标签:upd 缓冲 flag 处理 target 服务 while cleanup ssi
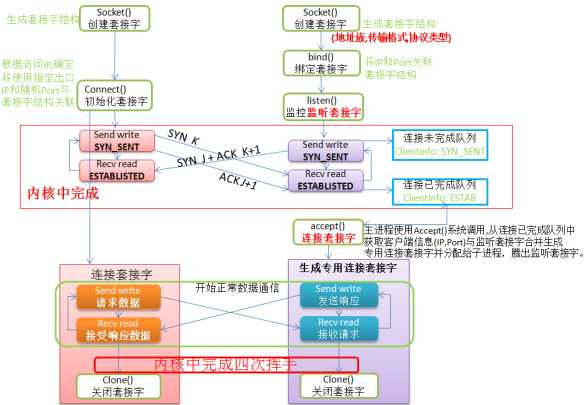
TCP Socket的连接的过程是服务端先通过socket()函数创建一个socket对象,生成一个socket文件描述符,然后通过bind()函数将生成的socket绑定到要监听的地址和端口上面。绑定好了之后,使用listen()函数来监听相应的端口。而客户端是在通过socket()函数创建一个socket对象之后,通过connect()函数向被服务端监听的socket发起一个连接请求,即发起一次TCP连接的三次握手。接下来就可以就可以通过TCP连接收发数据了。
send()和recv()为了实现数据的收发,每个TCP socket在内核中都维护了一个发送缓冲区和一个接收缓冲区,send()函数把应用缓冲区中的数据拷贝到TCP发送缓冲区中,接下来的发送过程由TCP负责;recv()函数是将TCP接收缓冲区中的数据拷贝到应用缓冲区中。在socket中,send()和recv()只管拷贝,真正的发送和接收是由TCP连接负责的。接下来我们看看TCP连接是如何实现数据收发的。
__sys_sendto和__sys_recvfrom函数实验环境的准备参考构建调试Linux内核网络代码的环境MenuOS系统
$ cd ~/linuxnet/lab3
$ make rootfs
#保持当前终端和Qemu运行,重新打开一个终端,运行gdb
$ gdb
(gdb)file ~/linux-5.0.1/vmlinux
(gdb)target remote:1234
(gdb)b __sys_sendto
(gdb)b __sys_recvfrom
(gdb)c
MenuOS>>replyhi#在MenuOS中执行
MenuOS>>hello#在MenuOS中执行
(gdb)info b# 设置好的断点信息如下
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0xffffffff817ba370 in __sys_sendto at net/socket.c:1758
