标签:套接字 ssi ack oid || img exp 全双工 address
一、基础知识
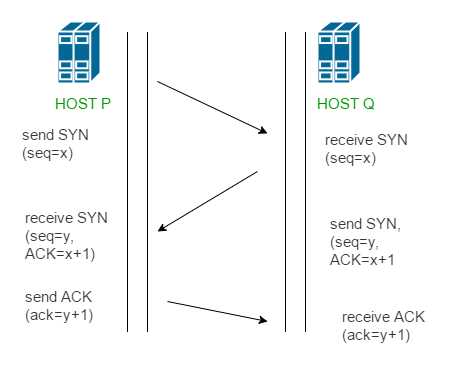
TCP通过称为“主动确认重传”(PAR)的方式提供可靠的通信。传输层的协议数据单元(PDU)称为段。使用PAR的设备重新发送数据单元,直到它收到确认为止。如果接收端接收的数据单元已损坏(使用用于错误检测的传输层的校验和功能检查数据),则接收端将丢弃该段。因此,发送方必须重新发送未收到确认的数据单元。通过上述机制,可以实现在发送方(客户端)和接收方(服务器)之间交换三个段,以建立可靠的TCP连接。这一机制是这样工作的:
步骤1、2建立一个方向的连接参数(序列号),并确认该参数。步骤2、3为另一个方向建立连接参数(序列号),并确认该参数。利用这些,建立了全双工通信。
注–在客户端和服务器之间建立连接时,会随机选择初始序列号。
二、实验过程
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
unsigned long a[AUDITSC_ARGS];
unsigned long a0, a1;
int err;
unsigned int len;
if (call < 1 || call > SYS_SENDMMSG)
return -EINVAL;
call = array_index_nospec(call, SYS_SENDMMSG + 1);
len = nargs[call];
if (len > sizeof(a))
return -EINVAL;
/* copy_from_user should be SMP safe. */
if (copy_from_user(a, args, len))
return -EFAULT;
err = audit_socketcall(nargs[call] / sizeof(unsigned long), a);
if (err)
return err;
a0 = a[0];
a1 = a[1];
switch (call) {
case SYS_SOCKET: #call=1
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND: #call=2
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT: #call=3
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN: #call=4
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT: #call=5
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
case SYS_GETSOCKNAME: #call=6
err =
__sys_getsockname(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_GETPEERNAME: #call=7
err =
__sys_getpeername(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_SOCKETPAIR: #call=8
err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]);
break;
case SYS_SEND: #call=9
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
NULL, 0);
break;
case SYS_SENDTO: #call=10
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4], a[5]);
break;
case SYS_RECV: #call=11
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
NULL, NULL);
break;
case SYS_RECVFROM: #call=12
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4],
(int __user *)a[5]);
break;
case SYS_SHUTDOWN: #call=13
err = __sys_shutdown(a0, a1);
break;
case SYS_SETSOCKOPT: #call=14
err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3],
a[4]);
break;
case SYS_GETSOCKOPT: #call=15
err =
__sys_getsockopt(a0, a1, a[2], (char __user *)a[3],
(int __user *)a[4]);
break;
case SYS_SENDMSG: #call=16
err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_SENDMMSG: #call=17
err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2],
a[3], true);
break;
case SYS_RECVMSG: #call=18
err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_RECVMMSG: #call=19
if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME))
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3],
(struct __kernel_timespec __user *)a[4],
NULL);
else
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3], NULL,
(struct old_timespec32 __user *)a[4]);
break;
case SYS_ACCEPT4: #call=20
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], a[3]);
break;
default:
err = -EINVAL;
break;
}
return err;
在上次实验中,我们发现了sys_socketcall根据传入call的数值决定调用的函数,又根据gdb信息不难定位到__sys_socket,__sys_connect,__sys_listen,__sys_accept4四个函数,因此打开gdb,连接并打断点,如图所示。
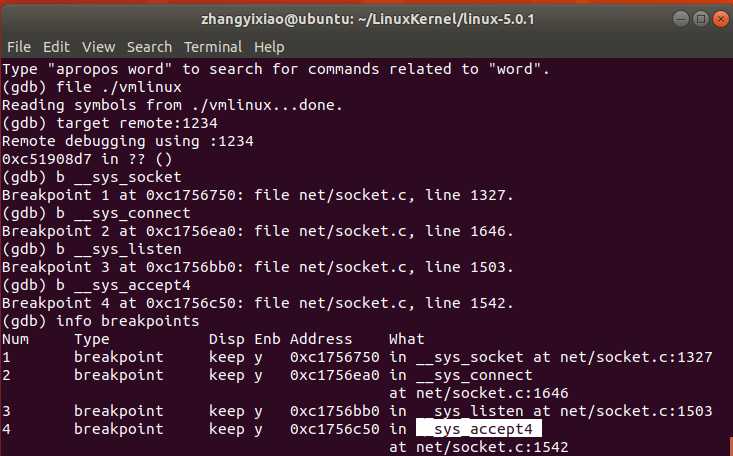
也就是说在这些函数的调用后,我们实现了TCP通信,那么我们接下来就依次看看具体的源代码来看看TCP的三次握手是怎么实现的。
(1)首先是__sys_socket,代码如下
int __sys_socket(int family, int type, int protocol) { int retval; struct socket *sock; int flags; /* Check the SOCK_* constants for consistency. */ BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC); BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK); flags = type & ~SOCK_TYPE_MASK; if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; type &= SOCK_TYPE_MASK; if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; retval = sock_create(family, type, protocol, &sock); if (retval < 0) return retval; return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); }
在这个函数中,主要是调用了sock_create和sock_map_fd函数,找到这两个函数,源码如下:
int sock_create(int family, int type, int protocol, struct socket **res) { return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0); }
调用了__sock_create函数,源码如下:
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; /* * Check protocol is in range */ if (family < 0 || family >= NPROTO) return -EAFNOSUPPORT; if (type < 0 || type >= SOCK_MAX) return -EINVAL; /* Compatibility. This uglymoron is moved from INET layer to here to avoid deadlock in module load. */ if (family == PF_INET && type == SOCK_PACKET) { pr_info_once("%s uses obsolete (PF_INET,SOCK_PACKET)\n", current->comm); family = PF_PACKET; } err = security_socket_create(family, type, protocol, kern); if (err) return err; /* * Allocate the socket and allow the family to set things up. if * the protocol is 0, the family is instructed to select an appropriate * default. */ sock = sock_alloc(); if (!sock) { net_warn_ratelimited("socket: no more sockets\n"); return -ENFILE; /* Not exactly a match, but its the closest posix thing */ } sock->type = type; #ifdef CONFIG_MODULES /* Attempt to load a protocol module if the find failed. * * 12/09/1996 Marcin: But! this makes REALLY only sense, if the user * requested real, full-featured networking support upon configuration. * Otherwise module support will break! */ if (rcu_access_pointer(net_families[family]) == NULL) request_module("net-pf-%d", family); #endif rcu_read_lock(); pf = rcu_dereference(net_families[family]); err = -EAFNOSUPPORT; if (!pf) goto out_release; /* * We will call the ->create function, that possibly is in a loadable * module, so we have to bump that loadable module refcnt first. */ if (!try_module_get(pf->owner)) goto out_release; /* Now protected by module ref count */ rcu_read_unlock(); err = pf->create(net, sock, protocol, kern); if (err < 0) goto out_module_put; /* * Now to bump the refcnt of the [loadable] module that owns this * socket at sock_release time we decrement its refcnt. */ if (!try_module_get(sock->ops->owner)) goto out_module_busy; /* * Now that we‘re done with the ->create function, the [loadable] * module can have its refcnt decremented */ module_put(pf->owner); err = security_socket_post_create(sock, family, type, protocol, kern); if (err) goto out_sock_release; *res = sock; return 0; out_module_busy: err = -EAFNOSUPPORT; out_module_put: sock->ops = NULL; module_put(pf->owner); out_sock_release: sock_release(sock); return err; out_release: rcu_read_unlock(); goto out_sock_release; }
struct socket *sock_alloc(void) { struct inode *inode; struct socket *sock; inode = new_inode_pseudo(sock_mnt->mnt_sb); if (!inode) return NULL; sock = SOCKET_I(inode); inode->i_ino = get_next_ino(); inode->i_mode = S_IFSOCK | S_IRWXUGO; inode->i_uid = current_fsuid(); inode->i_gid = current_fsgid(); inode->i_op = &sockfs_inode_ops; return sock; } EXPORT_SYMBOL(sock_alloc);
可以看到,调用了sock_alloc函数初始化socket的相关信息。
sock_map_fd()主要用于对socket的*file指针初始化,经过sock_map_fd()操作后,socket就通过其*file指针与VFS管理的文件进行了关联,便可以进行文件的各种操作,如read、write、lseek、ioctl等.
