标签:阻塞 can ast 实验 each ipv4 class 导出 protected
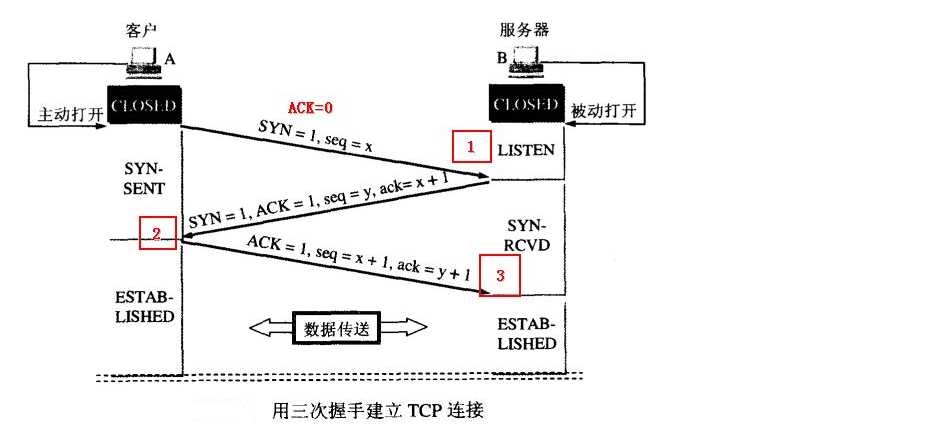
1.什么是三次握手?
TCP协议建立连接时,需要三次发送数据包:
第一次:客户机向服务器端请求建立连接
第二次:服务器收到客户机的请求,发出响应
第三次:客户机收到响应 认为连接建立成功
详细过程:
名词解释:
SYN - 标志位 只有第一次和第二次为1,第三次和其他任何情况都是0
ACK - 标志位 只有第一次不为1,第二,三次和其他任何情况都是1
Sequence Number 顺序号,初始值为随机数
Acknowledgment Number 确认号,下一次对收到的数据顺序号的期望
第一次:
客户机 >>服务器
SYN =1
ACK =0
Sequence Number=X(随机数)
第二次:
SYN =1
ACK =1
Sequence Number=Y(随机数)
Acknowledgment Number=X+1
客户机<<服务器
第三次:
SYN =0
ACK =1
Sequence Number=X+1
Acknowledgment Number=Y+1
客户机 >>服务器
2.为什么要有三次握手?
我们考虑一次和两次握手为什么不行:
考虑
链路1 客户机 >>服务器
链路2 客户机<<服务器
一次握手:
如果链路1故障,客户机仍然会认为连接成功,而服务器不知道连接发生
如果链路2故障,服务器和客户机都会认为连接成功
两次握手:
如果链路2故障,服务器会认为连接成功
接下来考虑三次握手:
如果链路1故障
服务器端收不到第一次握手包,因而不会认为有连接请求,没有误认为连接成功,也不会发送第二次握手包
客户机收不到第二次握手包(服务器端没有发送),没有误认为连接成功
双方都不会误认为连接成功
如果链路2故障
客户机收不到第二次握手包(服务器端发送了但由于链路故障没有收到),没有误认为连接成功,也不会发送第三次握手包
服务器端收不到第三次握手包(客户机没有发送),没有误认为连接成功
双方都不会误认为连接成功
3.捕获一次典型的TCP三次握手:
我们使用wireshark工具
首先 在cmd执行 ping www.baidu.com
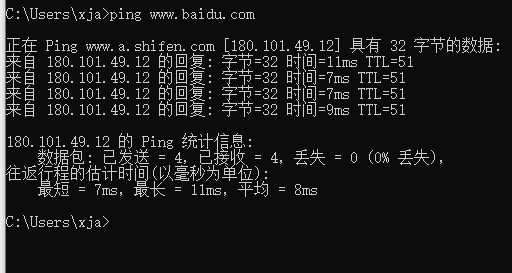
这是为了确定目标IP地址,便于设置捕获规则
ip.addr==180.101.49.12
打开www.baidu.com
捕获到
这三个数据包即是TCP三次握手数据包(192.168.3.89是本地IP)
这里有一个问题:为什么Seq的初始值是0而不是一个随机数?
