标签:add zed value 好处 应用 临界区 pos 系统 综合
原子性问题的源头是线程切换,如果能够禁用线程切换那不就能解决这个问题了吗?而操作系统做线程切换是依赖 CPU 中断的,所以禁止 CPU 发生中断就能够禁止线程切换。
在早期单核 CPU 时代,这个方案的确是可行的,而且也有很多应用案例,但是并不适合多核场景。这里我们以 32 位 CPU 上执行 long 型变量的写操作为例来说明这个问题,long 型变量是 64 位,在 32 位 CPU 上执行写操作会被拆分成两次写操作(写高 32 位和写低 32 位,如下图所示)。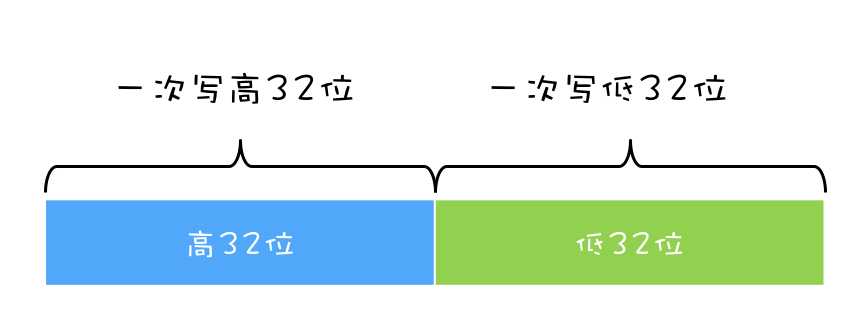
在单核 CPU 场景下,同一时刻只有一个线程执行,禁止 CPU 中断,意味着操作系统不会重新调度线程,也就是禁止了线程切换,获得 CPU 使用权的线程就可以不间断地执行,所以两次写操作一定是:要么都被执行,要么都没有被执行,具有原子性。但是在多核场景下,同一时刻,有可能有两个线程同时在执行,一个线程执行在 CPU-1 上,一个线程执行在 CPU-2 上,此时禁止 CPU 中断,只能保证 CPU 上的线程连续执行,并不能保证同一时刻只有一个线程执行,如果这两个线程同时写 long 型变量高 32 位的话,那就有可能出现诡异 Bug 。
“同一时刻只有一个线程执行”这个条件非常重要,我们称之为互斥。如果我们能够保证对共享变量的修改是互斥的,那么,无论是单核 CPU 还是多核 CPU,就都能保证原子性了。
锁模型如下图:
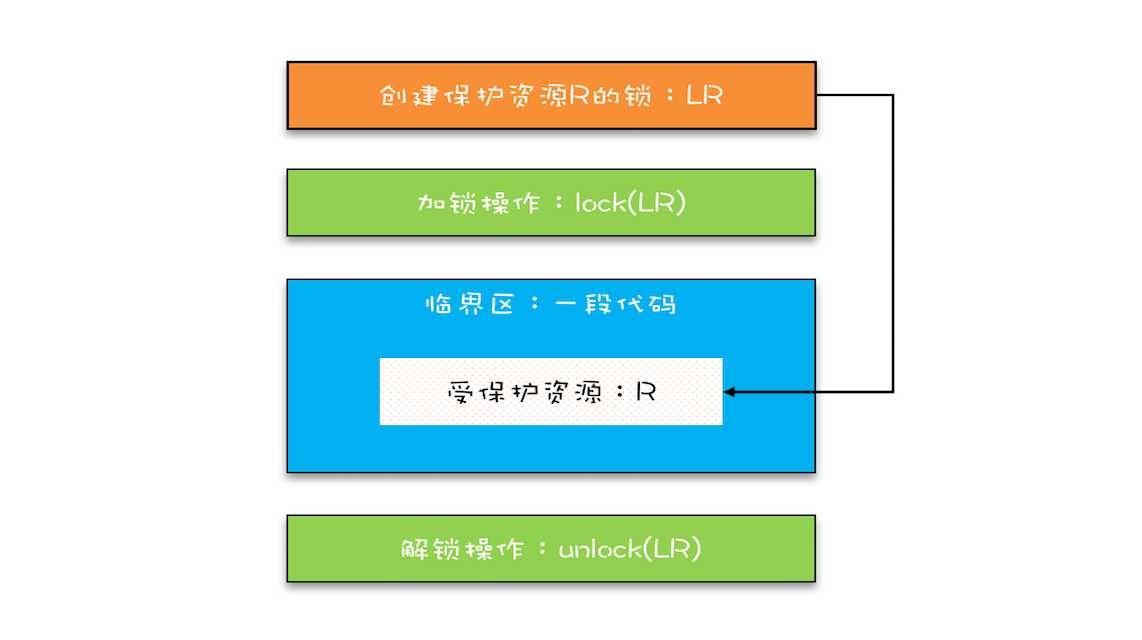
首先,我们要把临界区要保护的资源标注出来,如图中临界区里增加了一个元素:受保护的资源 R;其次,我们要保护资源 R 就得为它创建一把锁 LR;最后,针对这把锁 LR,我们还需在进出临界区时添上加锁操作和解锁操作。另外,在锁 LR 和受保护资源之间,我特地用一条线做了关联,这个关联关系非常重要。很多并发 Bug 的出现都是因为把它忽略了,然后就出现了类似锁自家门来保护他家资产的事情,这样的 Bug 非常不好诊断,因为潜意识里我们认为已经正确加锁了。