2 breakpoint keep y 0xffffffff817ba540 in __sys_recvfrom at net/socket.c:1819我们先给socket中的__sys_sendto和__sys_recvfrom打上断点,执行一次replyhi/hello命令观察一下断点的情况:
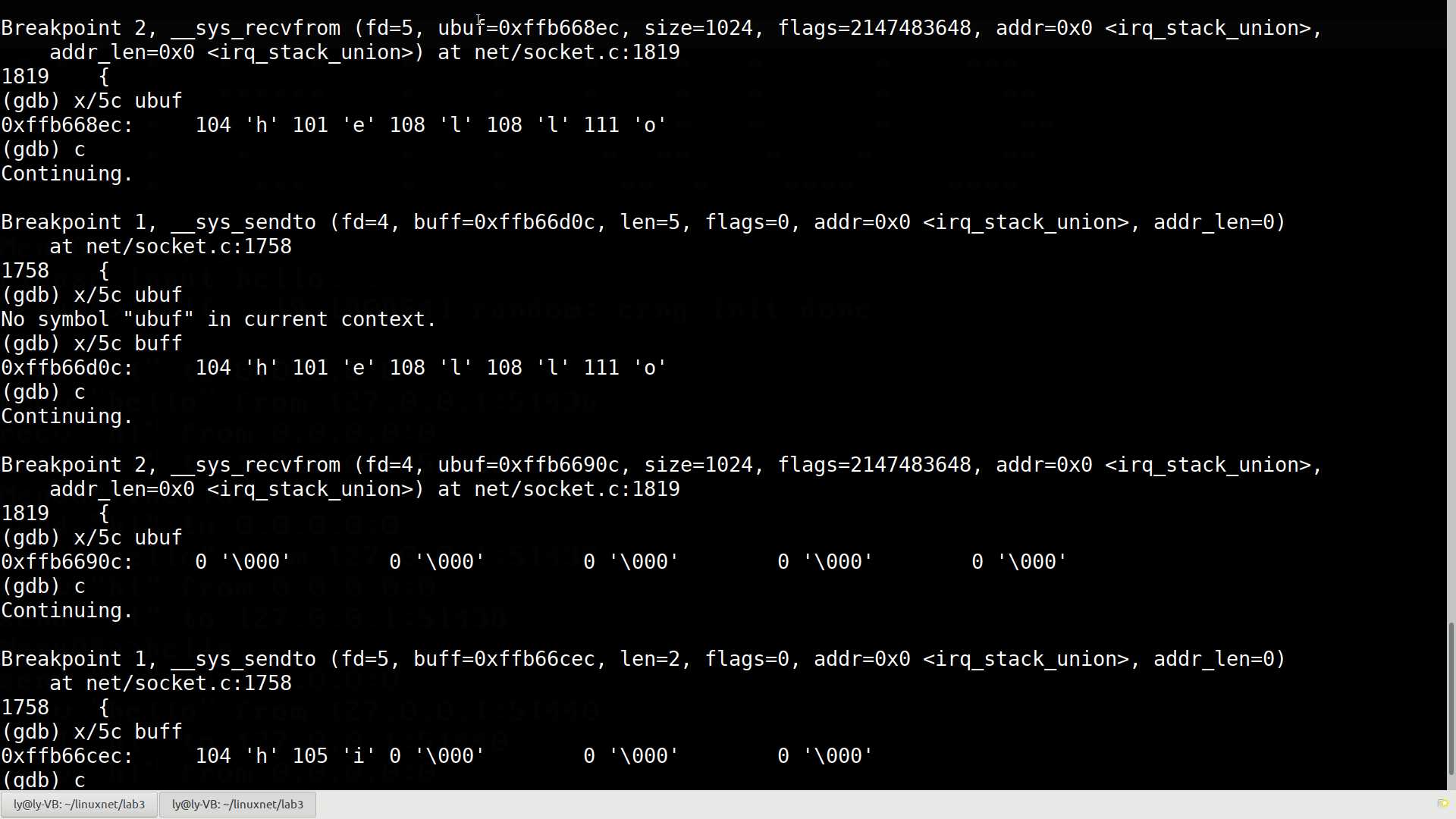
此处客户端给服务端发送了字符串"hello",而服务端回复了"hi",__sys_sendto()和__sys_recvfrom()函数的参数值如下:
Breakpoint 2, __sys_recvfrom (fd=5, ubuf=0xffb668ec, size=1024, flags=2147483648, addr=0x0 <irq_stack_union>,
addr_len=0x0 <irq_stack_union>) at net/socket.c:1819
1819 {
(gdb) x/5c ubuf////第一次截到__sys_recvfrom函数时,从缓冲区中看到已经收到了字符串"hello"
0xffb668ec: 104 'h' 101 'e' 108 'l' 108 'l' 111 'o'
(gdb) c
Continuing.
Breakpoint 1, __sys_sendto (fd=4, buff=0xffb66d0c, len=5, flags=0, addr=0x0 <irq_stack_union>, addr_len=0)
at net/socket.c:1758
1758 {
(gdb) x/5c buff//这时,截到了发送hello的__sys_sendto函数
0xffb66d0c: 104 'h' 101 'e' 108 'l' 108 'l' 111 'o'
(gdb) c
Continuing.
Breakpoint 2, __sys_recvfrom (fd=4, ubuf=0xffb6690c, size=1024, flags=2147483648, addr=0x0 <irq_stack_union>,
addr_len=0x0 <irq_stack_union>) at net/socket.c:1819
1819 {
(gdb) x/5c ubuf//此时该函数尚未接收到字符串
0xffb6690c: 0 '\000' 0 '\000' 0 '\000' 0 '\000' 0 '\000'
(gdb) c
Continuing.
