(‘D:/test2.csv‘)
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 import re 5 import csv 6 import pandas as pd 7 8 def getHTMLText(url, code =‘utf-8‘): 9 try: 10 r = requests.get(url, timeout=30) 11 r.raise_for_status() 12 r.encoding = r.apparent_encoding 13 return r.text 14 except: 15 print("获取失败") 16 17 # 爬取基本列表 18 def getCourseList(lst, html): 19 soup = BeautifulSoup(html, ‘html.parser‘) 20 div_href = soup.find_all(‘div‘, class_=‘m-grid-of-cards m-grid-of-cards--compact‘) 21 cop = re.compile(‘href="(.*?)">‘) 22 href_get = re.findall(cop, str(div_href)) 23 z = "" 24 # print(href_get) 25 # print(type(href_get)) 26 for i in href_get: 27 j = ‘courses‘ 28 m = r‘" role="button‘ 29 if j in i: 30 if m in i: 31 i = i.replace(m, z) 32 # print("https://www.futurelearn.com"+i) 33 else: 34 pass 35 # print("https://www.futurelearn.com"+i) 36 i = "https://www.futurelearn.com" + i 37 lst.append(i) 38 39 else: 40 pass 41 # print(lst) 42 return lst 43 44 45 def CourseList(lst, list_1): 46 47 for i in lst: 48 list_ = [] 49 url = i 50 r = requests.get(url, timeout=30) 51 52 r.encoding = r.apparent_encoding 53 html = r.text 54 x = BeautifulSoup(html, ‘html.parser‘) 55 56 for i in x.find_all(‘h1‘, class_=‘m-dual-billboard__heading‘) : 57 list_.append(i.text) 58 # print(list_) 59 60 a_1 = ‘‘ 61 for a in x.find_all(‘span‘, class_=‘m-key-info__content‘): 62 a_1 += a.text 63 list_.append(a_1) 64 # print(list_1) 65 66 b_1 = ‘‘ 67 for b in x.find(‘div‘, class_="a-content a-content--tight").find_all(‘p‘): 68 b_1 += b.text 69 list_.append(b_1) 70 # print(list_) 71 72 c = x.find(‘section‘, class_=‘a-section a-section--alt-adjacent‘).find(‘div‘, class_=‘a-content‘) 73 list_.append(c.text) 74 # print(list_) 75 76 d = x.find(‘section‘, class_=‘a-section‘, id=‘section-dates‘).find(‘p‘, class_=‘u-responsive-alignment‘) 77 list_.append(d.text) 78 # print(list_) 79 80 e = x.find(‘section‘, class_=‘a-section‘, id=‘section-requirements‘).find(‘p‘) 81 list_.append(e.text) 82 # print(list_) 83 84 f_1 = ‘‘ 85 try: 86 87 for f in x.find(‘section‘, class_=‘a-section‘, id=‘section-educators‘).find_all(‘p‘): 88 f_1 += f.text 89 list_.append(f_1) 90 except: 91 92 list_.append(‘********‘) 93 # print(list_) 94 95 for g in x.find(‘div‘, class_="a-content a-content--contiguous-top").find(‘p‘): 96 list_.append(g) 97 list_1.append(list_) 98 # print(list_1) 99 return list_1 100 def write_dictionary_to_csv(list_1): 101 # print(list_1) 102 name = [‘课程名‘, ‘课程性质与阶段学习‘, ‘介绍‘, ‘话题‘, ‘开始时间‘, ‘服务对象‘, ‘老师‘, ‘课程创作人‘] 103 test = pd.DataFrame(columns=name, data=list_1) 104 test.to_csv(‘D:/test2.csv‘) 105 106 def main(): 107 star_url = "https://www.futurelearn.com/subjects/science-engineering-and-maths-courses" 108 infoList = [] 109 list_1 = [] 110 url = star_url 111 # file_name_ = ‘courses‘ 112 html = getHTMLText(url) 113 getCourseList(infoList, html) 114 CourseList(infoList, list_1) 115 write_dictionary_to_csv(list_1) 116 main()
标签:OLE ppa pil llb 地方 subject 防止 nbsp -o
原文地址:https://www.cnblogs.com/yangbiao6/p/12078039.html