这是wireShark软件本身的特性,显示的不是实际值而是相对值
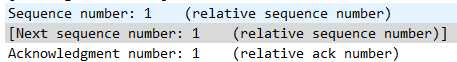
三次Sequence Number和Acknowledgment Number的真实值(使用十六进制):
第一次(分别是前八位和后八位):
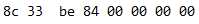
第二次:

第三次:
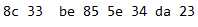
可以看到符合
X 0
Y X+1
X+1 Y+1的规律
和我们的预期相符
三次数据包的标志位:
第一次:
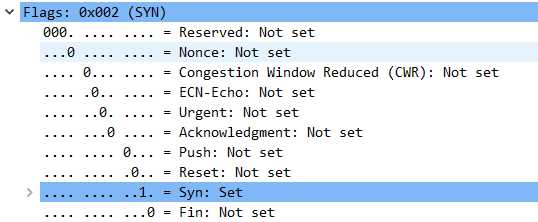
第二次:
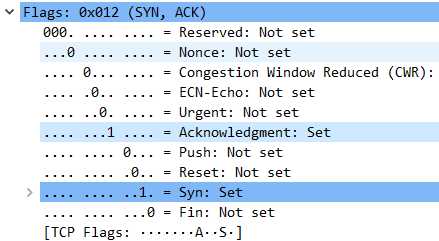
第三次:
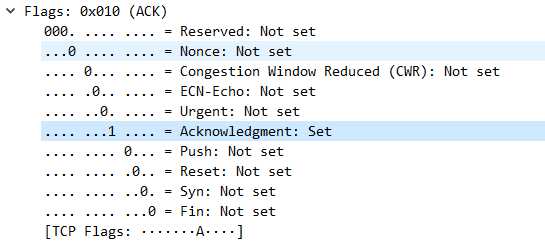
可以看到wireshark已经非常贴心的替我们做好了标注
也和我们的预期一致
3.代码追踪和分析:
在之前的实验中,我们知道发出TCP连接请求的函数是__sys_connect
我们分析这个函数的源代码
1 int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) 2 { 3 struct socket *sock; 4 struct sockaddr_storage address; 5 int err, fput_needed; 6 sock = sockfd_lookup_light(fd, &err, &fput_needed); 7 if (!sock) 8 goto out; 9 err = move_addr_to_kernel(uservaddr, addrlen, &address); 10 if (err < 0) 11 goto out_put; 12 err = 13 security_socket_connect(sock, (struct sockaddr *)&address, addrlen); 14 if (err) 15 goto out_put; 16 17 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, 18 sock->file->f_flags); 19 out_put: 20 fput_light(sock->file, fput_needed); 21 out: 22 return err; 23 }
主要的执行过程是
1 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, 2 sock->file->f_flags)
这是一个函数指针,我们通过gdb,发现指向:inet_stream_connect
源代码
1 int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, 2 int addr_len, int flags) 3 { 4 int err; 5 6 lock_sock(sock->sk); 7 err = __inet_stream_connect(sock, uaddr, addr_len, flags, 0); 8 release_sock(sock->sk); 9 return err; 10 }
发现是对__inet_stream_connect的封装,前面应当是并发控制
继续追踪源代码:
1 int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, 2 int addr_len, int flags) 3 { 4 struct sock *sk = sock->sk; 5 int err; 6 long timeo; 7 8 if (addr_len < sizeof(uaddr->sa_family)) 9 return -EINVAL; 10 11 if (uaddr->sa_family == AF_UNSPEC) { 12 err = sk->sk_prot->disconnect(sk, flags); 13 sock->state = err ? SS_DISCONNECTING : SS_UNCONNECTED; 14 goto out; 15 } 16 switch (sock->state) { 17 default: 18 err = -EINVAL; 19 goto out; 20 case SS_CONNECTED: 21 err = -EISCONN; 22 goto out; 23 case SS_CONNECTING: 24 err = -EALREADY; 25 break; 26 case SS_UNCONNECTED: 27 err = -EISCONN; 28 if (sk->sk_state != TCP_CLOSE) 29 goto out; 30 err = sk->sk_prot->connect(sk, uaddr, addr_len); 31 ...太长了 后面的先省略
重点是err = sk->sk_prot->connect(sk, uaddr, addr_len);
可以看到这个函数又是通过一个函数指针工作的
err = sk->sk_prot->connect(sk, uaddr, addr_len);
追踪这个函数指针,发现最终指向:tcp_v4_connect
源代码