Breakpoint 1, __sys_sendto (fd=5, buff=0xffb66cec, len=2, flags=0, addr=0x0 <irq_stack_union>, addr_len=0)
at net/socket.c:1758
1758 {
(gdb) x/5c buff//从缓冲区看出已经发送了hello
0xffb66cec: 104 'h' 105 'i' 0 '\000' 0 '\000' 0 '\000'
可以看到,socket中的__sys_sendto和__sys_recvfrom函数的缓冲区分别是buff和ubuf指向的内存空间,我们从源码中看一看这两个缓冲区中的数据是如何被处理的。
在~/linux-5.0.1/net/socket.c中找到对应的源码:
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
struct socket *sock;
struct iovec iov;
struct msghdr msg;
struct sockaddr_storage address;
int err, err2;
int fput_needed;
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don't copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
if (err2 < 0)
err = err2;
}
fput_light(sock->file, fput_needed);
out:
return err;
}可以看到,buff和ubuf分别被传入err后传给了sock_recvmsg和sock_sendmsg函数,接下来看查看这两个函数的源码:
int sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
EXPORT_SYMBOL(sock_sendmsg);
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags)
{
int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags);
return err ?: sock_recvmsg_nosec(sock, msg, flags);
}
EXPORT_SYMBOL(sock_recvmsg);在源码中已经难以分析出函数的调用关系了,不妨运行时一路追踪下去,看看什么时候能调用到tcp协议相关的函数:
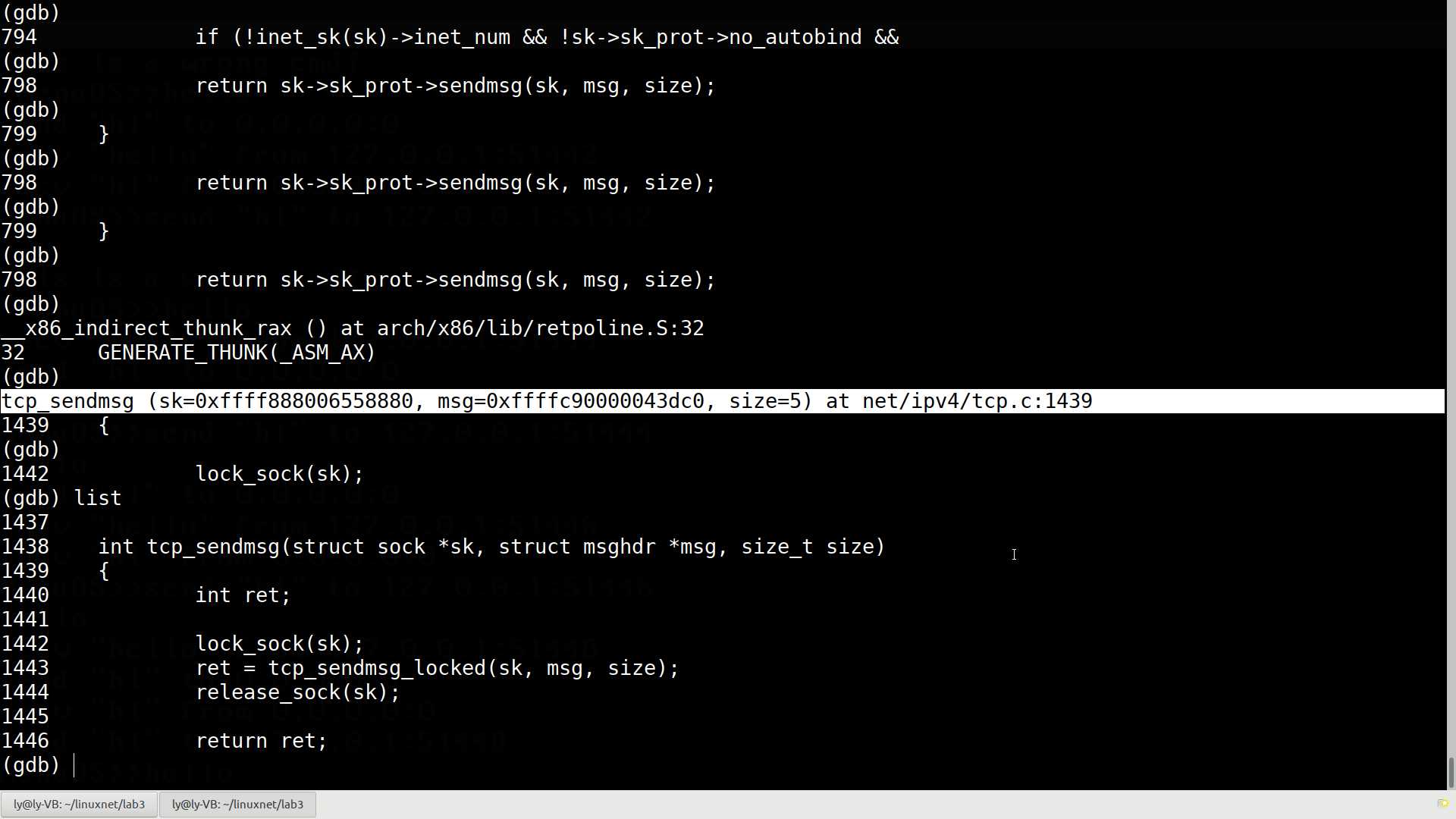
终于找到了send()对应的tcp中的函数,发现该源码在net/ipv4/tcp.c:1439:
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
EXPORT_SYMBOL(tcp_sendmsg);继续追查tcp_sendmsg_locked函数:
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
bool process_backlog = false;
bool zc = false;
long timeo;
flags = msg->msg_flags;
if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) {
if ((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) {
err = -EINVAL;
goto out_err;
}
skb = tcp_write_queue_tail(sk);
uarg = sock_zerocopy_realloc(sk, size, skb_zcopy(skb));
if (!uarg) {
err = -ENOBUFS;
goto out_err;
}
zc = sk->sk_route_caps & NETIF_F_SG;
if (!zc)
uarg->zerocopy = 0;
}
if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) &&
!tp->repair) {
