标签:ima 顺序 kafka集群 work 维护 临时性 时序 共享锁 最小
zookeeper简介ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务。
ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服 务封装起来,构成一个高效可靠的原语集,并以一系列简单易用 的接口提供给用户使用。
1、发布者将数据发布到Zookeeper的节点上,供订阅者进行数据订阅。
2、Zookeeper采用了推拉相结合的模式,客户端向服务端注册自己需要关注的节点,一旦该节点数据发生变更,那么服务端就会向相应的客户端推送Watcher事件通知,客户端接收到此通知后,主动到服务端获取最新的数据。
1、排它锁也叫独占锁
① 获取锁,在需要获取排它锁时,所有客户端通过调用接口,在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。Zookeeper可以保证只有一个客户端能够创建成功,没有成功的客户端需要注册/exclusive_lock节点监听。
② 释放锁,当获取锁的客户端宕机或者正常完成业务逻辑都会导致临时节点的删除,此时,所有在/exclusive_lock节点上注册监听的客户端都会收到通知,可以重新发起分布式锁获取。
2、读写锁
① 获取锁,在需要获取共享锁时,所有客户端都会到/shared_lock下面创建一个临时顺序节点,如果是读请求,那么就创建例如/shared_lock/host1-R-00000001的节点,如果是写请求,那么就创建例如/shared_lock/host2-W-00000002的节点。
② 判断读写顺序
