标签:cache 插件 拉取 插件化 doc 网卡 排查 最新版本 数据
点击下载《不一样的 双11 技术:阿里巴巴经济体云原生实践》

作者 | 杨育兵(沈陵) 阿里巴巴高级技术专家
我们从 2016 年开始在集团推广全面的镜像化容器化,今年是集团全面镜像化容器化后的第 4 个 双11,PouchContainer 容器技术已经成为集团所有在线应用运行的运行时底座和运维载体,每年 双11 都有超过百万的 PouchContainer 容器同时在线,提供电商和所有相关的在线应用平稳运行的载体,保障大促购物体验的顺滑。
我们通过 PouchContainer 容器运行时这一层标准构建了应用开发和基础设施团队的标准界面,每年应用都有新的需求、新的变化,同时基础设施也有上云/混部/神龙/存储计算分离/网络变革这些升级,两边平行演进,互不干扰。技术设施和 PouchContainer 自身都做了很大的架构演进,这些很多的架构和技术演进对应用开发者都是无感知的。
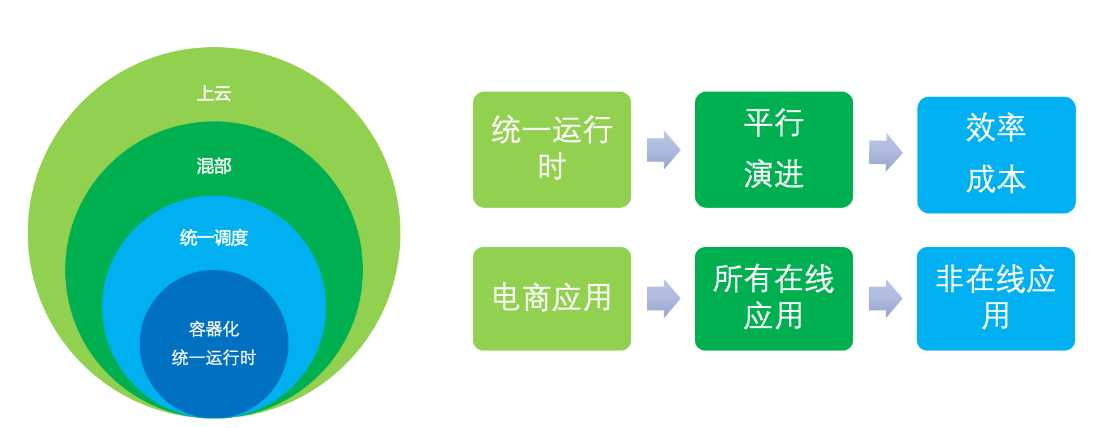
在容器技术加持的云原生形成趋势的今天,PouchContainer 容器技术支持的业务方也不再只有集团电商业务和在线业务了,我们通过标准化的演进,把所有定制功能做了插件化,适配了不同场景的需要。除了集团在线应用,还有运行在离线调度器上面的离线 job 类任务、跑在搜索调度器上面的搜索广告应用、跑在 SAE/CSE 上面的 Serverless 应用、专有云产品及公有云(ACK+CDN)等场景,都使用了 PouchContainer 提供的能力。
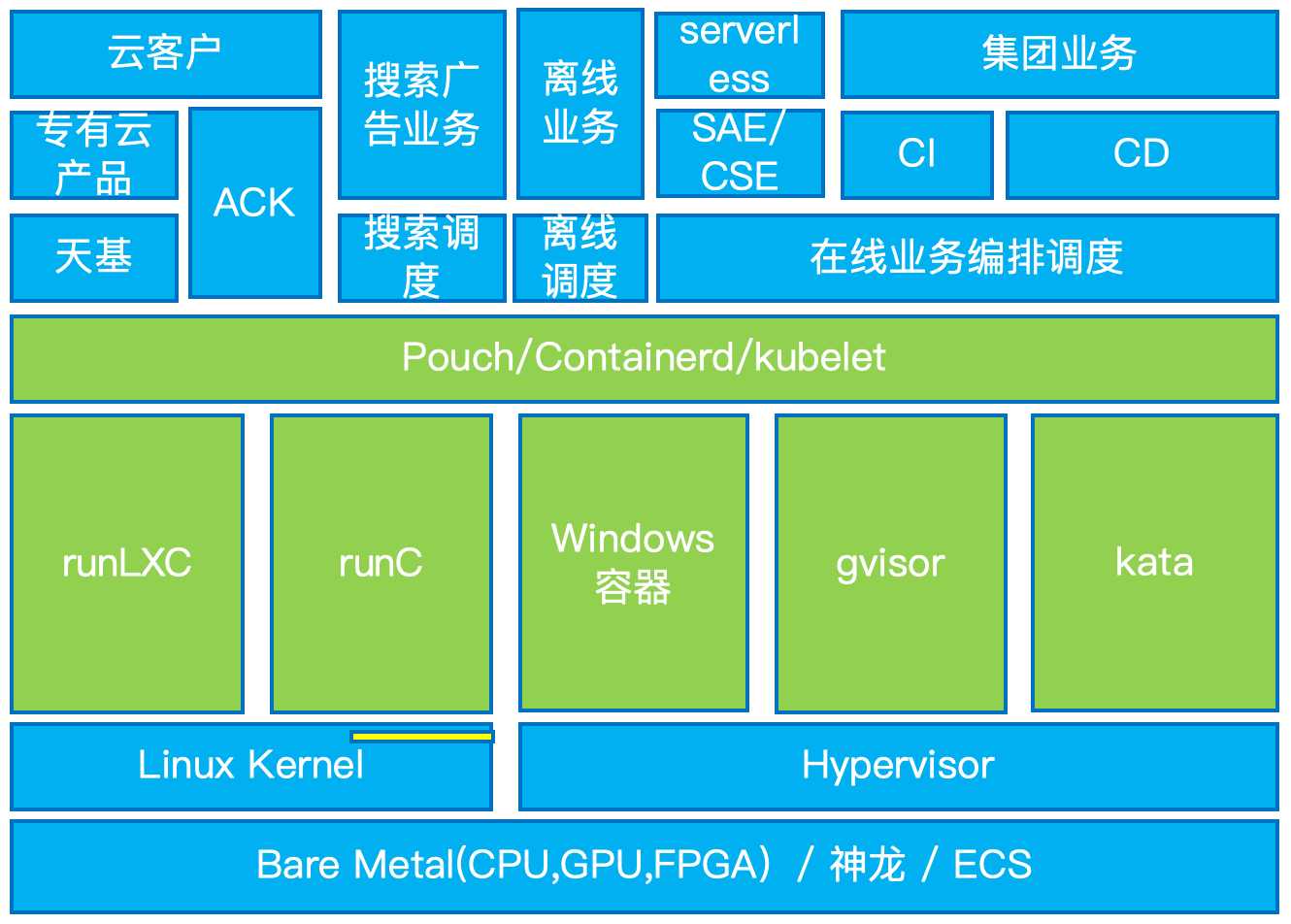
2015 年之前,我们用的运行时是 LXC,PouchContainer 为了在镜像化后能够平滑接管原来的 T4 容器,在 LXC 中支持新的镜像组装方式,并支持交互式的 exec 和内置的网络模式。