err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size);
if (err == -EINPROGRESS && copied_syn > 0)
goto out;
else if (err)
goto out_err;
}
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
tcp_rate_check_app_limited(sk); /* is sending application-limited? */
/* Wait for a connection to finish. One exception is TCP Fast Open
* (passive side) where data is allowed to be sent before a connection
* is fully established.
*/
if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
!tcp_passive_fastopen(sk)) {
err = sk_stream_wait_connect(sk, &timeo);
if (err != 0)
goto do_error;
}
if (unlikely(tp->repair)) {
if (tp->repair_queue == TCP_RECV_QUEUE) {
copied = tcp_send_rcvq(sk, msg, size);
goto out_nopush;
}
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out_err;
/* 'common' sending to sendq */
}
sockcm_init(&sockc, sk);
if (msg->msg_controllen) {
err = sock_cmsg_send(sk, msg, &sockc);
if (unlikely(err)) {
err = -EINVAL;
goto out_err;
}
}
/* This should be in poll */
sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk);
/* Ok commence sending. */
copied = 0;
restart:
mss_now = tcp_send_mss(sk, &size_goal, flags);
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto do_error;
while (msg_data_left(msg)) {
int copy = 0;
skb = tcp_write_queue_tail(sk);
if (skb)
copy = size_goal - skb->len;
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
bool first_skb;
int linear;
new_segment:
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
if (process_backlog && sk_flush_backlog(sk)) {
process_backlog = false;
goto restart;
}
first_skb = tcp_rtx_and_write_queues_empty(sk);
linear = select_size(first_skb, zc);
skb = sk_stream_alloc_skb(sk, linear, sk->sk_allocation,
first_skb);
if (!skb)
goto wait_for_memory;
process_backlog = true;
skb->ip_summed = CHECKSUM_PARTIAL;
skb_entail(sk, skb);
copy = size_goal;
/* All packets are restored as if they have
* already been sent. skb_mstamp_ns isn't set to
* avoid wrong rtt estimation.