static int sock_map_fd(struct socket *sock, int flags) { struct file *newfile; int fd = get_unused_fd_flags(flags); if (unlikely(fd < 0)) { sock_release(sock); return fd; } newfile = sock_alloc_file(sock, flags, NULL); if (likely(!IS_ERR(newfile))) { fd_install(fd, newfile); return fd; } put_unused_fd(fd); return PTR_ERR(newfile); }
(2)其次是__sys_connect,源码如下
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; //获得socket sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out;
//将地址移动到内核空间 err = move_addr_to_kernel(uservaddr, addrlen, &address); if (err < 0) goto out_put; err = security_socket_connect(sock, (struct sockaddr *)&address, addrlen); if (err) goto out_put; err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags);
//对于流式套接字,sock->ops为 inet_stream_ops -->inet_stream_connect
//对于数据报套接字,sock->ops为 inet_dgram_ops --> inet_dgram_connect
out_put: fput_light(sock->file, fput_needed); out: return err; }
由于我们时TCP协议,采用的肯定是流的形式,继续看inet_stream_connect,在gdb中打断点,找到inet_stream_connec的定义:
int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags) { int err; lock_sock(sock->sk); err = __inet_stream_connect(sock, uaddr, addr_len, flags, 0); release_sock(sock->sk); return err; }
采用锁保证操作的原子性,调用的__inet_stream_connect函数源码:
int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
int err;
lock_sock(sock->sk);
err = __inet_stream_connect(sock, uaddr, addr_len, flags);
release_sock(sock->sk);
return err;
}
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
struct sock *sk = sock->sk;
int err;
long timeo;
if (addr_len < sizeof(uaddr->sa_family))
return -EINVAL;
if (uaddr->sa_family == AF_UNSPEC) {
err = sk->sk_prot->disconnect(sk, flags);
sock->state = err ? SS_DISCONNECTING : SS_UNCONNECTED;
goto out;
}
//判断socket状态
switch (sock->state) {
default:
err = -EINVAL;
goto out;
case SS_CONNECTED:
err = -EISCONN;
goto out;
case SS_CONNECTING:
err = -EALREADY;
/* Fall out of switch with err, set for this state */
break;
case SS_UNCONNECTED://未建立连接,因此发起连接走的是这个流程
err = -EISCONN;
if (sk->sk_state != TCP_CLOSE)
goto out;
//主处理函数,最终调用的是tcp_v4_connect()函数
err = sk->sk_prot->connect(sk, uaddr, addr_len);
if (err < 0)
goto out;
sock->state = SS_CONNECTING;
/* Just entered SS_CONNECTING state; the only
* difference is that return value in non-blocking
* case is EINPROGRESS, rather than EALREADY.
*/
//如果是非阻塞调用,那么最后返回的就是这个错误码
err = -EINPROGRESS;
break;
}
//如果connect设置的是非阻塞,获取超时时间
//超时时间可以通过SO_SNDTIMEO选项设置
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
int writebias = (sk->sk_protocol == IPPROTO_TCP) &&
tcp_sk(sk)->fastopen_req &&
tcp_sk(sk)->fastopen_req->data ? 1 : 0;
/* Error code is set above */
//非阻塞时,timeo为0,直接返回;否则设置定时器,然后调度出去,等待超时返回
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))
goto out;
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
}
...
}
该函数的作用是判断socket的状态,根据状态判断做出动作,sk->sk_prot指向tcp_prot,因此sk->sk_prot->connect最终调用的就是tcp_v4_connect()。
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; struct inet_sock *inet = inet_sk(sk); struct tcp_sock *tp = tcp_sk(sk); __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4; struct rtable *rt; int err; struct ip_options_rcu *inet_opt; ... nexthop = daddr = usin->sin_addr.s_addr;//赋值下一跳地址和目的地址, inet_opt = rcu_dereference_protected(inet->inet_opt, sock_owned_by_user(sk)); if (inet_opt && inet_opt->opt.srr) { if (!daddr) return -EINVAL; nexthop = inet_opt->opt.faddr; } orig_sport = inet->inet_sport;//源地址 orig_dport = usin->sin_port;//源端口 fl4 = &inet->cork.fl.u.ip4; //根据当前信息,查找路由,并新建路由缓存 rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); ... if (!inet->inet_saddr) //如果socket没有绑定ip地址,使用路由查询返回的结果 inet->inet_saddr = fl4->saddr; //inet_rcv_saddr表示的是本地绑定的ip地址,也就是源地址 inet->inet_rcv_saddr = inet->inet_saddr; if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { /* Reset inherited state */ tp->rx_opt.ts_recent = 0; tp->rx_opt.ts_recent_stamp = 0; if (likely(!tp->repair)) tp->write_seq = 0; } if (tcp_death_row.sysctl_tw_recycle && !tp->rx_opt.ts_recent_stamp && fl4->daddr == daddr) tcp_fetch_timewait_stamp(sk, &rt->dst); inet->inet_dport = usin->sin_port;//目的端口 inet->inet_daddr = daddr;//目的地址 inet_csk(sk)->icsk_ext_hdr_len = 0; if (inet_opt) inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; tcp_set_state(sk, TCP_SYN_SENT);//socket进入SYN-SENT状态 //绑定ip和端口号,并将sock加入哈希表中 err = inet_hash_connect(&tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); //使用新的端口号再次做路由查询, //因为如果客户端没有用bind()绑定IP地址和端口号,上面inet_hash_connect() //就会自动选择一个端口号,因此源端口会不一样 rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure; } /* OK, now commit destination to socket. */ sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); if (!tp->write_seq && likely(!tp->repair)) //生成序列号 tp->write_seq = secure_tcp_sequence_number(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port); inet->inet_id = tp->write_seq ^ jiffies; //由socket层转入TCP层,构造SYN报文并发送 err = tcp_connect(sk); ... }
客户端自动发起连接,至此第一步完成。
在分析connect()系统调用时,我们已经发送SYN报文,所以服务端就需要作出回应了,SYN报文到达TCP层由tcp_v4_rcv()接管。