随着云原生的进程,我们在用户无感知的情况下对运行时做了 containerd+runc 的支持,用标准化的方式加内部功能插件,实现了内部功能特性的支持和被各种标准化运维系统无缝集成的目标。
无论是 LXC 还是 runc 都是让所有容器共享 Linux 内核,利用 cgroup 和 namespace 来做隔离,对于强安全场景和强隔离场景是不适用的。为了容器这种开发和运维友好的交付形式能给更多场景带来收益,我们很早就开始探索这方面的技术,和集团 os 创新团队以及蚂蚁 os 虚拟化团队合作共建了 kata 安全容器和 gvisor 安全容器技术,在容器生态嫁接,磁盘、网络和系统调用性能优化等方面都做了很多的优化。在兼容性要求高的场景我们优先推广 kata 安全容器,已经支持了 SAE 和 ACK 安全容器场景。在语言和运维习惯确定的场景,我们也在 618 大促时上线了一些合适的电商使用了 gvisor 的运行时隔离技术,稳定性和性能都得到了验证。
为了一部分专有云场景的实施,我们今年还首次支持了 Windows 容器运行时,在容器依赖相关的部署、运维方面做了一些探索,帮助敏捷版专有云拿下了一些客户。
除了安全性和隔离性,我们的运行时演进还保证了标准性,今年最新版本的 PouchContainer 把 diskquota、lxcfs、dragonfly、DADI 这些特性都做成了可插拔的插件,不需要这些功能的场景可以完全不受这些功能代码的影响。甚至我们还对一些场景做了 containerd 发行版,支持纯粹的标准 CRI 接口和丰富的运行时。
镜像化以后必然会引入镜像分发的效率方面的困难,一个是速度另一个是稳定性,让发布扩容流程不增加太多时间的情况下,还要保证中心节点不被压垮。
PouchContainer 在一开始就支持了使用 Dragonfly?来做 P2P 的镜像分发,就是为了应对这种问题,这是我们的第一代镜像分发方案。在研发域我们也对镜像分层的最佳实践做了推广,这样能最大程度的保证基础环境不变时每次下载的镜像层最小。镜像加速要解决的问题有:build 效率、push 效率、pull 效率、解压效率以及组装效率。第一代镜像加速方案,结合 Dockerfile 的最佳实践解决了 build 效率和 pull 效率和中心压力。