*/
if (tp->repair)
TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED;
}
/* Try to append data to the end of skb. */
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
/* Where to copy to? */
if (skb_availroom(skb) > 0 && !zc) {
/* We have some space in skb head. Superb! */
copy = min_t(int, copy, skb_availroom(skb));
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
if (err)
goto do_fault;
} else if (!zc) {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_memory;
if (!skb_can_coalesce(skb, i, pfrag->page,
pfrag->offset)) {
if (i >= sysctl_max_skb_frags) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int, copy, pfrag->size - pfrag->offset);
if (!sk_wmem_schedule(sk, copy))
goto wait_for_memory;
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
if (err)
goto do_error;
/* Update the skb. */
if (merge) {
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
page_ref_inc(pfrag->page);
}
pfrag->offset += copy;
} else {
err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg);
if (err == -EMSGSIZE || err == -EEXIST) {
tcp_mark_push(tp, skb);
goto new_segment;
}
if (err < 0)
goto do_error;
copy = err;
}
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
tp->write_seq += copy;
TCP_SKB_CB(skb)->end_seq += copy;
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
TCP_SKB_CB(skb)->eor = 1;
goto out;
}
if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
wait_for_sndbuf:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
err = sk_stream_wait_memory(sk, &timeo);
if (err != 0)
goto do_error;
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
out:
if (copied) {
tcp_tx_timestamp(sk, sockc.tsflags);
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
}
out_nopush:
sock_zerocopy_put(uarg);
return copied + copied_syn;
do_fault:
if (!skb->len) {
tcp_unlink_write_queue(skb, sk);
/* It is the one place in all of TCP, except connection
* reset, where we can be unlinking the send_head.
*/
tcp_check_send_head(sk, skb);
sk_wmem_free_skb(sk, skb);
}
do_error:
if (copied + copied_syn)
goto out;
out_err:
sock_zerocopy_put_abort(uarg, true);
err = sk_stream_error(sk, flags, err);
/* make sure we wake any epoll edge trigger waiter */
if (unlikely(skb_queue_len(&sk->sk_write_queue) == 0 &&
err == -EAGAIN)) {
sk->sk_write_space(sk);
tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED);
}
return err;
}
EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);在同一个文件中,还能找到tcp_recvmsg函数:
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err, inq;
int target; /* Read at least this many bytes */
long timeo;
struct sk_buff *skb, *last;
u32 urg_hole = 0;
struct scm_timestamping tss;
bool has_tss = false;
bool has_cmsg;
if (unlikely(flags & MSG_ERRQUEUE))
return inet_recv_error(sk, msg, len, addr_len);
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
err = -ENOTCONN;
if (sk->sk_state == TCP_LISTEN)
goto out;
has_cmsg = tp->recvmsg_inq;
timeo = sock_rcvtimeo(sk, nonblock);
/* Urgent data needs to be handled specially. */
if (flags & MSG_OOB)
goto recv_urg;
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
/* 'common' recv queue MSG_PEEK-ing */
}
seq = &tp->copied_seq;
if (flags & MSG_PEEK) {
peek_seq = tp->copied_seq;
seq = &peek_seq;
}
target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
do {
u32 offset;
/* Are we at urgent data? Stop if we have read anything or have SIGURG pending. */
if (tp->urg_data && tp->urg_seq == *seq) {
if (copied)
break;
if (signal_pending(current)) {
copied = timeo ? sock_intr_errno(timeo) : -EAGAIN;
break;
}
}
/* Next get a buffer. */
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
/* Now that we have two receive queues this
* shouldn't happen.
