标签:影响 rac 执行引擎 desc const 需要 nbsp 优化算法 保存
1.placeholder
一个数据占位符,用于在构建一个算法时留出一个位置,然后在run时填入数据。
x = tf.placeholder(tf.float32) y = tf.placeholder(tf.float32) z = x*y with tf.Session() as sess: print(sess.run(z,feed_dict={x:3.0,y:2.0}))
2.variable
存储节点作为数据流图中的有状态节点,其主要作用是在多次执行相同数据流图时存储特定的参数,如深度学习或机器学习的模型参数。对于无状态节点,其输出由输入张量和节点操作共同确定,对于有状态节点
如存储节点,其输出还会受到节点内部保存的状态值影响。
x = tf.placeholder(tf.float32) W = tf.Variable(1.0) b = tf.Variable(1.0) y = W*x + b with tf.Session() as sess: tf.global_variables_initializer().run() fetch = y.eval(feed_dict={x:3.0}) print(fetch)
3.Session
tensorflow所有的操作必须在会话中执行,所有计算任务都由它分发到其连接的执行引擎完成。
会话分为普通会话和交互式会话。
普通会话的典型使用流程,创建会话,运行会话,关闭会话
交互式会话,为用户提供类似shell的交互式编程环境,交互式会话在创建是将自己注册为默认会话,在普通会话中如果要执行张量的eval或op的run必须借助with,交互式会话中不需要。
a = tf.constant(5.0) b = tf.constant(6.0) c = a*b sess = tf.InteractiveSession() print(c.eval()) sess.close()
二、优化器
1.损失函数与优化算法
损失函数分为平方损失函数,交叉熵损失函数,指数损失函数

优化算法
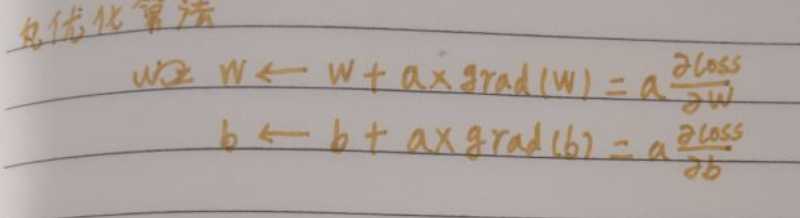
tensorflow提供的优化器
Adadelta,Adagrad,Adagrad Dual Averaging,Adam,Ftrl,Gradient Descent,Momentum,Proximal Adagrad,Proximal Gradient Descent,Rmsprop,Synchronize Replicas
标签:影响 rac 执行引擎 desc const 需要 nbsp 优化算法 保存
原文地址:https://www.cnblogs.com/yangyang12138/p/12078931.html