1. 创建完节点后,获取/shared_lock节点下所有子节点,并对该节点变更注册监听。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 对于读请求:若没有比自己序号小的子节点或所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到共享锁,同时开始执行读取逻辑,若有写请求,则需要等待。对于写请求:若自己不是序号最小的子节点,那么需要等待。
4. 接收到Watcher通知后,重复步骤1。
③ 释放锁,其释放锁的流程与独占锁一致。
两种锁如何避免羊群效应?
1、独占锁:

2、读写锁呢?
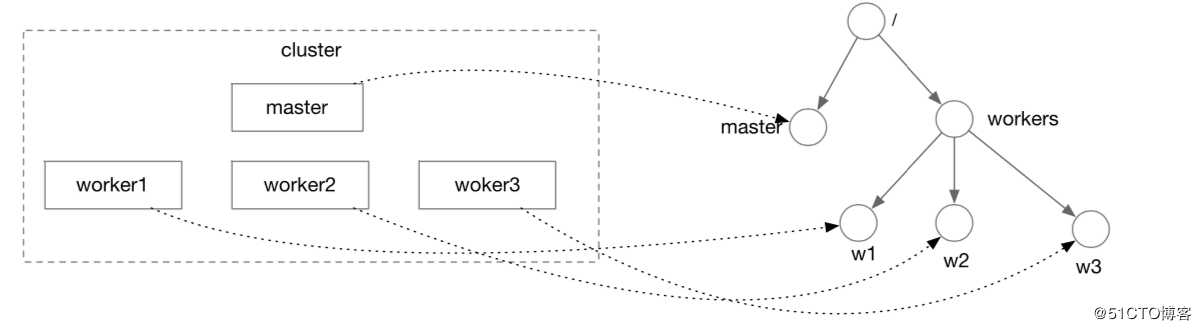
1、master-worker模式
一个Kafka集群由多个broker组成,这些borker是系统中的worker。Kafka会从这些worker选举出一个 controller,这个controlle是系统中的master,负责把topic和partition分配给各个broker。
2、Topic注册
Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护。
3、消费分区与消费者的关系,消息消费位移记录
同一个消费者组内,每个分区只能有一个消费者进行消费,每条消息只被消费一次,所以消费者和消费分区之间的关系也写入zookeeper。
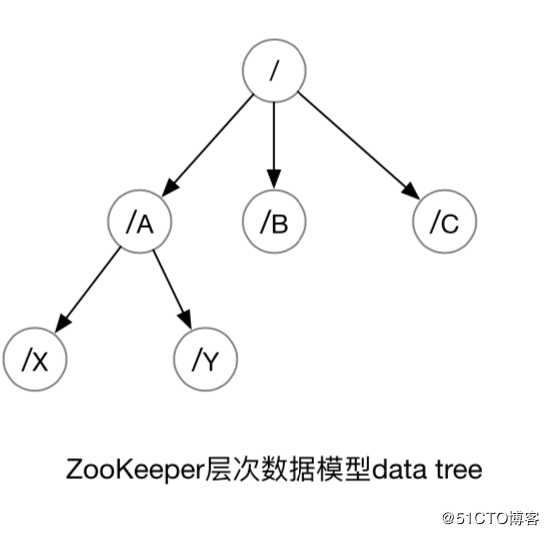
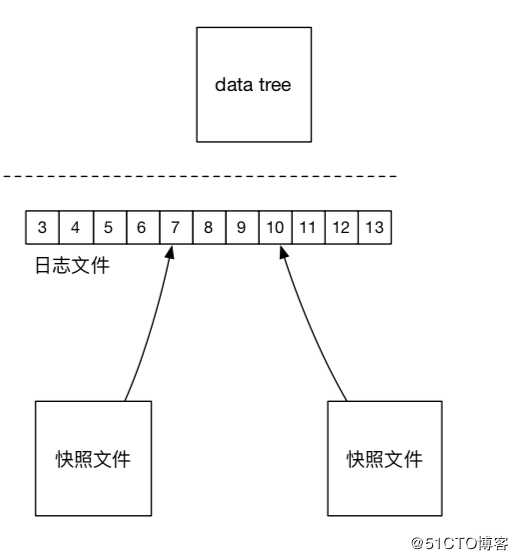
ZooKeeper 使用文件系统模型,Datatree。Datatree 的每个节点叫作 znode。每个节点都可以保存数据。每个节点都有一个版本 (version)。版本从 0 开始计数。
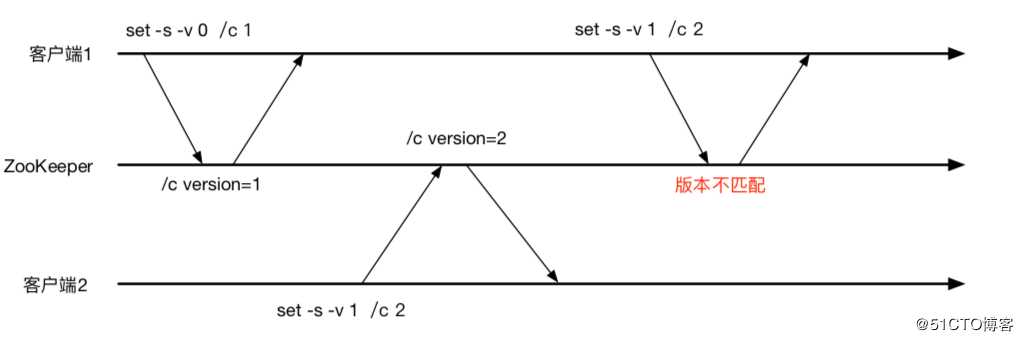
基于版本号的条件更新