*/
if (WARN(before(*seq, TCP_SKB_CB(skb)->seq),
"TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt,
flags))
break;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) {
pr_err_once("%s: found a SYN, please report !\n", __func__);
offset--;
}
if (offset < skb->len)
goto found_ok_skb;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
WARN(!(flags & MSG_PEEK),
"TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags);
}
/* Well, if we have backlog, try to process it now yet. */
if (copied >= target && !sk->sk_backlog.tail)
break;
if (copied) {
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
if (sk->sk_state == TCP_CLOSE) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
if (!timeo) {
copied = -EAGAIN;
break;
}
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
tcp_cleanup_rbuf(sk, copied);
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
if ((flags & MSG_PEEK) &&
(peek_seq - copied - urg_hole != tp->copied_seq)) {
net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n",
current->comm,
task_pid_nr(current));
peek_seq = tp->copied_seq;
}
continue;
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
/* Do we have urgent data here? */
if (tp->urg_data) {
u32 urg_offset = tp->urg_seq - *seq;
if (urg_offset < used) {
if (!urg_offset) {
if (!sock_flag(sk, SOCK_URGINLINE)) {
++*seq;
urg_hole++;
offset++;
used--;
if (!used)
goto skip_copy;
}
} else
used = urg_offset;
}
}
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
skip_copy:
if (tp->urg_data && after(tp->copied_seq, tp->urg_seq)) {
tp->urg_data = 0;
tcp_fast_path_check(sk);