第一代镜像分发的缺点是无论用户启动过程中用了多少镜像数据,在启动容器之前就需要把所有的镜像文件都拉到本地,在很多场景下都是浪费的,特别影响的是扩容场景。所以第二代的镜像加速方案,我们调研了阿里云的盘古,盘古的打快照、mount、再打快照这种使用方式完美匹配打镜像和分发的流程;能做到秒级镜像 pull,因为 pull 镜像时只需要鉴权,下载镜像 manifest,然后 mount 盘古,也能做到镜像内容按需读取。
2018 年 双11,我们小规模上线了盘古远程镜像,也验证了我们的设计思路,这一代的镜像加速方案结合新的 overlay2 技术在第一代的基础上又解决了PouchContainer 效率/pull 效率/解压效率和组装效率。
但是也存在一些问题。首先镜像数据没有存储在中心镜像仓库中,只有 manifest 信息,这样镜像的分发范围就受限,在哪个盘古集群做的镜像,就必须在那个盘古集群所在的阿里云集群中使用这个镜像;其次没有 P2P 的能力,在大规模使用时对盘古后端的压力会很大,特别是离线场景下由于内存压力导致很多进程的可执行文件的 page cache 被清理,然后需要重新 load 这种场景,会给盘古后端带来更大的压力。基于这两个原因,我们和 ContainerFS 团队合作共建了第三代镜像分发方案:DADI(基于块设备的按需 P2P 加载技术,后面也有计划开源这个镜像技术)。
DADI 在构建阶段保留了镜像的多层结构,保证了镜像在多次构建过程中的可重用性,并索引了每个文件在每层的offset 和 length,推送阶段还是把镜像推送到中心镜像仓库中,保证在每个机房都能拉取到这个镜像。在每个机房都设置了超级节点做缓存,每一块内容在特定的时间段内,都只从镜像仓库下载一次。如果有时间做镜像预热,像 双11 这种场景,预热阶段就是从中心仓库中把镜像预热到本地机房的超级节点,后面的同机房的数据传输会非常快。