标签:blocks cat direction pdf can 优点 loss from pos
facebook AI 出品
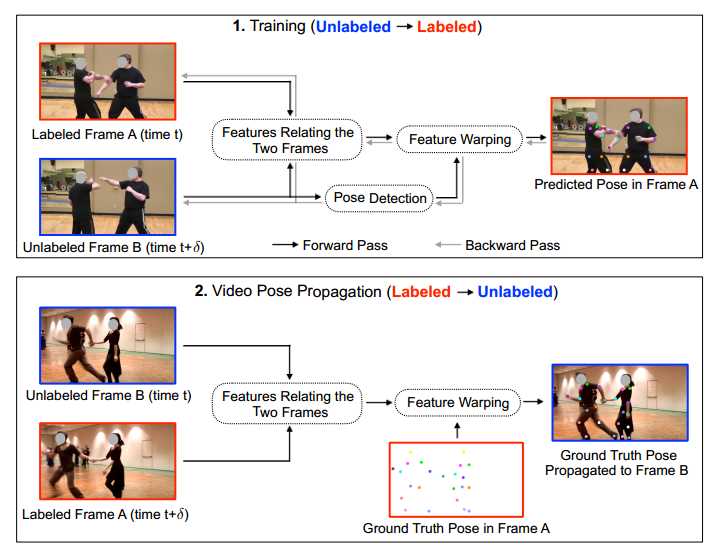
之前的关键点论文大多是在静态图片上进行关键点识别,作者的工作是在不完全标注的视频序列中识别关键点,方法是每k帧进行一次关键点标注,标注的帧和某帧未标注的帧进行特征的warping,进行预测标注帧的结果,利用标注帧的结果反向优化未标注帧的关键点结果。
《摘要》
现在视频中的多人关键点识别需要密集标注,资金和劳动力消耗大。作者提出的 PoseWarper 网络利用训练视频每K帧一标注的稀疏标注来实现密集关键点的反向传播和估计。对于已标注的视频帧A和未标注的视频帧B,A利用通过反卷积提取的B的特征学习A与B的特征扭曲。该方法的优点是:
1、at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames
2、we can improve the accuracy of a pose estimator by training it on an augmented dataset
3、we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference
开源代码: https://github.com/facebookresearch/PoseWarper
文章地址:https://arxiv.org/pdf/1906.04016.pdf
《介绍》
首先介绍关键点以前聚焦与静止图片到现在处理视频的问题,视频需要考虑运动模糊、失焦、遮挡等问题,然后介绍作者方法的优点。
1、利用反向传播,用少数量有标签的样本信息得到没有标签信息的关键点估计
2、反向传播相当于制造了伪标签。
3、推理时可以利用临近帧的信息。
《相关工作》
介绍了图像中的多人关键点识别方法,视频中的多人关键点识别方法。
确定文章的主要目的是从稀疏标注的视频中学习到一个有效的视频关键点识别检测子。
《The PoseWarper Network》
this task would become trivial, as we would simply need to spatially “warp” the feature maps computed from frame B according to the set of correspondences relating frame B to frame A.
网络的目的是为了学习两帧之间的运动偏移,决定B中的哪些坐标可以被采样用于A的预测。
Backbone Network:HRNet-W48
Deformable Warping.:
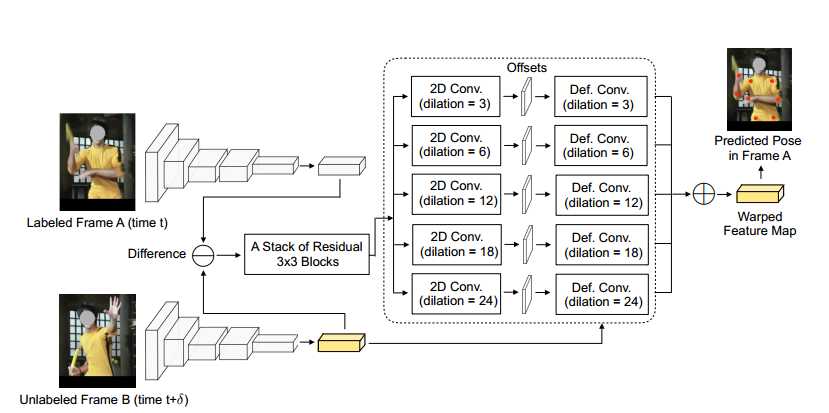
backbone CNN得到pose heatmaps,fa、fb,Wab=fa-fb, Wab是a stack of 3 × 3 simple residual blocks的输入,输出是Oab,Oab输入dilation不同的一系列3x3卷积层,在每个坐标点pn 得到相应的偏移集合 o(d)(pn) ,不同的dilation是为了得到在不同的空间尺度下的运动线索,预测到的偏移量是为了在空间上扭曲B的特征,五个偏移集合相加得到gAB,用来在A上进行预测。
Loss Function:omputes a mean squared error,applying a 2D Gaussian around the location of each joint
Pose Annotation Propagation:将AB之间的特征图大小相等,可以匹配A的真值yA,这样可以进行反向传播,we can predict the offsets for warping ground-truth heatmap yA to an unlabeled Frame B, from the feature difference WBA = fB − fA,然后可以得到yA与B之间的扭曲。
Temporal Pose Aggregation at Inference Time:u使用反卷积扭曲机制来聚集推理时附近视频帧的关键点信息来提升关键点检测的准确性。时间t时的图像帧,会聚集 时间在t + δ 时的视频帧信息,δ 在(−3; −2; −1; 0; 1; 2; 3)范围内. 此方法使算法对 occlusions, motion blur, and video defocus更鲁棒。
《实验》
略
《结论》
略
Learning Temporal Pose Estimation from Sparsely-Labeled Videos
标签:blocks cat direction pdf can 优点 loss from pos
原文地址:https://www.cnblogs.com/xiaoheizi-12345/p/12104206.html