Java 语言提供的锁技术:synchronized。锁是一种通用的技术方案,Java 语言提供的 synchronized 关键字,就是锁的一种实现。synchronized 关键字可以用来修饰方法,也可以用来修饰代码块。加锁 lock() 和解锁 unlock() 在哪里呢?其实这两个操作都是有的,只是这两个操作是被 Java 默默加上的,Java 编译器会在 synchronized 修饰的方法或代码块前后自动加上加锁 lock() 和解锁 unlock(),这样做的好处就是加锁 lock() 和解锁 unlock() 一定是成对出现的。
1 class X{ 2 // 修饰非静态方法 3 synchronized void foo(){ 4 //临界区 5 } 6 // 修饰静态方法 7 synchronized static void bar(){ 8 //临界区 9 } 10 // 修饰代码块 11 bject obj = new Object(); 12 void baz() { 13 synchronized(obj){ 14 //临界区 15 } 16 } 17 18 }
那 synchronized 里的加锁 lock() 和解锁 unlock() 锁定的对象在哪里呢?上面的代码我们看到只有修饰代码块的时候,锁定了一个 obj 对象,那修饰方法的时候锁定的是什么呢?这个也是 Java 的一条隐式规则:1、当修饰静态方法的时候,锁定的是当前类的 Class 对象,在上面的例子中就是 Class X;2、当修饰非静态方法的时候,锁定的是当前实例对象 this。
对于上面的例子,synchronized 修饰方法相当于:
class X{ //修饰静态方法 synchronized(X.class) static void bar() { //临界区 }
//修饰非静态方法
synchronized(this) s void foo() { //临界区 } }
分析如下代码是否会带来并发问题
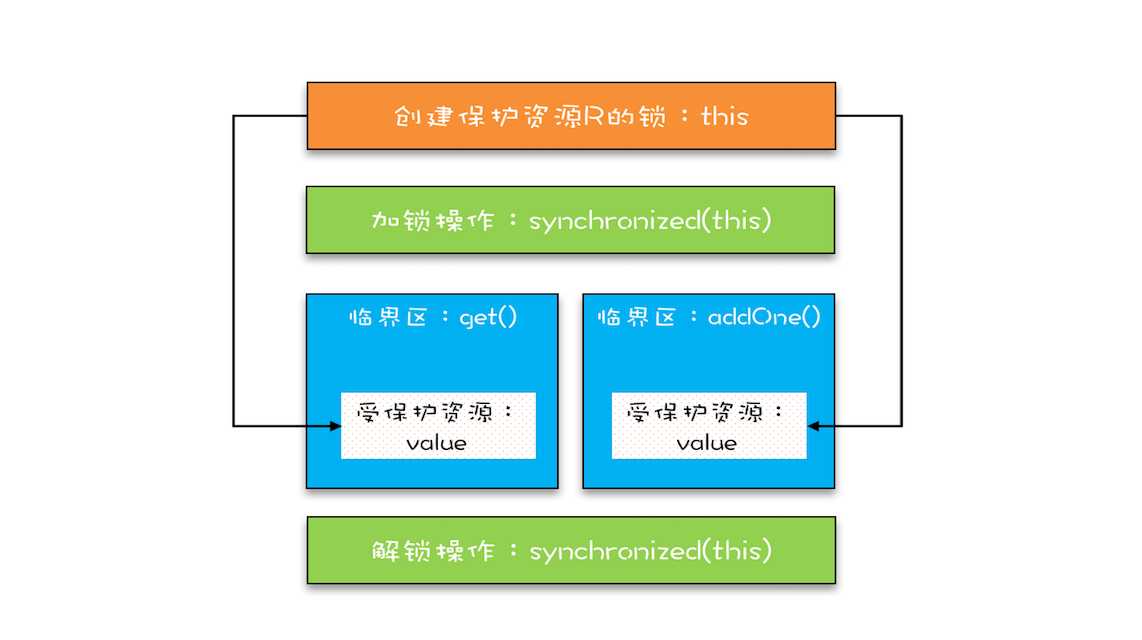
1 class SafeCalc { 2 long value = 0L; 3 synchronized long get() { 4 return value; 5 } 6 synchronized void addOne() { 7 value += 1; 8 } 9 }