镜像 pull 阶段只需要下载镜像的 manifest 文件(通常只有几 K大小),速度非常快,启动阶段 DADI 会给每个容器生成一个块设备,这个块设备的 chunk 读取是按需从超级节点或临近节点 P2P 读取的内容,这样就保证了容器启动阶段节点上只读取了需要的部分内容。为了防止容器运行过程中出现 iohang,我们在容器启动后会在后台把整个镜像的内容全部拉到 node 节点,享受超快速启动的同时最大程度地避免后续可能出现的 iohang。
使用 DADI 镜像技术后的今年 双11 高峰期,每次有人在群里面说有扩容任务,我们值班的同学去看工单时,基本都已经扩容完成了,扩容体验做到了秒级。
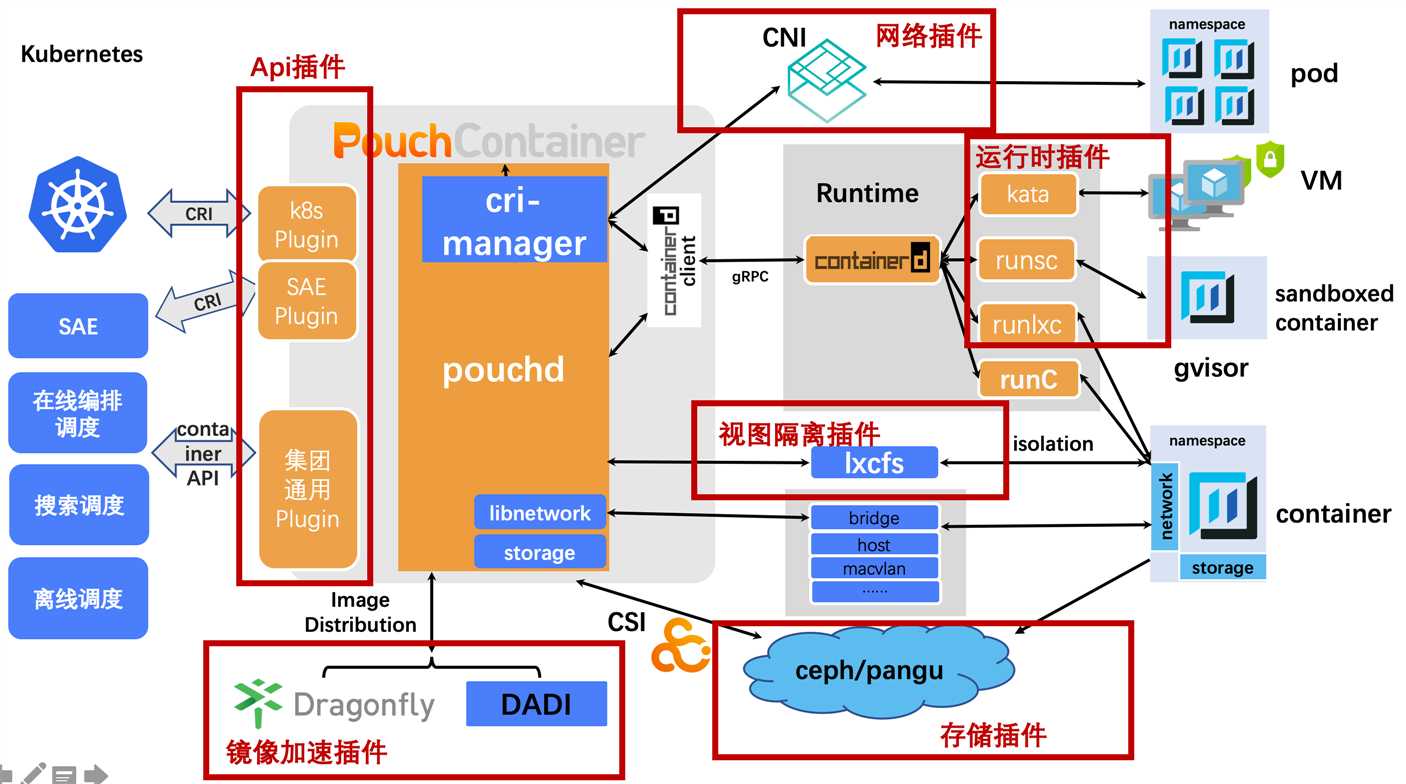
PouchContainer 一开始的网络功能是揉合在 PouchContainer 自己的代码中的,用集成代码的方式支持了集团各个时期的网络架构,为了向标准化和云原生转型,在应用无感知的情况下,我们在 Sigma-2.0 时代使用 libnetwork 把集团现存的各种网络机架构都统一做了 CNM 标准的网络插件,沉淀了集团和专有云都在用的阿里巴巴自己的网络插件。在在线调度系统推广期间,CNM 的网络插件已经不再适用,为了不需要把所有的网络插件再重新实现一遍,我们对原来的网络插件做了包装,沉淀了 CNI 的网络插件,把 CNM 的接口转换为 CNI 的接口标准。
内部的网络插件支持的主流单机网络拓扑演进过程如下图所示:
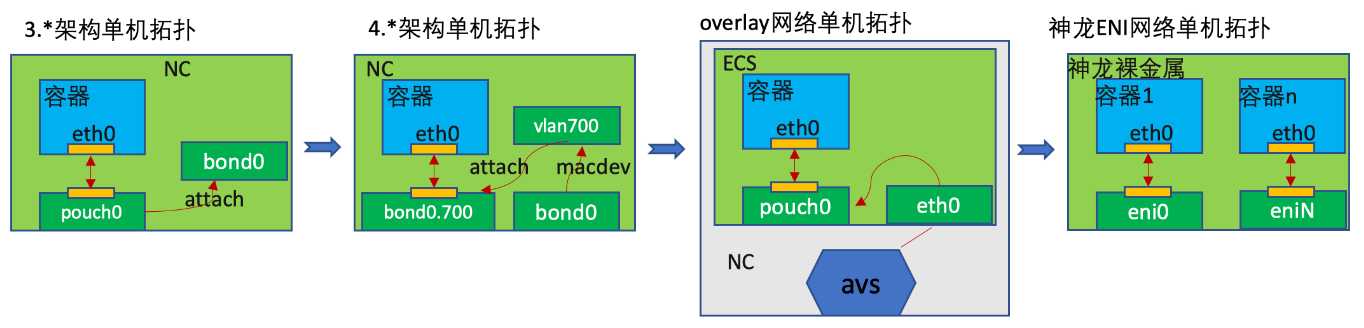
从单机拓扑能看出来使用神龙 eni 网络模式可以避免容器再做网桥转接,但是用神龙的弹性网卡和CNI网络插件时也有坑需要避免,特别是 eni 弹性网卡是扩容容器时才热插上来的情况时。创建 eni 网卡时,udevd 服务会分配一个唯一的 id N,比如 ethN,然后容器 N 启动时会把 ethN 移动到容器 N 的 netns,并从里面改名为 eth0。容器 N 停止时,eth0 会改名为 ethN 并从容器 N 的 netns 中移动到宿主机的 netns 中。