1 int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) 2 { 3 struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; 4 struct inet_sock *inet = inet_sk(sk); 5 struct tcp_sock *tp = tcp_sk(sk); 6 __be16 orig_sport, orig_dport; 7 __be32 daddr, nexthop; 8 struct flowi4 *fl4; 9 struct rtable *rt; 10 int err; 11 struct ip_options_rcu *inet_opt; 12 struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row; 13 14 if (addr_len < sizeof(struct sockaddr_in)) 15 return -EINVAL; 16 17 if (usin->sin_family != AF_INET) 18 return -EAFNOSUPPORT; 19 20 nexthop = daddr = usin->sin_addr.s_addr; 21 inet_opt = rcu_dereference_protected(inet->inet_opt, 22 lockdep_sock_is_held(sk)); 23 if (inet_opt && inet_opt->opt.srr) { 24 if (!daddr) 25 return -EINVAL; 26 nexthop = inet_opt->opt.faddr; 27 } 28 29 orig_sport = inet->inet_sport; 30 orig_dport = usin->sin_port; 31 fl4 = &inet->cork.fl.u.ip4; 32 rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, 33 RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, 34 IPPROTO_TCP, 35 orig_sport, orig_dport, sk); 36 if (IS_ERR(rt)) { 37 err = PTR_ERR(rt); 38 if (err == -ENETUNREACH) 39 IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); 40 return err; 41 } 42 43 if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) { 44 ip_rt_put(rt); 45 return -ENETUNREACH; 46 } 47 48 if (!inet_opt || !inet_opt->opt.srr) 49 daddr = fl4->daddr; 50 51 if (!inet->inet_saddr) 52 inet->inet_saddr = fl4->saddr; 53 sk_rcv_saddr_set(sk, inet->inet_saddr); 54 55 if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { 56 /* Reset inherited state */ 57 tp->rx_opt.ts_recent = 0; 58 tp->rx_opt.ts_recent_stamp = 0; 59 if (likely(!tp->repair)) 60 tp->write_seq = 0; 61 } 62 63 inet->inet_dport = usin->sin_port; 64 sk_daddr_set(sk, daddr); 65 66 inet_csk(sk)->icsk_ext_hdr_len = 0; 67 if (inet_opt) 68 inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; 69 70 tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; 71 72 tcp_set_state(sk, TCP_SYN_SENT); 73 err = inet_hash_connect(tcp_death_row, sk); 74 if (err) 75 goto failure; 76 77 sk_set_txhash(sk); 78 79 rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, 80 inet->inet_sport, inet->inet_dport, sk); 81 if (IS_ERR(rt)) { 82 err = PTR_ERR(rt); 83 rt = NULL; 84 goto failure; 85 } 86 87 sk->sk_gso_type = SKB_GSO_TCPV4; 88 sk_setup_caps(sk, &rt->dst); 89 rt = NULL; 90 91 if (likely(!tp->repair)) { 92 if (!tp->write_seq) 93 tp->write_seq = secure_tcp_seq(inet->inet_saddr, 94 inet->inet_daddr, 95 inet->inet_sport, 96 usin->sin_port); 97 tp->tsoffset = secure_tcp_ts_off(sock_net(sk), 98 inet->inet_saddr, 99 inet->inet_daddr); 100 } 101 102 inet->inet_id = tp->write_seq ^ jiffies; 103 104 if (tcp_fastopen_defer_connect(sk, &err)) 105 return err; 106 if (err) 107 goto failure; 108 109 err = tcp_connect(sk); 110 111 if (err) 112 goto failure; 113 114 return 0; 115 116 failure: 117 118 tcp_set_state(sk, TCP_CLOSE); 119 ip_rt_put(rt); 120 sk->sk_route_caps = 0; 121 inet->inet_dport = 0; 122 return err; 123 }
