标签:tar 写代码 如何 chm 参数 pen local 时间 访问
1.通过代码验证集群的配置文件的优先级
1.编写源代码
|
@Test public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统 Configuration configuration = new Configuration(); configuration.set("dfs.replication", "2"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "jinghang");
// 2 上传文件 fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 关闭资源 fs.close();
System.out.println("over"); } |
2.将hdfs-site.xml拷贝到项目的根目录下
|
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
3.参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的默认配置
2.通过代码验证seek指定位置下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "jinghang");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);
// 3 关闭资源
fs.close();
}
3.hdfs的文件的上传、下载流程
1.需求:把本地d盘上的banhua.txt文件上传到HDFS根目录
2.编写代码
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "jinghang");
// 2 创建输入流
FileInputStream fis = new FileInputStream(new File("e:/banhua.txt"));
// 3 获取输出流
FSDataOutputStream fos = fs.create(new Path("/banhua.txt"));
// 4 流对拷
IOUtils.copyBytes(fis, fos, configuration);
// 5 关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
1.需求:从HDFS上下载banhua.txt文件到本地e盘上
2.编写代码
// 文件下载
@Test
public void getFileFromHDFS() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "jinghang");
// 2 获取输入流
FSDataInputStream fis = fs.open(new Path("/banhua.txt"));
// 3 获取输出流
FileOutputStream fos = new FileOutputStream(new File("e:/banhua.txt"));
// 4 流的对拷
IOUtils.copyBytes(fis, fos, configuration);
// 5 关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
4.hdfs的默认副本策略
第一个副本在客户端所处的节点上,如果客户端在集群外,随机选一个
第二个副本和第一个副本位于相同机架上,随机节点
第三个副本位于不同机架,随机节点。
5.nn和2nn的工作机制?2nn有什么作用?
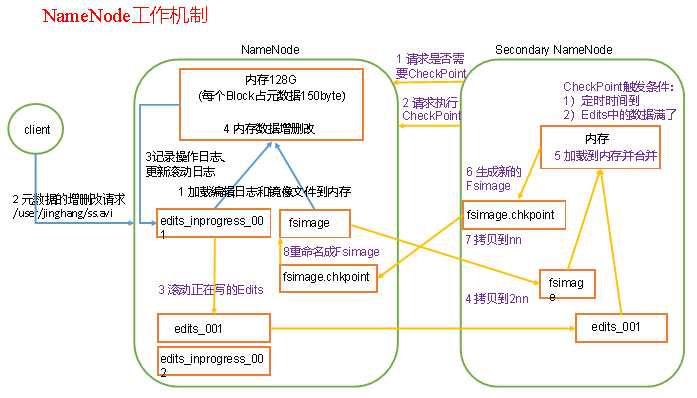
1. 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2. 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
集群的故障处理
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
1. kill -9 NameNode进程
2. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[jinghang@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
3. 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[jinghang@hadoop102 dfs]$ scp -r jinghang@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
4. 重新启动NameNode
[jinghang@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
2. kill -9 NameNode进程
3. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[jinghang@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
4. 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[jinghang@hadoop102 dfs]$ scp -r jinghang@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
[jinghang@hadoop102 namesecondary]$ rm -rf in_use.lock
[jinghang@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[jinghang@hadoop102 dfs]$ ls
data name namesecondary
5. 导入检查点数据(等待一会ctrl+c结束掉)
[jinghang@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint
6. 启动NameNode
[jinghang@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
集群的安全模式
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
案例
模拟等待安全模式
(1)查看当前模式
[jinghang@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -safemode get
Safe mode is OFF
(2)先进入安全模式
[jinghang@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode enter
(3)创建并执行下面的脚本
在/opt/module/hadoop-2.7.2路径上,编辑一个脚本safemode.sh
[jinghang@hadoop102 hadoop-2.7.2]$ touch safemode.sh
[jinghang@hadoop102 hadoop-2.7.2]$ vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-2.7.2/README.txt /
[jinghang@hadoop102 hadoop-2.7.2]$ chmod 777 safemode.sh
[jinghang@hadoop102 hadoop-2.7.2]$ ./safemode.sh
(4)再打开一个窗口,执行
[jinghang@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode leave
(5)观察
(a)再观察上一个窗口
Safe mode is OFF
(b)HDFS集群上已经有上传的数据了。
6.dn的工作机制
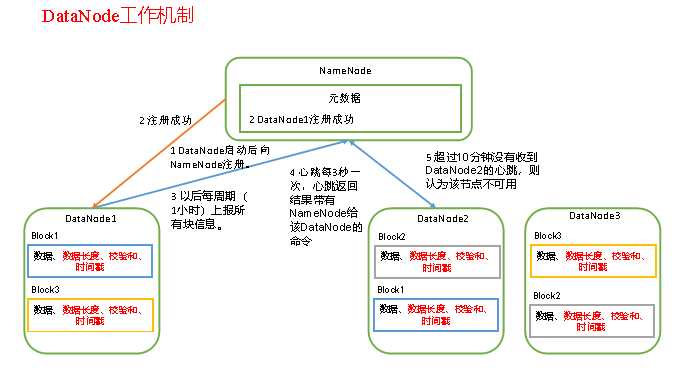
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
7.判断dn的离线
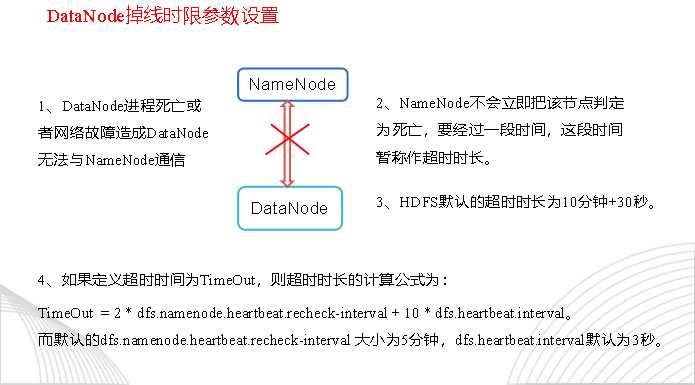
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
8.添加新节点
1. 环境准备
(1)在hadoop104主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称
(3)删除原来HDFS文件系统留存的文件(/opt/module/hadoop-2.7.2/data和log)
(4)source一下配置文件
[jinghang@hadoop105 hadoop-2.7.2]$ source /etc/profile
2. 服役新节点具体步骤
(1)直接启动DataNode,即可关联到集群
[jinghang@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[jinghang@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(2)在hadoop105上上传文件
[jinghang@hadoop105 hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt /
(3)如果数据不均衡,可以用命令实现集群的再平衡
[jinghang@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-jinghang-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
9.什么是白名单?什么是黑名单?如何设置白名单?如何退役旧节点?
在黑名单上面的主机都会被强制退出。
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。
1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[jinghang@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[jinghang@hadoop102 hadoop]$ touch dfs.hosts
[jinghang@hadoop102 hadoop]$ vi dfs.hosts
添加如下主机名称(不添加hadoop105)
hadoop102
hadoop103
hadoop104
(2)在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
(3)配置文件分发
[jinghang@hadoop102 hadoop]$ xsync hdfs-site.xml
(4)刷新NameNode
[jinghang@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
(5)更新ResourceManager节点
[jinghang@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(6)在web浏览器上查看
4. 如果数据不均衡,可以用命令实现集群的再平衡
[jinghang@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-jinghang-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
标签:tar 写代码 如何 chm 参数 pen local 时间 访问
原文地址:https://www.cnblogs.com/lu0420-0412/p/12088129.html