int tcp_v4_rcv(struct sk_buff *skb) { const struct iphdr *iph; const struct tcphdr *th; struct sock *sk; int ret; struct net *net = dev_net(skb->dev); ... //checksum检查,其实也就是完整性校验 if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; th = tcp_hdr(skb);//获取TCP头部 iph = ip_hdr(skb);//获取ip头部 TCP_SKB_CB(skb)->seq = ntohl(th->seq); TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4); TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq); TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th); TCP_SKB_CB(skb)->tcp_tw_isn = 0; TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph); TCP_SKB_CB(skb)->sacked = 0; //根据报文的源和目的地址在established哈希表以及listen哈希表中查找连接 //对于正要建立的连接,返回的就是listen哈希表的连接 sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest); if (!sk) goto no_tcp_socket; process: //如果此时socket状态处于time_wait,那就进入对应的处理流程中 if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; ... th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); sk_mark_napi_id(sk, skb);//记录napi的id skb->dev = NULL; bh_lock_sock_nested(sk); tcp_sk(sk)->segs_in += max_t(u16, 1, skb_shinfo(skb)->gso_segs); ret = 0; if (!sock_owned_by_user(sk)) {//如果sk没有被用户锁定,即没在使用 //检查是否需要先进入prequeue队列 if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb);//进入到主处理函数 //如果用户正在使用,则数据包进入backlog中 //不太理解的是为什么limit入参是sk_rcvbuf和sk_sndbuf之和 } else if (unlikely(sk_add_backlog(sk, skb, sk->sk_rcvbuf + sk->sk_sndbuf))) { bh_unlock_sock(sk); NET_INC_STATS_BH(net, LINUX_MIB_TCPBACKLOGDROP); goto discard_and_relse; } bh_unlock_sock(sk); sock_put(sk); return ret; ... do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { inet_twsk_put(inet_twsk(sk)); goto discard_it; } if (skb->len < (th->doff << 2)) { inet_twsk_put(inet_twsk(sk)); goto bad_packet; } if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } //处理在time_wait状态收到报文的情况 switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev), &tcp_hashinfo, iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb)); if (sk2) { inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row); inet_twsk_put(inet_twsk(sk)); sk = sk2; goto process; } /* Fall through to ACK */ } case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; case TCP_TW_RST: tcp_v4_send_reset(sk, skb); inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row); inet_twsk_put(inet_twsk(sk)); goto discard_it; case TCP_TW_SUCCESS:; } goto discard_it; }
接收到SYN包后要查看下该报文是否之前已建立的连接,通过__inet_lookup_skb()查找是否有匹配的连接。
static inline struct sock *__inet_lookup_skb(struct inet_hashinfo *hashinfo, struct sk_buff *skb, const __be16 sport, const __be16 dport) { //sk_buff结构体里有一个变量指向sock,即skb->sk //但是对于尚未建立连接的skb来说,其sk变量为空,因此会走进__inet_lookup() struct sock *sk = skb_steal_sock(skb); const struct iphdr *iph = ip_hdr(skb); if (sk) return sk; else return __inet_lookup(dev_net(skb_dst(skb)->dev), hashinfo, iph->saddr, sport, iph->daddr, dport, inet_iif(skb)); } static inline struct sock *__inet_lookup(struct net *net, struct inet_hashinfo *hashinfo, const __be32 saddr, const __be16 sport, const __be32 daddr, const __be16 dport, const int dif) { u16 hnum = ntohs(dport); //查找established哈希表 struct sock *sk = __inet_lookup_established(net, hashinfo, saddr, sport, daddr, hnum, dif); //查找listen哈希表 return sk ? : __inet_lookup_listener(net, hashinfo, saddr, sport, daddr, hnum, dif); }
最终会在listen哈希表中找到该连接,也就是服务端的监听socket。
之后如果当前这个监听socket没有被使用,就会进入prequeue队列中处理,但是由于这是SYN报文,还没有进程接收数据,所以不会进入prequeue的真正处理中。
bool tcp_prequeue(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); //如果设置了/proc/sys/net/ipv4/tcp_low_latency(低时延)参数,默认为0 //或者用户还没有调用接收函数接收数据,那么不使用prequeue队列 //ucopy.task会在接收数据函数recvmsg()中设置为接收数据的当前进程 //所以对于第一个SYN报文,会从以下分支返回 if (sysctl_tcp_low_latency || !tp->ucopy.task) return false; if (skb->len <= tcp_hdrlen(skb) && skb_queue_len(&tp->ucopy.prequeue) == 0) return false; if (likely(sk->sk_rx_dst)) skb_dst_drop(skb); else skb_dst_force_safe(skb); //加入到prequeue队列尾部 __skb_queue_tail(&tp->ucopy.prequeue, skb); tp->ucopy.memory += skb->truesize; //如果prequeue队列长度大于socket连接的接收缓冲区, //将prequeue中的数据报文转移到receive_queue中 if (tp->ucopy.memory > sk->sk_rcvbuf) { struct sk_buff *skb1; BUG_ON(sock_owned_by_user(sk)); //从prequeue中摘链 while ((skb1 = __skb_dequeue(&tp->ucopy.prequeue)) != NULL) { sk_backlog_rcv(sk, skb1);//放入backlog中 NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPPREQUEUEDROPPED); } tp->ucopy.memory = 0; //如果prequeue中有报文了,那么唤醒睡眠的进程来收取报文 } else if (skb_queue_len(&tp->ucopy.prequeue) == 1) { //唤醒sk上睡眠的进程,这里只唤醒其中一个,避免惊群现象 //至于怎么唤醒,选择哪个唤醒,暂未研究 wake_up_interruptible_sync_poll(sk_sleep(sk), POLLIN | POLLRDNORM | POLLRDBAND); //没有ACK需要发送,重置延时ACK定时器 if (!inet_csk_ack_scheduled(sk)) inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK, (3 * tcp_rto_min(sk)) / 4, TCP_RTO_MAX); } return true; }
既然不会进入到prequeue队列中,那就进入tcp_v4_do_rcv()的处理,这是个主要的报文处理函数。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
...
//SYN报文走的是这里
if (sk->sk_state == TCP_LISTEN) {
//查找对应的半连接状态的socket
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
//可知,对于SYN报文,返回的还是入参sk,即nsk=sk
if (nsk != sk) {
sock_rps_save_rxhash(nsk, skb);
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
//这里是除ESTABLISHED and TIME_WAIT状态外报文的归宿。。。
if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
return 0;
...
}
半连接状态socket通过tcp_v4_hnd_req()查找。
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
struct tcphdr *th = tcp_hdr(skb);
const struct iphdr *iph = ip_hdr(skb);
struct sock *nsk;
struct request_sock **prev;
/* Find possible connection requests. */
//查找半连接队列,对于SYN报文肯定找不到
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source,
iph->saddr, iph->daddr);
if (req)
return tcp_check_req(sk, skb, req, prev, false);
//再一次查找established哈希表,以防在此期间重传过SYN报文且建立了连接
//对于SYN报文这里也是返回空的
nsk = inet_lookup_established(sock_net(sk), &tcp_hashinfo, iph->saddr,
th->source, iph->daddr, th->dest, inet_iif(skb));
if (nsk) {
if (nsk->sk_state != TCP_TIME_WAIT) {
bh_lock_sock(nsk);
return nsk;
}
inet_twsk_put(inet_twsk(nsk));
return NULL;
}
#ifdef CONFIG_SYN_COOKIES
if (!th->syn)
sk = cookie_v4_check(sk, skb, &(IPCB(skb)->opt));
#endif
//所以最终返回的还是原来的连接,即该函数对于SYN报文啥都没做
return sk;
}
加入半连接队列通过icsk->icsk_af_ops->conn_request操作。我们知道icsk->icsk_af_ops指向ipv4_specific。
const struct inet_connection_sock_af_ops ipv4_specific = { .queue_xmit = ip_queue_xmit, .send_check = tcp_v4_send_check, .rebuild_header = inet_sk_rebuild_header, .sk_rx_dst_set = inet_sk_rx_dst_set, .conn_request = tcp_v4_conn_request, ... };
所以加入半连接的操作就是由tcp_v4_conn_request()操作。
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) { /* Never answer to SYNs send to broadcast or multicast */ if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST)) goto drop; return tcp_conn_request(&tcp_request_sock_ops, &tcp_request_sock_ipv4_ops, sk, skb); drop: NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS); return 0; }
