标签:app org raw false webkit tar spider 存储 yourself
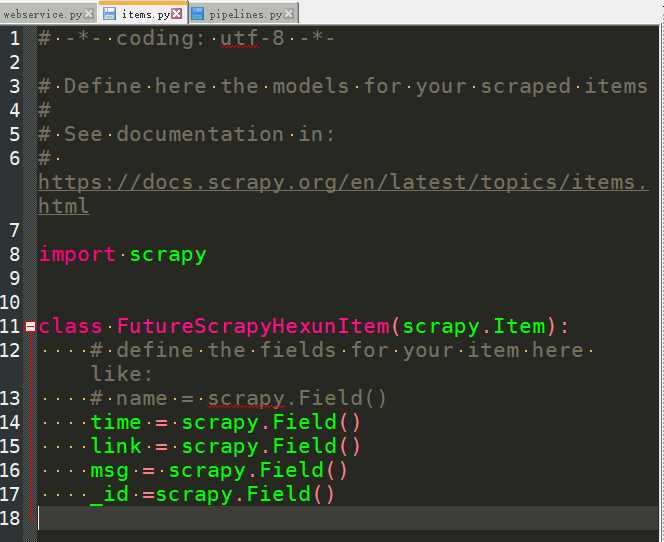

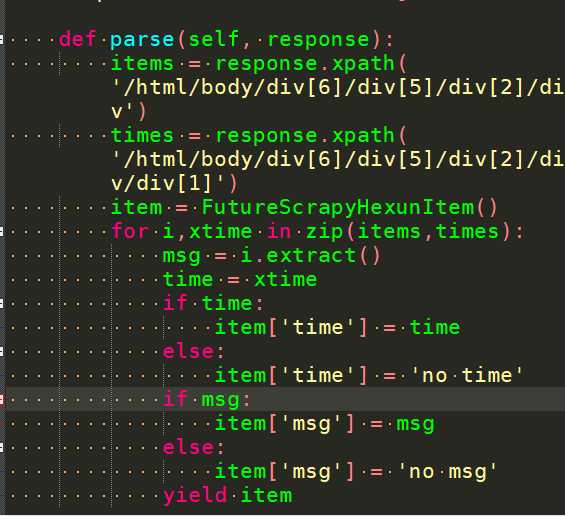
记得修改settings.py文件
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5514.400 QQBrowser/10.1.1660.400‘
2
# Obey robots.txt rules
#不遵守机器人规则 有些它不让去的我们也要去
ROBOTSTXT_OBEY = False
3
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
‘cls.pipelines.ClsPipeline‘: 300,
}
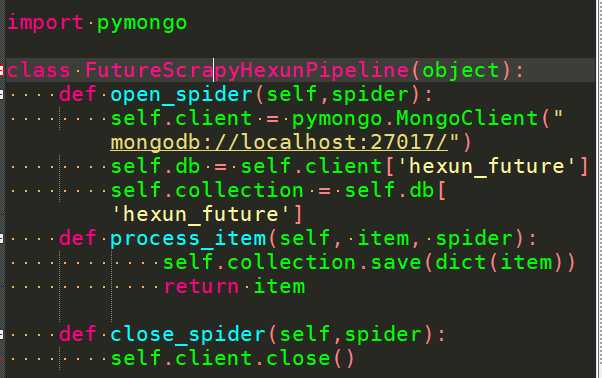
标签:app org raw false webkit tar spider 存储 yourself
原文地址:https://www.cnblogs.com/zhibin123/p/12100922.html