标签:重用 cto 上下文 依赖 规模 base 单元 hdf row
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性:
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
创建RDD的两种方式
1、由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))2、由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd2 = sc.textFile("hdfs://node1.itcast.cn:9000/words.txt")RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
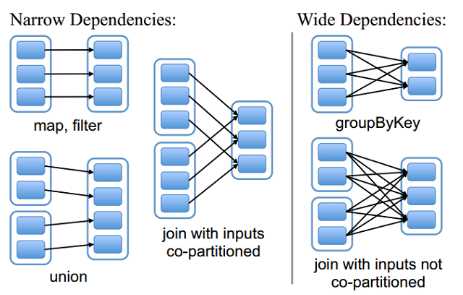
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中
RDD缓存的方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份
RDD:全称Resilient Distributed Dataset,弹性分布式数据集,Spark中最基础的数据抽象,特点是RDD只包含数据本身,没有数据结构。
DataFrame:也是一个分布式数据容器,除数据本身,还记录了数据的结构信息,即schema;结构信息便于Spark知道该数据集中包含了哪些列,每一列的类型和数据是什么。
DataSet:Spark中最上层的数据抽象,不仅包含数据本身,记录了数据的结构信息schema,还包含了数据集的类型,也就是真正把数据集做成了一个java对象的形式,需要先创建一个样例类case class,把数据做成样例类的格式,每一列就是样例类里的属性。
注:
(1)DataSet是面向对象的思想,把数据变成了对象的属性。
(2)DataSet是强类型,比如可以有DataSet[Car],DataSet[Person](汽车对象数据集,人对象数据集);DataFrame=DataSet[Row],DataFrame是DataSet的特例。
(3)在后期的Spark版本中,DataSet会逐步取代RDD和DataFrame成为唯一的API接口。
(4)三者可以互相转换

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
1、Transformation
2、Action
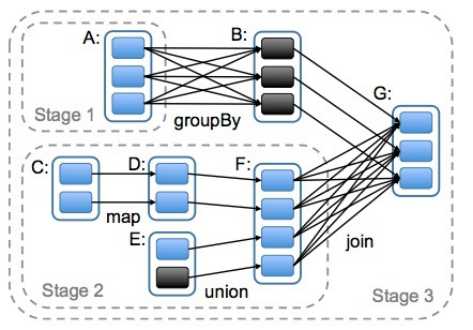
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
1、通过ActorSystem创建MasterActor,启动定时器,定时检查与接收Worker节点的发送消息
2、Worker节点主动向Master发送注册消息
3、Master接收Worker的注册请求,然后将注册信息保存起来,并向Worker返回一个注册成功的消息
4、Worker接收到Master注册成功的消息后,启用定时器,定时向master发送心跳报活,Master接收到Worker发送来的心跳消息后,更新Worker上一次的心跳时间
5、DAGScheduler根据FinalRDD递归向上解析Lineager的依赖关系,并以宽依赖为切分一个新stage的依据,并将多个task任务封装到TaskSet,其中Task的数量由其父RDD的切片数量决定,最后使用递归优先提交父Stage(TaskSet)
6、先创建TaskScheduler即TaskSchedulerImpl接着又创建SparkDeploySchedulerBackend对资源参数创建AppClient与Master注册Application,并替每个TaskSet创建TaskManager负责监控此TaskSet中任务的执行情况
7、Master接收到ClientActor的任务描述之后,将任务描述信息保存起来,然后向ClientActor返回消息,告知ClientActor任务注册成功,接下来Master(打散|负载均衡|尽量集中)进行资源调度
8、Master跟Worker通信,然后让Worker启动Executor
9、Executor向Driver发送注册消息,Driver接收到Executor注册消息后,响应注册成功的消息
10、Executor接收到Driver注册成功的消息后,本进程中创建Executor的引用对象
11、Driver中TaskSchedulerImp向Executor发送LaunchTask消息,Executor将创建一个线程池作为所提交的Task任务的容器
12、Task接收到launchTask消息后,准备运行文件初始化与反序列化,就绪后,调用Task的run方法,其中每个Task所执行的函数是应用在RDD中的一个独立分区上
13、Task运行完成,向TaskManager汇报情况,并且释放线程资源
14、所有Task运行结束之后,Executor向Worker注销自身,释放资源。
spark 的部署图:
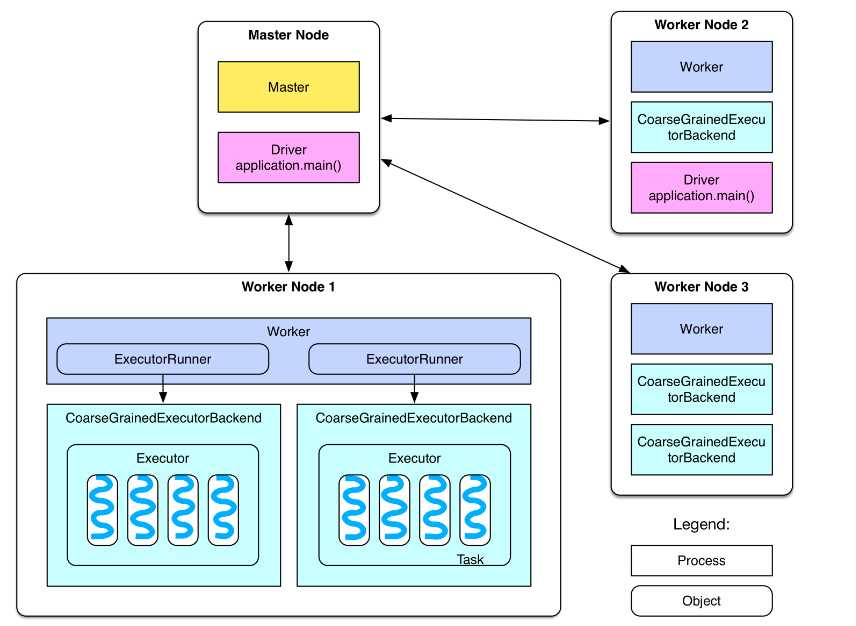
master 节点: 常驻master进程,负责管理全部worker节点。
worker 节点: 常驻worker进程,负责管理executor 并与master节点通信。
dirvier:官方解释为: The process running the main() function of the application and creating the SparkContext。即理解为用户自己编写的应用程序
在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:Executor是一个应用程序运行的监控和执行容器。Executor的数目可以在submit时,由 --num-executors (on yarn)指定.
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据.
本文主要对Spark的关键技术及原理做了阐述,主要理解以下概念:
driver program是用户写的带main函数的代码
每个action算子的操作都会对应一个job,例如(ForeachRDD写入外部系统的一个操作)
DAGScheduler会对Job进行拆分,拆分的依据:根据FinalRDD(在这里ForeachRDD)递归向上解析Lineager的依赖关系,以宽依赖为切分stage的依据,切分成若干个Stage,递归优先提交父Stage,每个Stage里面包含多个Task任务
若干个Transformation的算子RDD组成Stage,一个RDD中有多少个partition,就有多少个Task,因为每一个Task只对一个partition数据做处理
标签:重用 cto 上下文 依赖 规模 base 单元 hdf row
原文地址:https://www.cnblogs.com/bigdata1024/p/12104927.html