tcp_v4_conn_request()对tcp_conn_request()做了一个简单的封装。
int tcp_conn_request(struct request_sock_ops *rsk_ops, const struct tcp_request_sock_ops *af_ops, struct sock *sk, struct sk_buff *skb) { struct tcp_options_received tmp_opt; struct request_sock *req; struct tcp_sock *tp = tcp_sk(sk); struct dst_entry *dst = NULL; __u32 isn = TCP_SKB_CB(skb)->tcp_tw_isn; bool want_cookie = false, fastopen; struct flowi fl; struct tcp_fastopen_cookie foc = { .len = -1 }; int err; //如果开启了syncookies选项,/proc/sys/net/ipv4/ if ((sysctl_tcp_syncookies == 2 || //或者此时半连接队列已经满了 //同时isn不是由tcp_timewait_state_process()函数选择 //那么判断是否需要发送syncookie inet_csk_reqsk_queue_is_full(sk)) && !isn) { want_cookie = tcp_syn_flood_action(sk, skb, rsk_ops->slab_name); //不需要发送syncookies就直接丢弃报文 if (!want_cookie) goto drop; } //如果全连接队列满了,同时半连接队列里尚未重传过的SYN报文个数大于1 //那么就直接丢弃报文 if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS); goto drop; } //都没问题的话,那就分配一个request_sock,表示一个请求 //这个内存分配是从tcp的slab中分配的 req = inet_reqsk_alloc(rsk_ops); if (!req) goto drop; inet_rsk(req)->ireq_family = sk->sk_family; //af_ops即为tcp_request_sock_ipv4_ops,这个结构体比较重要,请留意 tcp_rsk(req)->af_specific = af_ops; tcp_clear_options(&tmp_opt); tmp_opt.mss_clamp = af_ops->mss_clamp; tmp_opt.user_mss = tp->rx_opt.user_mss; //分析该请求的tcp各个选项,比如时间戳、窗口大小、快速开启等选项 tcp_parse_options(skb, &tmp_opt, 0, want_cookie ? NULL : &foc); if (want_cookie && !tmp_opt.saw_tstamp) tcp_clear_options(&tmp_opt); tmp_opt.tstamp_ok = tmp_opt.saw_tstamp;//记录时间戳选项开启情况 //将刚才分析的请求的TCP选项记录到刚刚分配的request_sock中,即req中 tcp_openreq_init(req, &tmp_opt, skb); af_ops->init_req(req, sk, skb); if (security_inet_conn_request(sk, skb, req)) goto drop_and_free; //如果不需要发送syncookies //同时isn不是由tcp_timewait_state_process()函数选择 if (!want_cookie && !isn) { //如果开启了time_wait状态连接快速回收 //即设置/proc/sys/net/ipv4/tcp_tw_recycle if (tcp_death_row.sysctl_tw_recycle) { bool strict; //查找路由 dst = af_ops->route_req(sk, &fl, req, &strict); if (dst && strict && //主要用于判断是否会和该IP的旧连接冲突 //这里就涉及到nat环境下丢包的问题 !tcp_peer_is_proven(req, dst, true, tmp_opt.saw_tstamp)) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED); goto drop_and_release; } } /* Kill the following clause, if you dislike this way. */ //如果没有开启syncookies选项 else if (!sysctl_tcp_syncookies && //同时,半连接队列长度已经大于syn backlog队列的3/4 (sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) < (sysctl_max_syn_backlog >> 2)) && //并且当前连接和旧连接有冲突 !tcp_peer_is_proven(req, dst, false, tmp_opt.saw_tstamp)) { //很有可能遭受synflood 攻击 pr_drop_req(req, ntohs(tcp_hdr(skb)->source), rsk_ops->family); goto drop_and_release; } //生成随机报文序列号 isn = af_ops->init_seq(skb); } if (!dst) { dst = af_ops->route_req(sk, &fl, req, NULL); if (!dst) goto drop_and_free; } tcp_ecn_create_request(req, skb, sk, dst); //如果要发送syncookies,那就发送 if (want_cookie) { isn = cookie_init_sequence(af_ops, sk, skb, &req->mss); req->cookie_ts = tmp_opt.tstamp_ok; if (!tmp_opt.tstamp_ok) inet_rsk(req)->ecn_ok = 0; } tcp_rsk(req)->snt_isn = isn; tcp_openreq_init_rwin(req, sk, dst); fastopen = !want_cookie && tcp_try_fastopen(sk, skb, req, &foc, dst); //这里便是调用tcp_v4_send_synack()发送SYNACK报文了 err = af_ops->send_synack(sk, dst, &fl, req, skb_get_queue_mapping(skb), &foc); if (!fastopen) { if (err || want_cookie) goto drop_and_free; tcp_rsk(req)->listener = NULL; //发送报文后将该请求加入半连接队列,同时启动SYNACK定时器 //调用inet_csk_reqsk_queue_hash_add()完成上述操作 af_ops->queue_hash_add(sk, req, TCP_TIMEOUT_INIT); } return 0; ... }
要加入半连接队列首先要创建一个request_sock,用于表示客户端发起的请求,然后是做一些初始化,其中req->ts_recent后续会用到多次,这个变量表示的就是对端发送报文的时间(前提是对端开启了时间戳选项)。
static inline void tcp_openreq_init(struct request_sock *req, struct tcp_options_received *rx_opt, struct sk_buff *skb) { struct inet_request_sock *ireq = inet_rsk(req); req->rcv_wnd = 0; /* So that tcp_send_synack() knows! */ req->cookie_ts = 0; tcp_rsk(req)->rcv_isn = TCP_SKB_CB(skb)->seq; tcp_rsk(req)->rcv_nxt = TCP_SKB_CB(skb)->seq + 1; tcp_rsk(req)->snt_synack = tcp_time_stamp; tcp_rsk(req)->last_oow_ack_time = 0; req->mss = rx_opt->mss_clamp; //如果对端开启时间戳,那么记录下这个时间,也就是对方发送SYN报文的时间 req->ts_recent = rx_opt->saw_tstamp ? rx_opt->rcv_tsval : 0; ireq->tstamp_ok = rx_opt->tstamp_ok;//时间戳开启标志 ireq->sack_ok = rx_opt->sack_ok; ireq->snd_wscale = rx_opt->snd_wscale; ireq->wscale_ok = rx_opt->wscale_ok; ireq->acked = 0; ireq->ecn_ok = 0; ireq->ir_rmt_port = tcp_hdr(skb)->source; //目的端口,也就是当前服务端的监听端口 ireq->ir_num = ntohs(tcp_hdr(skb)->dest); }
初始化完这个请求后就要看下这个请求是否有问题。主要检查的就是看是否会和当前ip的上次通讯有冲突。该操作通过tcp_peer_is_proven()检查。
#define TCP_PAWS_MSL 60 /* Per-host timestamps are invalidated * after this time. It should be equal * (or greater than) TCP_TIMEWAIT_LEN * to provide reliability equal to one * provided by timewait state. */ #define TCP_PAWS_WINDOW 1 /* Replay window for per-host * timestamps. It must be less than * minimal timewait lifetime. */ bool tcp_peer_is_proven(struct request_sock *req, struct dst_entry *dst, bool paws_check, bool timestamps) { struct tcp_metrics_block *tm; bool ret; if (!dst) return false; rcu_read_lock(); tm = __tcp_get_metrics_req(req, dst); if (paws_check) { //如果当前ip的上次tcp通讯发生在60s内 if (tm && (u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL && //同时当前ip上次tcp通信的时间戳大于本次tcp,或者没有开启时间戳开关 //从这里看,快速回收打开选项就很容易导致nat环境丢包 ((s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW ||!timestamps)) ret = false; else ret = true; } else { if (tm && tcp_metric_get(tm, TCP_METRIC_RTT) && tm->tcpm_ts_stamp) ret = true; else ret = false; } rcu_read_unlock(); return ret; }
SYNACK报文就是通过tcp_v4_send_synack()发送。