}
if (used + offset < skb->len)
continue;
if (TCP_SKB_CB(skb)->has_rxtstamp) {
tcp_update_recv_tstamps(skb, &tss);
has_tss = true;
has_cmsg = true;
}
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
continue;
found_fin_ok:
/* Process the FIN. */
++*seq;
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
break;
} while (len > 0);
/* According to UNIX98, msg_name/msg_namelen are ignored
* on connected socket. I was just happy when found this 8) --ANK
*/
/* Clean up data we have read: This will do ACK frames. */
tcp_cleanup_rbuf(sk, copied);
release_sock(sk);
if (has_cmsg) {
if (has_tss)
tcp_recv_timestamp(msg, sk, &tss);
if (tp->recvmsg_inq) {
inq = tcp_inq_hint(sk);
put_cmsg(msg, SOL_TCP, TCP_CM_INQ, sizeof(inq), &inq);
}
}
return copied;
out:
release_sock(sk);
return err;
recv_urg:
err = tcp_recv_urg(sk, msg, len, flags);
goto out;
recv_sndq:
err = tcp_peek_sndq(sk, msg, len);
goto out;
}
EXPORT_SYMBOL(tcp_recvmsg);可以看到,这两个函数相当复杂。在socket系统调用中调用了__sys_send()和__sys_recv后,实际调用的tcp协议中的函数正是tcp_sendmsg和tcp_recvmsg函数,下面给这两个函数打上断点,在Meno OS中验证一下:
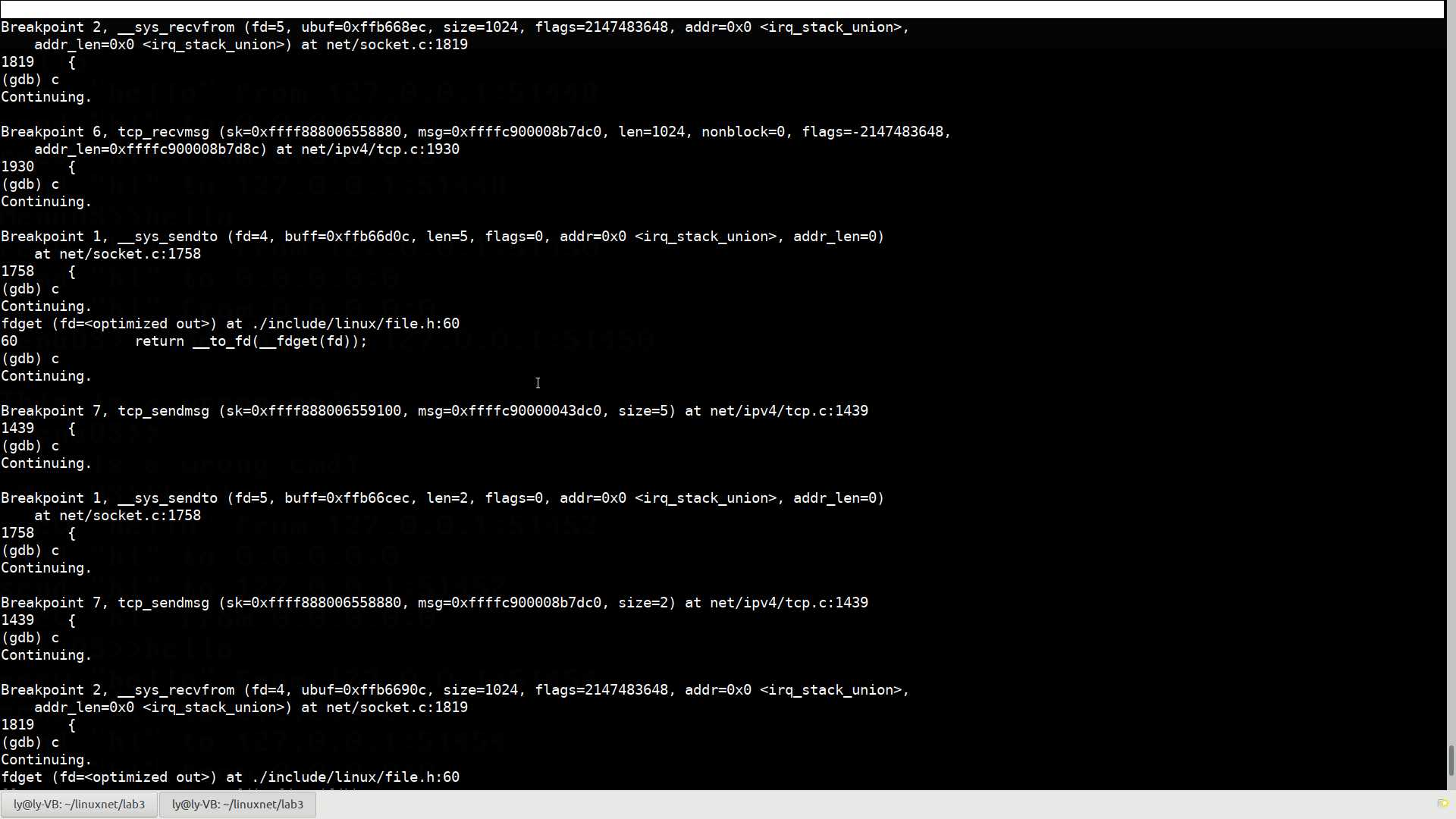
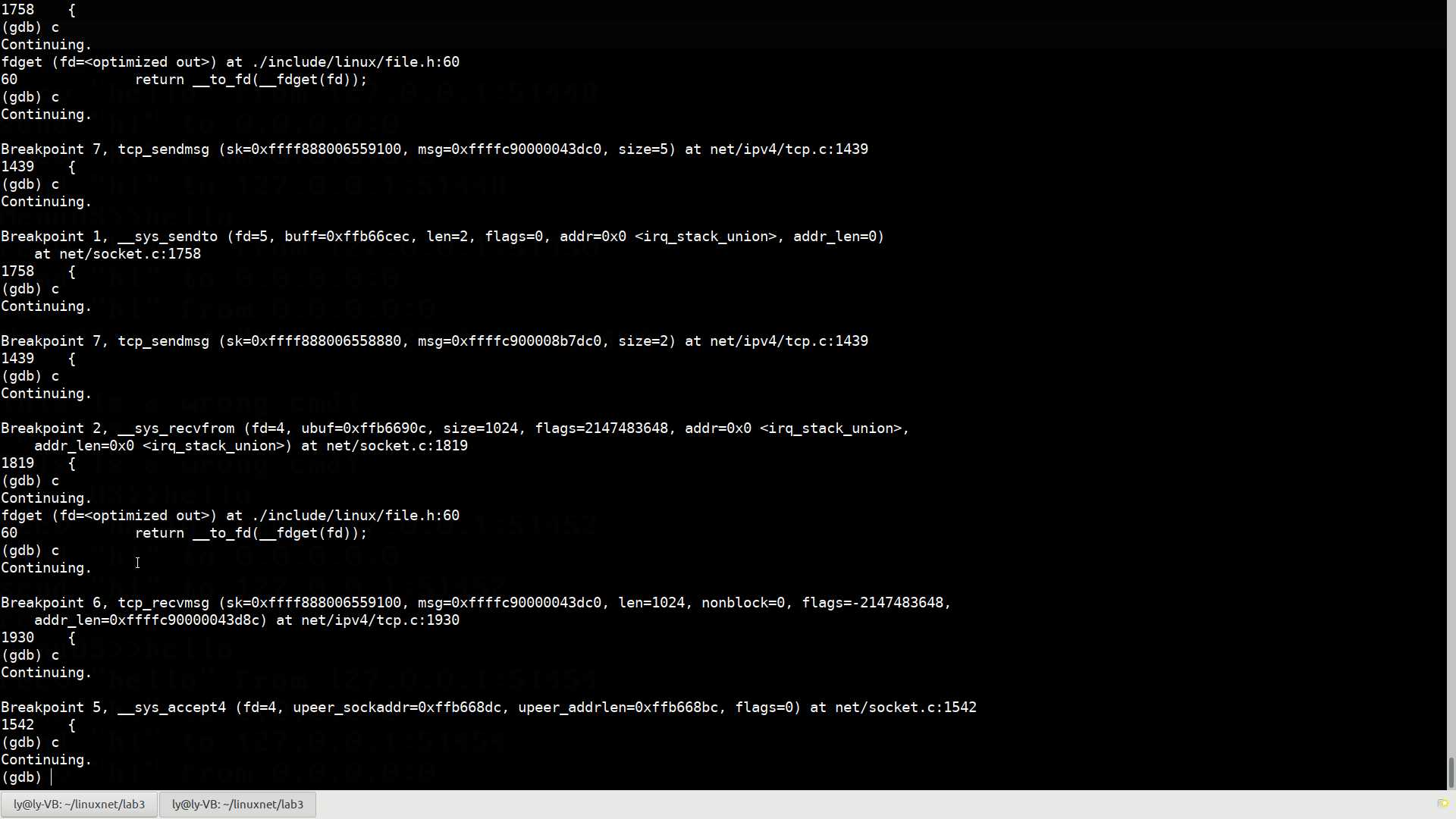
Breakpoint 2, __sys_recvfrom (fd=5, ubuf=0xffb668ec, size=1024, flags=2147483648, addr=0x0 <irq_stack_union>,
addr_len=0x0 <irq_stack_union>) at net/socket.c:1819
1819 {
(gdb) c
Continuing.
Breakpoint 6, tcp_recvmsg (sk=0xffff888006558880, msg=0xffffc900008b7dc0, len=1024, nonblock=0, flags=-2147483648,
addr_len=0xffffc900008b7d8c) at net/ipv4/tcp.c:1930
1930 {
(gdb) c
Continuing.