这个过程中,如果容器 N 没有停止时又分配了一个容器和 eni 到这台宿主机上,udevd 由于看不到 ethN 了,它有可能会分配这个新的 eni 的名字为 ethN。容器 N 停止时,把 eth0 改名为 ethN 这一步能成功,但是移动到宿主机根 netns 中这一步由于名字冲突会失败,导致 eni 网卡泄漏,下一次容器 N 启动时找不到它的 eni 了。可以通过修改 udevd 的网卡名字生成规则来避免这个坑。
PouchContainer 容器技术支持了百万级的在线容器同时运行,经常会有一些问题需要我们排查,很多都是已知的问题,为了解决这个困扰,我还写了 PouchContainer 的一千个细节以备用户查询,或者重复问题问过来时直接交给用户。但是 PouchContainer?和相关链路本身稳定性和运维能力的提升才是最优的方法。今年我们建设了 container-debugger 和 NodeOps 中心系统,把一些容器被用户问的问题做自动检测和修复,任何修复都做了灰度筛选和灰度部署能力,把一些经常需要答疑的问题做了用户友好的提示和修复,也减轻了我们自身的运维压力。
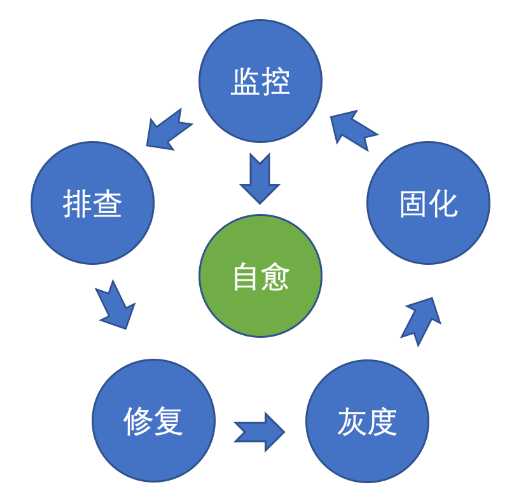
提供容器平台给应用使用,在容器启动之前必然有很多平台相关的逻辑需要处理,这也是我们以前用富容器的原因。
还有一些 agent 不是只做 volume 共享就可以放到 sidecar 的运维容器中的,比如 arthas 需要能 attach 到主容器的进程上去,还要能 load 主容器中非 volume 路径上面的 jar 文件才能正常工作。对于这种场景 PouchContainer 容器也提供了能让同 Pod 多容器做一些 ns 共享的能力,同时配合 ns 穿越来让这些 agent 可以在部署方式和资源隔离上是和主容器分离的,但是在运行过程中还可以做它原来可以做的事情。