重点在于
72 tcp_set_state(sk, TCP_SYN_SENT)
109 err = tcp_connect(sk);
继续分析
源代码:
1 void tcp_set_state(struct sock *sk, int state) 2 { 3 int oldstate = sk->sk_state; 4 5 /* We defined a new enum for TCP states that are exported in BPF 6 * so as not force the internal TCP states to be frozen. The 7 * following checks will detect if an internal state value ever 8 * differs from the BPF value. If this ever happens, then we will 9 * need to remap the internal value to the BPF value before calling 10 * tcp_call_bpf_2arg. 11 */ 12 BUILD_BUG_ON((int)BPF_TCP_ESTABLISHED != (int)TCP_ESTABLISHED); 13 BUILD_BUG_ON((int)BPF_TCP_SYN_SENT != (int)TCP_SYN_SENT); 14 BUILD_BUG_ON((int)BPF_TCP_SYN_RECV != (int)TCP_SYN_RECV); 15 BUILD_BUG_ON((int)BPF_TCP_FIN_WAIT1 != (int)TCP_FIN_WAIT1); 16 BUILD_BUG_ON((int)BPF_TCP_FIN_WAIT2 != (int)TCP_FIN_WAIT2); 17 BUILD_BUG_ON((int)BPF_TCP_TIME_WAIT != (int)TCP_TIME_WAIT); 18 BUILD_BUG_ON((int)BPF_TCP_CLOSE != (int)TCP_CLOSE); 19 BUILD_BUG_ON((int)BPF_TCP_CLOSE_WAIT != (int)TCP_CLOSE_WAIT); 20 BUILD_BUG_ON((int)BPF_TCP_LAST_ACK != (int)TCP_LAST_ACK); 21 BUILD_BUG_ON((int)BPF_TCP_LISTEN != (int)TCP_LISTEN); 22 BUILD_BUG_ON((int)BPF_TCP_CLOSING != (int)TCP_CLOSING); 23 BUILD_BUG_ON((int)BPF_TCP_NEW_SYN_RECV != (int)TCP_NEW_SYN_RECV); 24 BUILD_BUG_ON((int)BPF_TCP_MAX_STATES != (int)TCP_MAX_STATES); 25 26 if (BPF_SOCK_OPS_TEST_FLAG(tcp_sk(sk), BPF_SOCK_OPS_STATE_CB_FLAG)) 27 tcp_call_bpf_2arg(sk, BPF_SOCK_OPS_STATE_CB, oldstate, state); 28 29 switch (state) { 30 case TCP_ESTABLISHED: 31 if (oldstate != TCP_ESTABLISHED) 32 TCP_INC_STATS(sock_net(sk), TCP_MIB_CURRESTAB); 33 break; 34 35 case TCP_CLOSE: 36 if (oldstate == TCP_CLOSE_WAIT || oldstate == TCP_ESTABLISHED) 37 TCP_INC_STATS(sock_net(sk), TCP_MIB_ESTABRESETS); 38 39 sk->sk_prot->unhash(sk); 40 if (inet_csk(sk)->icsk_bind_hash && 41 !(sk->sk_userlocks & SOCK_BINDPORT_LOCK)) 42 inet_put_port(sk); 43 /* fall through */ 44 default: 45 if (oldstate == TCP_ESTABLISHED) 46 TCP_DEC_STATS(sock_net(sk), TCP_MIB_CURRESTAB); 47 } 48 49 /* Change state AFTER socket is unhashed to avoid closed 50 * socket sitting in hash tables. 51 */ 52 inet_sk_state_store(sk, state); 53 }
代码注释的含义为:
我们为在BPF中导出的TCP状态定义了一个新的枚举,以免强制冻结内部TCP状态。 以下检查将检测内部状态值是否与BPF值不同。 如果发生这种情况,那么我们需要在调用tcp_call_bpf_2arg之前将内部值重新映射为BPF值。
tcp_connect的功能是构造一个SYN报文并发送
