标签:规模 ima 经济学 现在 生物信息学 substr div index 用处
Wiki解释
动态规划(英语:Dynamic programming,简称DP)是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
动态规划常常适用于有重叠子问题[1]和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再根据子问题的解以得出原问题的解。
通常许多子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,从而减少计算量:一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个子问题解之时直接查表。这种做法在重复子问题的数目关于输入的规模呈指数增长时特别有用。
动态规划很有用处,尤其是在做算法题的时候?当然它也是最难的,虽然本质是分解问题,但是它是dynamic的。
0-1背包问题
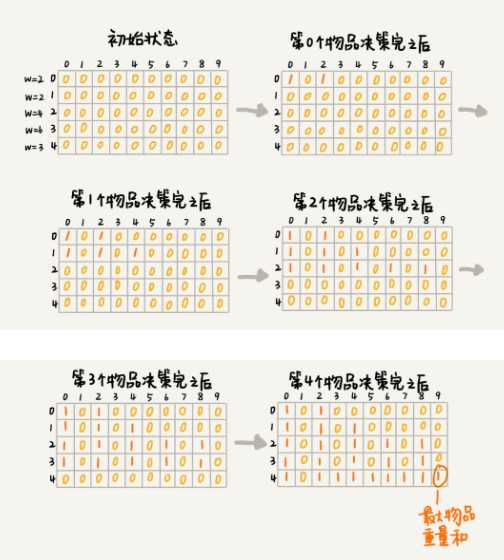
比如现在背包里有5个物品,分别质量w为2,2,4,6,3
我们把每一层重复的状态(节点)合并,只记录不同的状态,然后基于上一层的状态集合,来推导下一层的状态集合。我们可以通过合并每一层重复的状态,这样就保证每一层不同状态的个数都不会超过 w 个(w 表示背包的承载重量),也就是例子中的 9。于是,我们就成功避免了每层状态个数的指数级增长。
我们用一个二维数组 states[n][w+1],来记录每层可以达到的不同状态。
第 0 个(下标从 0 开始编号)物品的重量是 2,要么装入背包,要么不装入背包,决策完之后,会对应背包的两种状态,背包中物品的总重量是 0 或者 2。我们用 states[0][0]=true 和 states[0][2]=true 来表示这两种状态。
第 1 个物品的重量也是 2,基于之前的背包状态,在这个物品决策完之后,不同的状态有 3 个,背包中物品总重量分别是 0(0+0),2(0+2 or 2+0),4(2+2)。我们用 states[1][0]=true,states[1][2]=true,states[1][4]=true 来表示这三种状态。
以此类推,直到考察完所有的物品后,整个 states 状态数组就都计算好了。我把整个计算的过程画了出来,你可以看看。图中 0 表示 false,1 表示 true。我们只需要在最后一层,找一个值为 true 的最接近 w(这里是 9)的值,就是背包中物品总重量的最大值。
代码实现
// weight:物品重量,n:物品个数,w:背包可承载重量 public static int knapsack(int[] weight, int n, int w) { boolean[][] states = new boolean[n][w+1]; // 默认值false states[0][0] = true; // 第一行的数据要特殊处理,可以利用哨兵优化 if (weight[0] <= w) { states[0][weight[0]] = true; } for (int i = 1; i < n; ++i) { // 动态规划状态转移 for (int j = 0; j <= w; ++j) {// 不把第i个物品放入背包 if (states[i-1][j] == true) states[i][j] = states[i-1][j]; } for (int j = 0; j <= w-weight[i]; ++j) {//把第i个物品放入背包 if (states[i-1][j]==true) states[i][j+weight[i]] = true; } } for (int i = w; i >= 0; --i) { // 输出结果 if (states[n-1][i] == true) return i; } return 0; }
看这段代码一定要确保上面的图示明白了。
实际上,这就是一种用动态规划解决问题的思路。我们把问题分解为多个阶段,每个阶段对应一个决策。我们记录每一个阶段可达的状态集合(去掉重复的),然后通过当前阶段的状态集合,来推导下一个阶段的状态集合,动态地往前推进。这也是动态规划这个名字的由来,你可以自己体会一下,是不是还挺形象的?
尽管动态规划的执行效率比较高,但是就刚刚的代码实现来说,我们需要额外申请一个 n 乘以 w+1 的二维数组,对空间的消耗比较多。所以,有时候,我们会说,动态规划是一种空间换时间的解决思路。你可能要问了,有什么办法可以降低空间消耗吗?
标签:规模 ima 经济学 现在 生物信息学 substr div index 用处
原文地址:https://www.cnblogs.com/CherryTab/p/12098634.html