可插拔的插件化的架构和更精简的调用链路在容器生态里面还是主流方向,kubelet 可以直接去调用 pouch-containerd 的 CRI 接口,可以减少中间一个组件的远程调用,不过 CRI 接口现在还不够完善,很多运维相关的指令都没有,logs 接口也要依赖于 container API 来实现,还有运行环境和构建环境分离,这样用户就不需要到宿主机上面执行 build。所有的运维系统也不再依赖于 container API。在这些约束下我们可以做到减少对一个中间组件的系统调用,直接用 kubelet 去调用 pouch-containerd 的 CRI 接口。
现在每个应用都有很多的 Dockerifle,怎么让 Dockerfile 更有表达能力,减少 Dockerfile 数量。构建的时候并发构建也是一个优化方向,buildkit 在这方面是可选的方案,Dockerfile 表达能力的欠缺也需要新的解决方案,buildkit 中间态的 LLB 是 go 代码,是不是可以用 go 代码来代替 Dockerfile,定义更强表达能力的 Dockerfile 替代品。
容器化是云原生的关键路径,容器技术在运行时和镜像技术逐渐趋于稳定的情况下,热点和开发者的目光开始向上层转移,K8s 和基于其上的生态成为容器技术未来能产生更多创新的领域,PouchContainer?技术也在向着更云原生、更好适配 K8s 生态的方向发展,网络、diskquota、试图隔离等 PouchContainer?的插件,在 K8s 生态系统中适配和优化也我们后面的方向之一。

本书亮点
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”
PouchContainer 容器技术演进助力阿里云原生升级
标签:cache 插件 拉取 插件化 doc 网卡 排查 最新版本 数据
原文地址:https://www.cnblogs.com/alisystemsoftware/p/12096912.html