static int tcp_v4_send_synack(struct sock *sk, struct dst_entry *dst, struct flowi *fl, struct request_sock *req, u16 queue_mapping, struct tcp_fastopen_cookie *foc) { const struct inet_request_sock *ireq = inet_rsk(req); struct flowi4 fl4; int err = -1; struct sk_buff * skb; //获取路由 if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL) return -1; //准备synack报文,该报文使用的是用户的send buffer内存 skb = tcp_make_synack(sk, dst, req, foc); if (skb) { __tcp_v4_send_check(skb, ireq->ir_loc_addr, ireq->ir_rmt_addr); skb_set_queue_mapping(skb, queue_mapping); //传到IP层继续处理,组建ip头,然后发送报文 err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr, ireq->ir_rmt_addr, ireq->opt); err = net_xmit_eval(err); } return err; }
发送完SYNACK报文,接着就是将该连接放入半连接队列了,同时启动我们的SYNACK定时器。这一动作通过af_ops->queue_hash_add实现,由上面结构体可知,也就是调用inet_csk_reqsk_queue_hash_add()。
void inet_csk_reqsk_queue_hash_add(struct sock *sk, struct request_sock *req, unsigned long timeout) { struct inet_connection_sock *icsk = inet_csk(sk); struct listen_sock *lopt = icsk->icsk_accept_queue.listen_opt; const u32 h = inet_synq_hash(inet_rsk(req)->ir_rmt_addr, inet_rsk(req)->ir_rmt_port, lopt->hash_rnd, lopt->nr_table_entries); //添加到半连接队列 reqsk_queue_hash_req(&icsk->icsk_accept_queue, h, req, timeout); //更新半连接队列统计信息,同时开启SYNACK定时器 inet_csk_reqsk_queue_added(sk, timeout); }
剩下的工作就是将报文封装到ip层,由网卡发出。
随着SYNACK报文的发送,连接建立随着第二次握手报文来到客户端。客户端接收到这个SYNACK报文,就认为连接建立了。仍然从TCP层开始分析,依然是由tcp_v4_rcv()入手。
int tcp_v4_rcv(struct sk_buff *skb) { ... //根据报文的源和目的地址在established哈希表以及listen哈希表中查找连接 //由于之前调用connect时已经将连接加入到established哈希表中 //所以在接收到服务端的SYNACK时,就能从established表中找到对应的连接 sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest); if (!sk) goto no_tcp_socket; ... ret = 0; if (!sock_owned_by_user(sk)) {//如果sk没有被用户锁定,及没在使用 if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb);//进入到主处理函数 } ... }
然后还是来到老地方——tcp_v4_do_rcv()。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) { struct sock *rsk; if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */ ... } if (skb->len < tcp_hdrlen(skb) || tcp_checksum_complete(skb)) goto csum_err; if (sk->sk_state == TCP_LISTEN) { ... } else sock_rps_save_rxhash(sk, skb); if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) { rsk = sk; goto reset; } return 0; ... }
不过因为此时我们socket的状态是SYN_SENT,所以就直接进入tcp_rcv_state_process()的处理流程了。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock *req; int queued = 0; bool acceptable; u32 synack_stamp; tp->rx_opt.saw_tstamp = 0; switch (sk->sk_state) { ... case TCP_SYN_SENT: //进入到synack报文的处理流程 queued = tcp_rcv_synsent_state_process(sk, skb, th, len); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } ... }
层层深入,最后进入的归宿是tcp_rcv_synsent_state_process()。
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len) { struct inet_connection_sock *icsk = inet_csk(sk); struct tcp_sock *tp = tcp_sk(sk); struct tcp_fastopen_cookie foc = { .len = -1 }; int saved_clamp = tp->rx_opt.mss_clamp; //分析TCP选项 tcp_parse_options(skb, &tp->rx_opt, 0, &foc); if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr) tp->rx_opt.rcv_tsecr -= tp->tsoffset; if (th->ack) {//处理带ACK标志的报文 //如果接收到的确认号小于或等于已发送未确认的序列号, //或者大于下次要发送数据的序列号,非法报文,发送RST报文 if (!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_una) || after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) goto reset_and_undo; //如果开启了时间戳选项,且回显时间戳不为空 if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr && //且回显时间戳不在当前时间和SYN报文发送的时间窗内,就认为该报文非法 !between(tp->rx_opt.rcv_tsecr, tp->retrans_stamp, tcp_time_stamp)) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSACTIVEREJECTED); goto reset_and_undo; } if (th->rst) {//ack报文不允许出现rst标志 tcp_reset(sk); goto discard; } if (!th->syn)//除了上面的几种标志位和SYN标志位,其余报文都丢弃 goto discard_and_undo; TCP_ECN_rcv_synack(tp, th); tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); //确认ACK的确认号正常 tcp_ack(sk, skb, FLAG_SLOWPATH); /* Ok.. it‘s good. Set up sequence numbers and * move to established. */ tp->rcv_nxt = TCP_SKB_CB(skb)->seq + 1; tp->rcv_wup = TCP_SKB_CB(skb)->seq + 1; /* RFC1323: The window in SYN & SYN/ACK segments is * never scaled. */ tp->snd_wnd = ntohs(th->window); if (!tp->rx_opt.wscale_ok) { tp->rx_opt.snd_wscale = tp->rx_opt.rcv_wscale = 0; tp->window_clamp = min(tp->window_clamp, 65535U); } //如果连接支持时间戳选项 if (tp->rx_opt.saw_tstamp) { tp->rx_opt.tstamp_ok = 1; tp->tcp_header_len = sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED; tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; tcp_store_ts_recent(tp);//记录对端的时间戳 } else { tp->tcp_header_len = sizeof(struct tcphdr); } if (tcp_is_sack(tp) && sysctl_tcp_fack) tcp_enable_fack(tp); tcp_mtup_init(sk);//mtu探测初始化 tcp_sync_mss(sk, icsk->icsk_pmtu_cookie); tcp_initialize_rcv_mss(sk); /* Remember, tcp_poll() does not lock socket! * Change state from SYN-SENT only after copied_seq * is initialized. */ tp->copied_seq = tp->rcv_nxt; smp_mb(); //连接建立完成,将连接状态推向established //然后唤醒等在该socket的所有睡眠进程 tcp_finish_connect(sk, skb); //快速开启选项 if ((tp->syn_fastopen || tp->syn_data) && tcp_rcv_fastopen_synack(sk, skb, &foc)) return -1; /* 如果有以下情况,不会马上发送ACK报文 * 1.有数据等待发送 * 2.用户设置了TCP_DEFER_ACCEPT选项 * 3.禁用快速确认模式,可通过TCP_QUICKACK设置 */ if (sk->sk_write_pending || icsk->icsk_accept_queue.rskq_defer_accept || icsk->icsk_ack.pingpong) { //设置ICSK_ACK_SCHED标识,有ACK等待发送,当前不发送 inet_csk_schedule_ack(sk); //最后一次接收到数据包的时间 icsk->icsk_ack.lrcvtime = tcp_time_stamp; //设置快速确认模式,以及快速确认模式下可以发送的ACK报文数 tcp_enter_quickack_mode(sk); //激活延迟ACK定时器,超时时间为200ms //最多延迟200ms就会发送ACK报文 inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK, TCP_DELACK_MAX, TCP_RTO_MAX); discard: __kfree_skb(skb); return 0; } else { tcp_send_ack(sk);//否则马上发送ACK报文,即第三次握手报文 } return -1; } //没有ACK标记,只有RST标记,丢弃报文 if (th->rst) { goto discard_and_undo; } /* PAWS check. */ if (tp->rx_opt.ts_recent_stamp && tp->rx_opt.saw_tstamp && tcp_paws_reject(&tp->rx_opt, 0)) goto discard_and_undo; //在SYNSENT状态收到syn报文,说明这是同时打开的场景 if (th->syn) { /* We see SYN without ACK. It is attempt of * simultaneous connect with crossed SYNs. * Particularly, it can be connect to self. */ //设置连接状态为SYN_RECV tcp_set_state(sk, TCP_SYN_RECV); } ... }