1 int tcp_connect(struct sock *sk) 2 { 3 struct tcp_sock *tp = tcp_sk(sk); 4 struct sk_buff *buff; 5 int err; 6 7 tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0, NULL); 8 9 if (inet_csk(sk)->icsk_af_ops->rebuild_header(sk)) 10 return -EHOSTUNREACH; /* Routing failure or similar. */ 11 12 tcp_connect_init(sk); 13 14 if (unlikely(tp->repair)) { 15 tcp_finish_connect(sk, NULL); 16 return 0; 17 } 18 19 buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true); 20 if (unlikely(!buff)) 21 return -ENOBUFS; 22 23 tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); 24 tcp_mstamp_refresh(tp); 25 tp->retrans_stamp = tcp_time_stamp(tp); 26 tcp_connect_queue_skb(sk, buff); 27 tcp_ecn_send_syn(sk, buff); 28 tcp_rbtree_insert(&sk->tcp_rtx_queue, buff); 29 30 /* Send off SYN; include data in Fast Open. */ 31 err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : 32 tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); 33 if (err == -ECONNREFUSED) 34 return err; 35 36 /* We change tp->snd_nxt after the tcp_transmit_skb() call 37 * in order to make this packet get counted in tcpOutSegs. 38 */ 39 tp->snd_nxt = tp->write_seq; 40 tp->pushed_seq = tp->write_seq; 41 buff = tcp_send_head(sk); 42 if (unlikely(buff)) { 43 tp->snd_nxt = TCP_SKB_CB(buff)->seq; 44 tp->pushed_seq = TCP_SKB_CB(buff)->seq; 45 } 46 TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS); 47 48 /* Timer for repeating the SYN until an answer. */ 49 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, 50 inet_csk(sk)->icsk_rto, TCP_RTO_MAX); 51 return 0;
我们研究这个函数\
其中调用了tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
观察源代码
1 static void tcp_init_nondata_skb(struct sk_buff *skb, u32 seq, u8 flags) 2 { 3 skb->ip_summed = CHECKSUM_PARTIAL; 4 5 TCP_SKB_CB(skb)->tcp_flags = flags; 6 TCP_SKB_CB(skb)->sacked = 0; 7 8 tcp_skb_pcount_set(skb, 1); 9 10 TCP_SKB_CB(skb)->seq = seq; 11 if (flags & (TCPHDR_SYN | TCPHDR_FIN)) 12 seq++; 13 TCP_SKB_CB(skb)->end_seq = seq; 14 }
通过TCP_SKB_CB(skb)->tcp_flags = flags,把报文标志位的倒数第二位置位1,实现SYN置位
接下来分析服务器端代码
负责响应的函数是_sys_accept4:
1 int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr, 2 int __user *upeer_addrlen, int flags) 3 { 4 struct socket *sock, *newsock; 5 struct file *newfile; 6 int err, len, newfd, fput_needed; 7 struct sockaddr_storage address; 8 9 if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) 10 return -EINVAL; 11 12 if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) 13 flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; 14 15 sock = sockfd_lookup_light(fd, &err, &fput_needed); 16 if (!sock) 17 goto out; 18 19 err = -ENFILE; 20 newsock = sock_alloc(); 21 if (!newsock) 22 goto out_put; 23 24 newsock->type = sock->type; 25 newsock->ops = sock->ops; 26 27 /* 28 * We don‘t need try_module_get here, as the listening socket (sock) 29 * has the protocol module (sock->ops->owner) held. 30 */ 31 __module_get(newsock->ops->owner); 32 33 newfd = get_unused_fd_flags(flags); 34 if (unlikely(newfd < 0)) { 35 err = newfd; 36 sock_release(newsock); 37 goto out_put; 