标签:整数 nta 情况 text 工作量 数组 代码生成 sign 分解
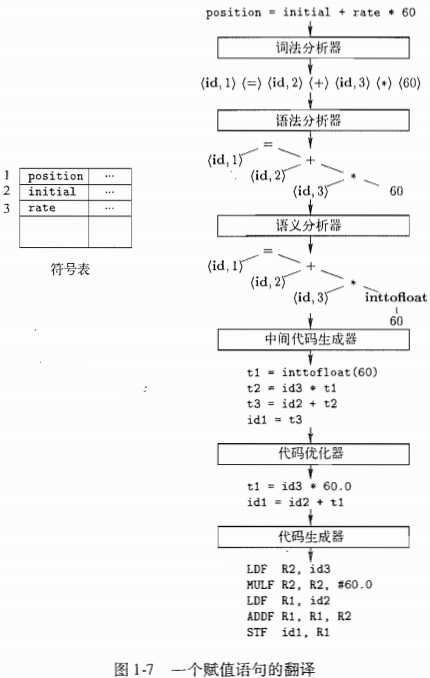
position = initial + rate * 60
词素 词素 词素 词素 词素 词素 词素
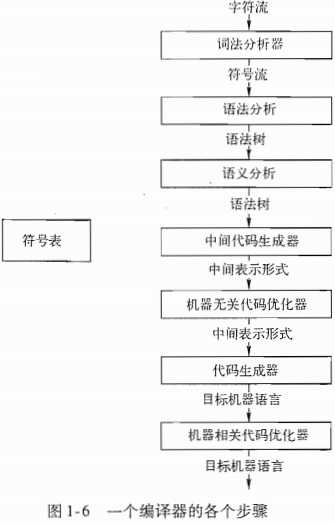
这个赋值语句的字符组合成如下词素,映射成为如下词法单元,这些词法单元被传递给语法分析阶段
经过词法分析后,赋值语句表示成如下的词法单元序列
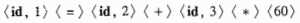
标签:整数 nta 情况 text 工作量 数组 代码生成 sign 分解
原文地址:https://www.cnblogs.com/YC-L/p/12105269.html