我们知道,客户端收到这个SYNACK报文后就会进入ESTABLISHED状态,这主要是tcp_finish_connect()里操作的。
void tcp_finish_connect(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); //对于客户端来说,此时连接已经建立,设置连接状态为established tcp_set_state(sk, TCP_ESTABLISHED); if (skb != NULL) { icsk->icsk_af_ops->sk_rx_dst_set(sk, skb); security_inet_conn_established(sk, skb); } /* Make sure socket is routed, for correct metrics. */ icsk->icsk_af_ops->rebuild_header(sk); //初始化TCP metrics,用于保存连接相关的路由信息 tcp_init_metrics(sk); //初始化拥塞控制 tcp_init_congestion_control(sk); //记录最后一个数据包发送的时间戳 tp->lsndtime = tcp_time_stamp; //初始化接收缓存和发送缓存 tcp_init_buffer_space(sk); //如果使用了SO_KEEPALIVE选项,那就激活保活定时器 if (sock_flag(sk, SOCK_KEEPOPEN)) inet_csk_reset_keepalive_timer(sk, keepalive_time_when(tp)); if (!tp->rx_opt.snd_wscale) __tcp_fast_path_on(tp, tp->snd_wnd); else tp->pred_flags = 0; if (!sock_flag(sk, SOCK_DEAD)) { //指向sock_def_wakeup,唤醒该socket上所有睡眠的进程 sk->sk_state_change(sk); //如果进程使用了异步通知,发送SIGIO信号通知进程可写 sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); } }
tcp_finish_connect()中主要有以下几点重要操作:
将socket状态推向ESTABLISHED,也就意味着在客户端来看,连接已经建立
然后是初始化路由和拥塞控制等一下参数
同时如果用户开启了保活定时器,此时开始生效,计算连接空闲时间
最后就是唤醒该socket上所有睡眠的进程,如果有进程使用异步通知,则发送SIGIO信号通知进程可写
最后就是发送第三次握手报文——ACK报文。不过ACK报文并不一定是马上发送,在一下几种情况下会延迟发送。
当前刚好有数据等待发送
用户设置了TCP_DEFER_ACCEPT选项
禁用快速确认模式,可通过TCP_QUICKACK选项设置
不过即使延迟,也最多延迟200ms,这个通过延迟ACK定时器操作。
如果是马上发送ACK报文,则通过tcp_send_ack()发送。
/* This routine sends an ack and also updates the window. */ void tcp_send_ack(struct sock *sk) { struct sk_buff *buff; /* If we have been reset, we may not send again. */ if (sk->sk_state == TCP_CLOSE) return; tcp_ca_event(sk, CA_EVENT_NON_DELAYED_ACK); /* We are not putting this on the write queue, so * tcp_transmit_skb() will set the ownership to this * sock. */ buff = alloc_skb(MAX_TCP_HEADER, sk_gfp_atomic(sk, GFP_ATOMIC)); if (buff == NULL) {//分配失败 //和上面讲到的延迟ACK一样,设置延迟ACK,稍后再发送 inet_csk_schedule_ack(sk); //超时时间为200ms inet_csk(sk)->icsk_ack.ato = TCP_ATO_MIN; //激活延迟ACK定时器 inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK, TCP_DELACK_MAX, TCP_RTO_MAX); return; } /* Reserve space for headers and prepare control bits. */ skb_reserve(buff, MAX_TCP_HEADER); //初始化无数据的skb tcp_init_nondata_skb(buff, tcp_acceptable_seq(sk), TCPHDR_ACK); /* We do not want pure acks influencing TCP Small Queues or fq/pacing * too much. * SKB_TRUESIZE(max(1 .. 66, MAX_TCP_HEADER)) is unfortunately ~784 * We also avoid tcp_wfree() overhead (cache line miss accessing * tp->tsq_flags) by using regular sock_wfree() */ skb_set_tcp_pure_ack(buff); /* Send it off, this clears delayed acks for us. */ skb_mstamp_get(&buff->skb_mstamp); //又到了这个路径,往后就是IP层了 tcp_transmit_skb(sk, buff, 0, sk_gfp_atomic(sk, GFP_ATOMIC)); }
客户端发送第三个握手报文ACK报文后,客户端其实就已经处于连接建立的状态,此时服务端还需要接收到这个ACK报文才算最终完成连接建立。
TCP层接收到ACK还是由tcp_v4_rcv()处理,这就是TCP层的对外接口。
int tcp_v4_rcv(struct sk_buff *skb) { ... //根据报文的源和目的地址在established哈希表以及listen哈希表中查找连接 //之前服务端接收到客户端的SYN报文时,socket的状态依然是listen //所以在接收到客户端的ACK时(第三次握手),依然从listen哈希表中找到对应的连接 //这里有个疑问就是,既然此时还是listen状态,为啥所有的解释都是说在接收到SYN //报文后服务端进入SYN_RECV,连netstat命令查出来的也是。。。 sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest); if (!sk) goto no_tcp_socket; ... ret = 0; if (!sock_owned_by_user(sk)) {//如果sk没有被用户锁定,及没在使用 if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb);//进入到主处理函数 ... }
在SYN报文接收时就会将请求放入半连接队列,因此在第三次握手时就能在半连接队列找到对应的请求连接了。
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb) { struct tcphdr *th = tcp_hdr(skb); const struct iphdr *iph = ip_hdr(skb); struct sock *nsk; struct request_sock **prev; //在第一次握手时会将连接放入半连接队列,因此这里是能找到对应请求连接的 struct request_sock *req = inet_csk_search_req(sk, &prev, th->source, iph->saddr, iph->daddr); //找到之前的连接 if (req) //使用这个req创建一个socket并返回 return tcp_check_req(sk, skb, req, prev, false); ... } struct request_sock *inet_csk_search_req(const struct sock *sk, struct request_sock ***prevp, const __be16 rport, const __be32 raddr, const __be32 laddr) { const struct inet_connection_sock *icsk = inet_csk(sk); struct listen_sock *lopt = icsk->icsk_accept_queue.listen_opt; struct request_sock *req, **prev; //遍历半连接队列,查找对应连接 for (prev = &lopt->syn_table[inet_synq_hash(raddr, rport, lopt->hash_rnd, lopt->nr_table_entries)]; (req = *prev) != NULL; prev = &req->dl_next) { const struct inet_request_sock *ireq = inet_rsk(req); if (ireq->ir_rmt_port == rport && ireq->ir_rmt_addr == raddr && ireq->ir_loc_addr == laddr && AF_INET_FAMILY(req->rsk_ops->family)) { WARN_ON(req->sk); *prevp = prev; break; } } return req; }
找到这个半连接请求后,就根据这个请求信息创建一个新的socket,由tcp_check_req()操作。
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb, struct request_sock *req, struct request_sock **prev, bool fastopen) { struct tcp_options_received tmp_opt; struct sock *child; const struct tcphdr *th = tcp_hdr(skb); __be32 flg = tcp_flag_word(th) & (TCP_FLAG_RST|TCP_FLAG_SYN|TCP_FLAG_ACK); bool paws_reject = false; BUG_ON(fastopen == (sk->sk_state == TCP_LISTEN)); tmp_opt.saw_tstamp = 0; if (th->doff > (sizeof(struct tcphdr)>>2)) { tcp_parse_options(skb, &tmp_opt, 0, NULL);//分析TCP头部选项 if (tmp_opt.saw_tstamp) {//如果开启了时间戳选项 //这个时间其实就是客户端发送SYN报文的时间 //req->ts_recent是在收到SYN报文时记录的 tmp_opt.ts_recent = req->ts_recent; //注释里写ts_recent_stamp表示的是记录ts_recent时的时间 //这里通过推算的方法得出ts_recent的时间,但是我觉得明显估计的不对 //按照代码说的,如果SYNACK报文没有重传(req->num_timeout=0) //那么ts_recent_stamp即为当前时间减去1 //但是收到SYN报文的时间肯定不可能是1s前,连接建立也就几毫秒的事。。。 