38 } 39 newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name); 40 if (IS_ERR(newfile)) { 41 err = PTR_ERR(newfile); 42 put_unused_fd(newfd); 43 goto out_put; 44 } 45 46 err = security_socket_accept(sock, newsock); 47 if (err) 48 goto out_fd; 49 50 err = sock->ops->accept(sock, newsock, sock->file->f_flags, false); 51 if (err < 0) 52 goto out_fd; 53 54 if (upeer_sockaddr) { 55 len = newsock->ops->getname(newsock, 56 (struct sockaddr *)&address, 2); 57 if (len < 0) { 58 err = -ECONNABORTED; 59 goto out_fd; 60 } 61 err = move_addr_to_user(&address, 62 len, upeer_sockaddr, upeer_addrlen); 63 if (err < 0) 64 goto out_fd; 65 } 66 67 /* File flags are not inherited via accept() unlike another OSes. */ 68 69 fd_install(newfd, newfile); 70 err = newfd; 71 72 out_put: 73 fput_light(sock->file, fput_needed); 74 out: 75 return err; 76 out_fd: 77 fput(newfile); 78 put_unused_fd(newfd); 79 goto out_put; 80 }
核心是函数指针
err = sock->ops->accept(sock, newsock, sock->file->f_flags, false);
追踪这个调用,发现是调用了inet_csk_accept
源代码
1 struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) 2 { 3 struct inet_connection_sock *icsk = inet_csk(sk); 4 struct request_sock_queue *queue = &icsk->icsk_accept_queue; 5 struct request_sock *req; 6 struct sock *newsk; 7 int error; 8 9 lock_sock(sk); 10 11 /* We need to make sure that this socket is listening, 12 * and that it has something pending. 13 */ 14 error = -EINVAL; 15 if (sk->sk_state != TCP_LISTEN) 16 goto out_err; 17 18 /* Find already established connection */ 19 if (reqsk_queue_empty(queue)) { 20 long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); 21 22 /* If this is a non blocking socket don‘t sleep */ 23 error = -EAGAIN; 24 if (!timeo) 25 goto out_err; 26 27 error = inet_csk_wait_for_connect(sk, timeo); 28 if (error) 29 goto out_err; 30 } 31 req = reqsk_queue_remove(queue, sk); 32 newsk = req->sk; 33 34 if (sk->sk_protocol == IPPROTO_TCP && 35 tcp_rsk(req)->tfo_listener) { 36 spin_lock_bh(&queue->fastopenq.lock); 37 if (tcp_rsk(req)->tfo_listener) { 38 /* We are still waiting for the final ACK from 3WHS 39 * so can‘t free req now. Instead, we set req->sk to 40 * NULL to signify that the child socket is taken 41 * so reqsk_fastopen_remove() will free the req 42 * when 3WHS finishes (or is aborted). 43 */ 44 req->sk = NULL; 45 req = NULL; 46 } 47 spin_unlock_bh(&queue->fastopenq.lock); 48 } 49 out: 50 release_sock(sk); 51 if (req) 52 reqsk_put(req); 53 return newsk; 54 out_err: 55 newsk = NULL; 56 req = NULL; 57 *err = error; 58 goto out; 59 }
这个函数的功能的功能是:从一个连接队列(已经完成三次握手)中取出控制块,若队列空,根据阻塞标志决定是直接返回还是在一定时间内阻塞并等待。
标签:阻塞 can ast 实验 each ipv4 class 导出 protected
原文地址:https://www.cnblogs.com/Miliapus/p/12104428.html