不会,原因:我们知道 synchronized 修饰的临界区是互斥的,也就是说同一时刻只有一个线程执行临界区的代码;而所谓“对一个锁解锁 Happens-Before 后续对这个锁的加锁”,指的是前一个线程的解锁操作对后一个线程的加锁操作可见,综合 Happens-Before 的传递性原则,我们就能得出前一个线程在临界区修改的共享变量(该操作在解锁之前),对后续进入临界区(该操作在加锁之后)的线程是可见的。按照这个规则,如果多个线程同时执行 addOne() 方法,可见性是可以保证的,也就说如果有 1000 个线程执行 addOne() 方法,最终结果一定是 value 的值增加了 1000。而get() 方法和 addOne() 方法都需要访问 value 这个受保护的资源,这个资源用 this 这把锁来保护,线程要进入临界区 get() 和 addOne(),必须先获得 this 这把锁,这样 get() 和 addOne() 也是互斥的(指的是两个方法中对共享变量value的读写互斥)。如图:
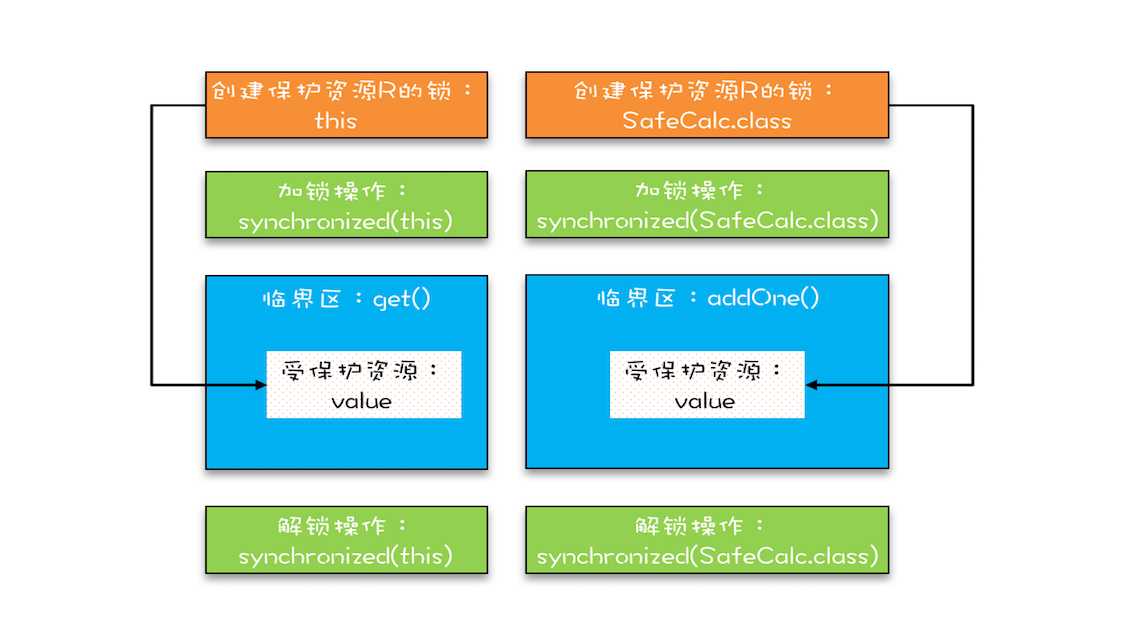
上面例子稍作改动,一个变成静态方法
1 class SafeCalc { 2 static long value = 0L; 3 synchronized long get() { 4 return value; 5 } 6 synchronized static void addOne() { 7 value += 1; 8 } 9 }
思考:此时受保护的资源还是value,而锁变成了两把,两个锁分别是 this 和 SafeCalc.class。两个临界区没有互斥关系,临界区 addOne() 对 value 的修改对临界区 get() 也没有可见性保证,这就导致并发问题了。如图:
思考题:这个使用方式正确吗?有哪些问题呢?能解决可见性和原子性问题吗?
1 class SafeCalc { 2 long value = 0L; 3 long get() { 4 synchronized (new Object()) { 5 return value; 6 } 7 } 8 void addOne() { 9 synchronized (new Object()) { 10 value += 1; 11 } 12 } 13 }
分析:1、加锁本质就是在锁对象的对象头中写入当前线程id,但是new object每次在内存中都是新对象,所以加锁无效。2、两把不同的锁,不能保护临界资源。这个锁会被编译器优化掉。
标签:add zed value 好处 应用 临界区 pos 系统 综合
原文地址:https://www.cnblogs.com/gao1991/p/12105248.html