tmp_opt.ts_recent_stamp = get_seconds() - ((TCP_TIMEOUT_INIT/HZ)<<req->num_timeout); //确认时间戳是否回绕,比较第一次握手报文和第三次握手报文的时间戳 //没有回绕,返回false paws_reject = tcp_paws_reject(&tmp_opt, th->rst); } } //如果接收到的报文序列号等于之前SYN报文的序列号,说明这是一个重传SYN报文 //如果SYN报文时间戳没有回绕,那就重新发送SYNACK报文,然后更新半连接超时时间 if (TCP_SKB_CB(skb)->seq == tcp_rsk(req)->rcv_isn && flg == TCP_FLAG_SYN && !paws_reject) { if (!tcp_oow_rate_limited(sock_net(sk), skb, LINUX_MIB_TCPACKSKIPPEDSYNRECV, &tcp_rsk(req)->last_oow_ack_time) && !inet_rtx_syn_ack(sk, req))//没有超过速率限制,那就重发SYNACK报文 req->expires = min(TCP_TIMEOUT_INIT << req->num_timeout, TCP_RTO_MAX) + jiffies;//更新半连接的超时时间 return NULL; } //收到的ACK报文的确认号不对,返回listen socket if ((flg & TCP_FLAG_ACK) && !fastopen && (TCP_SKB_CB(skb)->ack_seq != tcp_rsk(req)->snt_isn + 1)) return sk; /* Also, it would be not so bad idea to check rcv_tsecr, which * is essentially ACK extension and too early or too late values * should cause reset in unsynchronized states. */ /* RFC793: "first check sequence number". */ //报文时间戳回绕,或者报文序列不在窗口范围,发送ACK后丢弃 if (paws_reject || !tcp_in_window(TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq, tcp_rsk(req)->rcv_nxt, tcp_rsk(req)->rcv_nxt + req->rcv_wnd)) { /* Out of window: send ACK and drop. */ if (!(flg & TCP_FLAG_RST)) req->rsk_ops->send_ack(sk, skb, req); if (paws_reject) NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSESTABREJECTED); return NULL; } /* In sequence, PAWS is OK. */ //开启了时间戳,且收到的报文序列号小于等于期望接收的序列号 if (tmp_opt.saw_tstamp && !after(TCP_SKB_CB(skb)->seq, tcp_rsk(req)->rcv_nxt)) req->ts_recent = tmp_opt.rcv_tsval;//更新ts_recent为第三次握手报文的时间戳 //清除SYN标记 if (TCP_SKB_CB(skb)->seq == tcp_rsk(req)->rcv_isn) { /* Truncate SYN, it is out of window starting at tcp_rsk(req)->rcv_isn + 1. */ flg &= ~TCP_FLAG_SYN; } /* RFC793: "second check the RST bit" and * "fourth, check the SYN bit" */ if (flg & (TCP_FLAG_RST|TCP_FLAG_SYN)) { TCP_INC_STATS_BH(sock_net(sk), TCP_MIB_ATTEMPTFAILS); goto embryonic_reset; } /* ACK sequence verified above, just make sure ACK is * set. If ACK not set, just silently drop the packet. * * XXX (TFO) - if we ever allow "data after SYN", the * following check needs to be removed. */ if (!(flg & TCP_FLAG_ACK)) return NULL; /* For Fast Open no more processing is needed (sk is the * child socket). */ if (fastopen) return sk; /* While TCP_DEFER_ACCEPT is active, drop bare ACK. */ //设置了TCP_DEFER_ACCEPT,即延迟ACK选项,且该ACK没有携带数据,那就先丢弃 if (req->num_timeout < inet_csk(sk)->icsk_accept_queue.rskq_defer_accept && TCP_SKB_CB(skb)->end_seq == tcp_rsk(req)->rcv_isn + 1) { inet_rsk(req)->acked = 1;//标记已经接收过ACK报文了 NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPDEFERACCEPTDROP); return NULL; } /* OK, ACK is valid, create big socket and * feed this segment to it. It will repeat all * the tests. THIS SEGMENT MUST MOVE SOCKET TO * ESTABLISHED STATE. If it will be dropped after * socket is created, wait for troubles. */ //这里总算是正常ACK报文了,创建一个新的socket并返回 child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL); if (child == NULL) goto listen_overflow; //将老的socket从半连接队列里摘链 inet_csk_reqsk_queue_unlink(sk, req, prev); //删除摘除的请求,然后更新半连接队列的统计信息 //如果半连接队列为空,删除SYNACK定时器 inet_csk_reqsk_queue_removed(sk, req); //将新创建的新socket加入全连接队列里,并更新队列统计信息 inet_csk_reqsk_queue_add(sk, req, child); return child; ... }
找到半连接队列里的请求后,还需要和当前接收到的报文比较,检查是否出现时间戳回绕的情况(timestamps选项开启的前提下),通过tcp_paws_reject()检测。
static inline bool tcp_paws_reject(const struct tcp_options_received *rx_opt, int rst) { //检查时间戳是否回绕 if (tcp_paws_check(rx_opt, 0)) return false; //第三次握手报文一般都不会有rst标志 //另一个条件是,当前时间和上次该ip通信的时间间隔大于TCP_PAWS_MSL(60s), //即一个time_wait状态持续时间 if (rst && get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_MSL) return false; return true; } static inline bool tcp_paws_check(const struct tcp_options_received *rx_opt, int paws_win) { //rx_opt->ts_recent是SYN报文发送时间, //rx_opt->rcv_tsval是客户端发送第三次握手报文的时间 //也就是要保证时间戳没有回绕,正常情况下这里就满足返回了 if ((s32)(rx_opt->ts_recent - rx_opt->rcv_tsval) <= paws_win) return true; //距离上一次收到这个ip的报文过去了24天,一般不可能 if (unlikely(get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_24DAYS)) return true; //没有开启时间戳 if (!rx_opt->ts_recent) return true; return false; }
确认时间戳未发生回绕后,看下是不是重传的SYN报文,如果是那就重发SYNACK报文,并重置SYNACK定时器。
接下来一个比较重要的点就是,如果开启了TCP_DEFER_ACCEPT选项,即延迟ACK选项,但是接收到的这个ACK没有携带数据,那就先丢弃,标记收到过ACK报文,等待后续客户端发送数据再做连接建立的真正操作。
重重检查后,总算是要创建新的socket了,因此inet_csk(sk)->icsk_af_ops->syn_recv_sock上场了。我们熟悉的icsk_af_ops又来了,它指向的是ipv4_specific,
const struct inet_connection_sock_af_ops ipv4_specific = { .queue_xmit = ip_queue_xmit, .send_check = tcp_v4_send_check, .rebuild_header = inet_sk_rebuild_header, .sk_rx_dst_set = inet_sk_rx_dst_set, .conn_request = tcp_v4_conn_request, .syn_recv_sock = tcp_v4_syn_recv_sock, ... };
所以创建新socket就是tcp_v4_syn_recv_sock()完成的。
/* * The three way handshake has completed - we got a valid synack - * now create the new socket. */ struct sock *tcp_v4_syn_recv_sock(struct sock *sk, struct sk_buff *skb, struct request_sock *req, struct dst_entry *dst) { struct inet_request_sock *ireq; struct inet_sock *newinet; struct tcp_sock *newtp; struct sock *newsk; #ifdef CONFIG_TCP_MD5SIG struct tcp_md5sig_key *key; #endif struct ip_options_rcu *inet_opt; //如果全连接队列已经满了,那就丢弃报文 if (sk_acceptq_is_full(sk)) goto exit_overflow; //创建一个新的socket用于连接建立后的处理,原来的socket继续监听新发起的连接 newsk = tcp_create_openreq_child(sk, req, skb); if (!newsk) goto exit_nonewsk; ... //处理新创建的socket的端口,一般就是和原来监听socket使用同一个端口 if (__inet_inherit_port(sk, newsk) < 0) goto put_and_exit; //将新创建的新socket加入established哈希表中 __inet_hash_nolisten(newsk, NULL); return newsk; ... }
检查全连接队列是否满了,满了就丢弃报文,否则请出tcp_create_openreq_child()创建新socket。