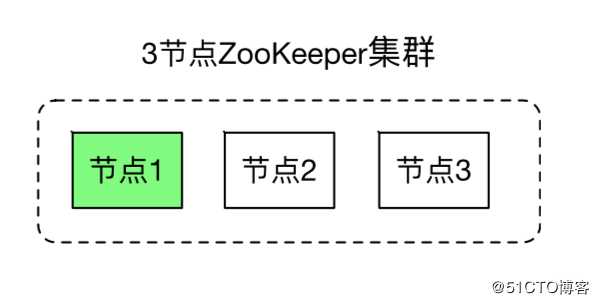
quorum模式要求至少3个节点
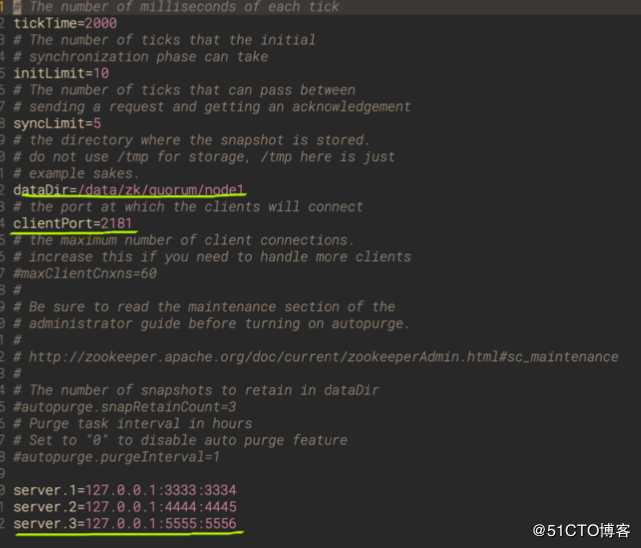
其中2181是默认客户端服务端口,3333是quorum之间的通信,3334是用于leader选举的端口。
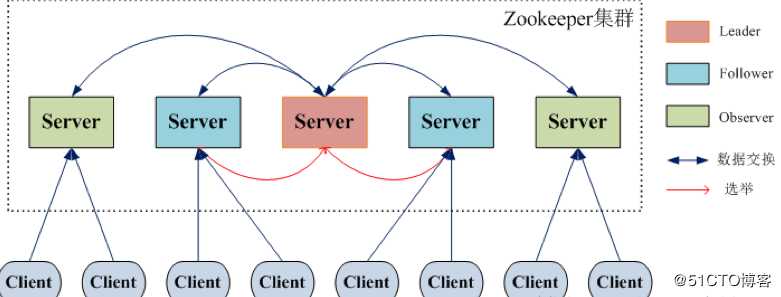
? 可线性化(Linearizable)写入:先到达 leader 的写请求会被先处理,leader 决定写请求的执 行顺序。
? 客户端FIFO顺序:来自给定客户端的请求按照发送顺序执行。
1、2PC,3PC,Paxos,Raft算法
2、ZAB(ZooKeeper Atomic Broadcast)协议
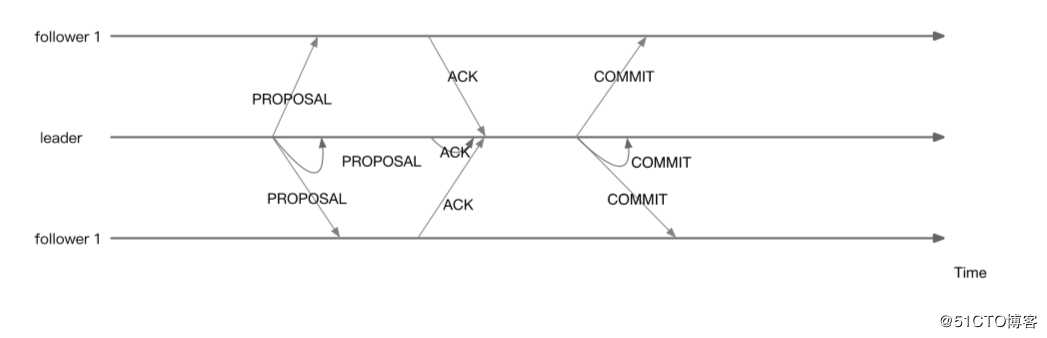
1、Vote投票包含的信息:sid(服务器ID),zxid(事务ID),epoch(leader周期)
2、投票过程
一个ZooKeeper节点通过向所有的节点发送vote开始选举
一个节点在接收到vote之后如果发现接收到的投票新,就把自己的投票更新成最新的投票,并把vote发送给所有的ZooKeeper节点。否则的话,什么也不用做。
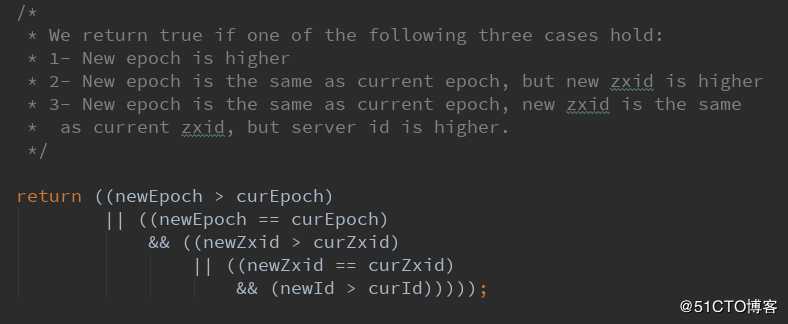
如何判断一个投票是新的?
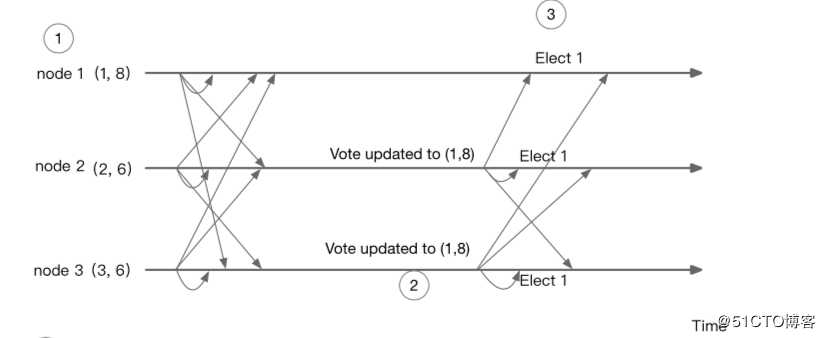
一个3节点集群选举一个leader的时序图:
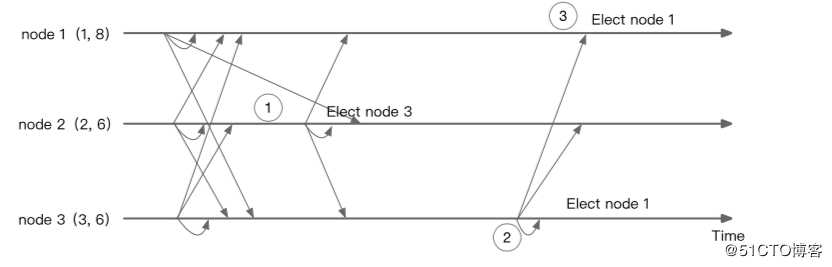
3、脑裂-长时间的消息发送延迟导致选举出两个leader
标签:ima 顺序 kafka集群 work 维护 临时性 时序 共享锁 最小
原文地址:https://blog.51cto.com/janephp/2460812