Breakpoint 1, __sys_sendto (fd=4, buff=0xffb66d0c, len=5, flags=0, addr=0x0 <irq_stack_union>, addr_len=0)
at net/socket.c:1758
1758 {
(gdb) c
Continuing.
fdget (fd=<optimized out>) at ./include/linux/file.h:60
60 return __to_fd(__fdget(fd));
(gdb) c
Continuing.
Breakpoint 7, tcp_sendmsg (sk=0xffff888006559100, msg=0xffffc90000043dc0, size=5) at net/ipv4/tcp.c:1439
1439 {
(gdb) c
Continuing.
Breakpoint 1, __sys_sendto (fd=5, buff=0xffb66cec, len=2, flags=0, addr=0x0 <irq_stack_union>, addr_len=0)
at net/socket.c:1758
1758 {
(gdb) c
Continuing.
Breakpoint 7, tcp_sendmsg (sk=0xffff888006558880, msg=0xffffc900008b7dc0, size=2) at net/ipv4/tcp.c:1439
1439 {
(gdb) c
Continuing.
Breakpoint 2, __sys_recvfrom (fd=4, ubuf=0xffb6690c, size=1024, flags=2147483648, addr=0x0 <irq_stack_union>,
addr_len=0x0 <irq_stack_union>) at net/socket.c:1819
1819 {
(gdb) c
Continuing.
fdget (fd=<optimized out>) at ./include/linux/file.h:60
60 return __to_fd(__fdget(fd));
(gdb) c
Continuing.
Breakpoint 6, tcp_recvmsg (sk=0xffff888006559100, msg=0xffffc90000043dc0, len=1024, nonblock=0, flags=-2147483648,
addr_len=0xffffc90000043d8c) at net/ipv4/tcp.c:1930
1930 {
(gdb) c
Continuing.
Breakpoint 5, __sys_accept4 (fd=4, upeer_sockaddr=0xffb668dc, upeer_addrlen=0xffb668bc, flags=0) at net/socket.c:1542
1542 {
(gdb) c
Continuing.
(gdb)
可以看到,__sys_send()和__sys_recv每一次运行后,tcp_sendmsg和tcp_recvmsg都被调用一次,验证了我们的结论。
https://www.cnblogs.com/f-ck-need-u/p/7623252.html#2-5-send-recv-
https://github.com/mengning/net
深入理解TCP协议及其源代码——send和recv背后数据的收发过程
标签:upd 缓冲 flag 处理 target 服务 while cleanup ssi
原文地址:https://www.cnblogs.com/litosty/p/12103594.html