struct sock *tcp_create_openreq_child(struct sock *sk, struct request_sock *req, struct sk_buff *skb) { //创建子socket struct sock *newsk = inet_csk_clone_lock(sk, req, GFP_ATOMIC); //接下来就是新socket的各种初始化了 if (newsk != NULL) { const struct inet_request_sock *ireq = inet_rsk(req); struct tcp_request_sock *treq = tcp_rsk(req); struct inet_connection_sock *newicsk = inet_csk(newsk); struct tcp_sock *newtp = tcp_sk(newsk); ... //初始化新socket的各个定时器 tcp_init_xmit_timers(newsk); ... //如果开启时间戳 if (newtp->rx_opt.tstamp_ok) { //记录第三次握手报文发送的时间,上面的流程已经将ts_recent更新 newtp->rx_opt.ts_recent = req->ts_recent; newtp->rx_opt.ts_recent_stamp = get_seconds(); newtp->tcp_header_len = sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED; } else { newtp->rx_opt.ts_recent_stamp = 0; newtp->tcp_header_len = sizeof(struct tcphdr); } ... } return newsk; } struct sock *inet_csk_clone_lock(const struct sock *sk, const struct request_sock *req, const gfp_t priority) { struct sock *newsk = sk_clone_lock(sk, priority); if (newsk != NULL) { struct inet_connection_sock *newicsk = inet_csk(newsk); //新创建的socket状态设置为SYN_RECV newsk->sk_state = TCP_SYN_RECV; newicsk->icsk_bind_hash = NULL; //记录目的端口,以及服务器端端口 inet_sk(newsk)->inet_dport = inet_rsk(req)->ir_rmt_port; inet_sk(newsk)->inet_num = inet_rsk(req)->ir_num; inet_sk(newsk)->inet_sport = htons(inet_rsk(req)->ir_num); newsk->sk_write_space = sk_stream_write_space; inet_sk(newsk)->mc_list = NULL; newicsk->icsk_retransmits = 0;//重传次数 newicsk->icsk_backoff = 0;//退避指数 newicsk->icsk_probes_out = 0; /* Deinitialize accept_queue to trap illegal accesses. */ memset(&newicsk->icsk_accept_queue, 0, sizeof(newicsk->icsk_accept_queue)); security_inet_csk_clone(newsk, req); } return newsk; }
从inet_csk_clone_lock()中我们终于看到socket的状态进入SYN_RECV了,千呼万唤始出来啊,这都是第三次握手报文了,说好的接收到SYN报文就进入SYN_RECV的呢,骗得我好苦。
创建好新的socket后,需要将该socket归档,处理其使用端口,并且放入bind哈希表,这样之后我们才能查询得到这个新的socket。
int __inet_inherit_port(struct sock *sk, struct sock *child) { struct inet_hashinfo *table = sk->sk_prot->h.hashinfo; unsigned short port = inet_sk(child)->inet_num; const int bhash = inet_bhashfn(sock_net(sk), port, table->bhash_size); struct inet_bind_hashbucket *head = &table->bhash[bhash]; struct inet_bind_bucket *tb; spin_lock(&head->lock); tb = inet_csk(sk)->icsk_bind_hash; //一般新socket和原先的socket端口都是一样的 if (tb->port != port) { /* NOTE: using tproxy and redirecting skbs to a proxy * on a different listener port breaks the assumption * that the listener socket‘s icsk_bind_hash is the same * as that of the child socket. We have to look up or * create a new bind bucket for the child here. */ inet_bind_bucket_for_each(tb, &head->chain) { if (net_eq(ib_net(tb), sock_net(sk)) && tb->port == port) break; } if (!tb) { tb = inet_bind_bucket_create(table->bind_bucket_cachep, sock_net(sk), head, port); if (!tb) { spin_unlock(&head->lock); return -ENOMEM; } } }
//将新的socket加入bind哈希表中 inet_bind_hash(child, tb, port); spin_unlock(&head->lock); return 0; }
但是加入bind哈希表并不足够,bind哈希表只是存储绑定的ip和端口信息,还需要以下几个动作:
将新建的socket加入establish哈希表
将原先老的socket从半连接队列里拆除并更新半连接统计信息
将新建的socket加入全连接队列
加入全连接队列由inet_csk_reqsk_queue_add()操作,
static inline void inet_csk_reqsk_queue_add(struct sock *sk, struct request_sock *req, struct sock *child) { reqsk_queue_add(&inet_csk(sk)->icsk_accept_queue, req, sk, child); } static inline void reqsk_queue_add(struct request_sock_queue *queue, struct request_sock *req, struct sock *parent, struct sock *child) { //将请求req的sk指针指向新建立的sock,这样在后面调用accept()时 //就能通过全连接队列上的这个请求找到这个新创建的sock,然后进行通信 req->sk = child; sk_acceptq_added(parent); if (queue->rskq_accept_head == NULL) queue->rskq_accept_head = req; else queue->rskq_accept_tail->dl_next = req; queue->rskq_accept_tail = req; req->dl_next = NULL; } static inline void sk_acceptq_added(struct sock *sk) { //全连接队列里连接数量统计更新 sk->sk_ack_backlog++; }
有一点要注意的就是,加入半连接队列的函数是inet_csk_reqsk_queue_added(),和加入全连接队列的函数就差一个单词,一个是add,一个是added,别混淆了。
返回这个新创建的socket后,就进入tcp_child_process()函数继续深造。
int tcp_child_process(struct sock *parent, struct sock *child, struct sk_buff *skb) { int ret = 0; int state = child->sk_state; //新的socket没有没用户占用 if (!sock_owned_by_user(child)) { //对,又是它,就是它,处理各种状态socket的接口 ret = tcp_rcv_state_process(child, skb, tcp_hdr(skb), skb->len); /* Wakeup parent, send SIGIO */ if (state == TCP_SYN_RECV && child->sk_state != state) parent->sk_data_ready(parent, 0); } else { /* Alas, it is possible again, because we do lookup * in main socket hash table and lock on listening * socket does not protect us more. */ //用户占用则加入backlog队列 __sk_add_backlog(child, skb); } bh_unlock_sock(child); sock_put(child); return ret; }
接着socket就要从SYN_RECV进入ESTABLISHED状态了,这就又要tcp_rcv_state_process()出马了。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock *req; int queued = 0; bool acceptable; u32 synack_stamp; tp->rx_opt.saw_tstamp = 0; ... req = tp->fastopen_rsk;//快速开启选项相关 ... /* step 5: check the ACK field */ //检查ACK确认号的合法值 acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) > 0; switch (sk->sk_state) { //这个是新创建的socket,所以此时状态是SYN_RECV case TCP_SYN_RECV: if (!acceptable) return 1; /* Once we leave TCP_SYN_RECV, we no longer need req * so release it. */ if (req) {//快速开启走这个流程 synack_stamp = tcp_rsk(req)->snt_synack; tp->total_retrans = req->num_retrans; reqsk_fastopen_remove(sk, req, false); } else { //非快速开启流程 synack_stamp = tp->lsndtime; /* Make sure socket is routed, for correct metrics. */ icsk->icsk_af_ops->rebuild_header(sk); tcp_init_congestion_control(sk);//初始化拥塞控制 //mtu探测初始化 tcp_mtup_init(sk); tp->copied_seq = tp->rcv_nxt; //初始化接收和发送缓存空间 tcp_init_buffer_space(sk); } smp_mb(); //服务端连接状态终于抵达终点,established tcp_set_state(sk, TCP_ESTABLISHED); //调用sock_def_wakeup唤醒该sock上等待队列的所有进程 sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal crossed SYN case. * Passively open sockets are not waked up, because * sk->sk_sleep == NULL and sk->sk_socket == NULL. */ //对于服务端是被动开启socket,所以不会走这个流程 if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); ... } /* step 6: check the URG bit */ tcp_urg(sk, skb, th); /* step 7: process the segment text */ switch (sk->sk_state) { ... case TCP_ESTABLISHED: //这时socket已经是established状态了,可以处理及接收数据了 tcp_data_queue(sk, skb); queued = 1; break; } /* tcp_data could move socket to TIME-WAIT */ if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: __kfree_skb(skb); } return 0; }
最终,服务端也到达established状态,建立了可靠连接。
connect及bind、listen、accept背后的三次握手
标签:套接字 ssi ack oid || img exp 全双工 address
原文地址:https://www.cnblogs.com/yxzh-ustc/p/12101658.html