标签:temp 结果 func err als 模型 拓扑 dshow 流行
原文地址:https://zhuanlan.zhihu.com/p/21554826
认知神经科学一个非常核心的问题就是解码与编码的问题:信息是怎么在不同的大脑结构被表示的?在不同阶段的处理中,信息是怎么转换的?为了研究这个解码与编码的问题,科学家们发展出了多体素模式分析(MVPA)的技术。
fMRI(功能核磁共振)为我们提供了一个非常好的工具,它可以让被试执行一定的认知任务时测量局部的血流信号(血氧依赖水平,BOLD信号)
 fMRI的成像单位是体素,也就是说我们测量的事每个体素的BOLD信号。简而言之,体素就是三维的像素。
fMRI的成像单位是体素,也就是说我们测量的事每个体素的BOLD信号。简而言之,体素就是三维的像素。
那么多体素模式分析(MVPA)就是用一些分类的机器学习算法,应用在很多很多体素的分析上,从而从大量体素的BOLD信号中解码出来他们表示的信息。
通过对大量体素的分析,我们可以比使用单个体素,或者体素信号平均值等方式更容易的建立分类,而且不会损失太多信息。从下面这图可以比较直观的看出来他的优点:
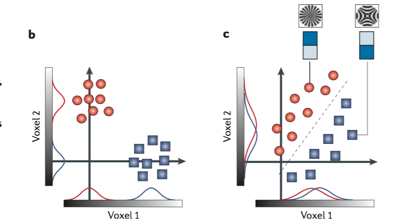
在上面这个图里,有时候只看一个体素的活动模式(比如x,y轴上的曲线代表他们的分布密度)是比较难把他们完全区别开来的,但是如果升高一个维度,画到平面上,就可以很容易的把它们分开了。
1. 解码大脑活动的信息
解码大脑活动也就是 MVPA作为“读心术”最典型的体现了,最为典型的案例就是视觉解码的研究了。
举个例子:
Haxby和他的同事通过对被试颞叶腹侧(VT)的fmri扫描,建立对应的MVPA模型,从而在新的样本中可以推断出来他看到的是鞋子还是瓶子(Haxby et al.,2001)。
Miyawaki通过使用MVPA对初级视觉皮层的解码,我们可以还原出来被试看到的图案(Miyawaki et al., 2008)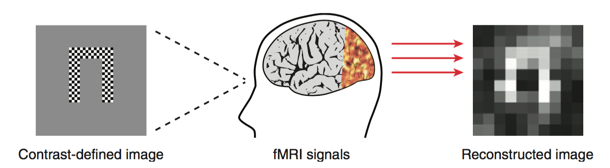
值得注意的是,多体素模式分析由于我们使用的是“多体素”,在一定程度上甚至可以解码一些比体素还小的功能单位(比如初级视觉皮层的功能柱)所包含的信息。
2. 探索大脑的编码机制
在建立多体素模式分析的模型后,我们可以进一步的考量这个MVPA模型中所给予我们的信息。在线性的分类模型中(比如稀疏的对数几率回归)我们可以查看这些体素对这个分类模型的贡献(权值的大小),从而了解这些体素是如何编码这个认知状态的。
举个例子:上面提到过的(Miyawaki et al., 2008),他们建立分类器了以后也分析了权制的分布,也看到了初级视觉皮层(v1)比较明显的视网膜拓扑的性质。
在使用非线性模型(比如非线性的SVM)的时候,我们很难衡量某个体素具体的贡献,我们可以考虑某个脑区的表征精度,从而可以看到这个脑区对于这个具体认知状态的贡献。
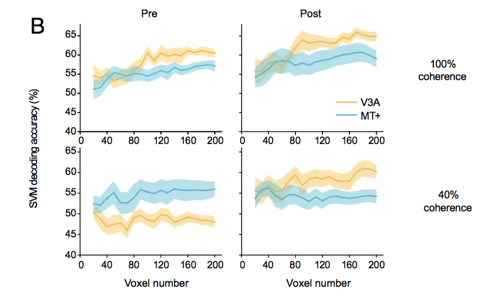
举个例子:方方教授的研究组通过MVPA来衡量知觉学习(Perceptual Learning)中大脑的V3A与MT区域对他的实验任务表征精度的变化,从而验证了他的假说。Perceptual learning modifies the functional specializations of visual cortical areas
1.选择特征(feature selection)
选择特征在多体素分析中,对应的就是选择那些体素进入我们分类器的构建过程。fmri扫描出来的体素可能会数量非常巨大(上万个),如果不加以特征选择,我们分类器的可能会维度远远高于训练集的样本数,很容易造成过拟合,影响我们的结果。
进行特征选择的方式主要有下面几种。
第一种是根据脑区加工、编码信息的既定的理论,去选择一些脑区中的体素进行后续的分析。类似Region of Interest(ROI)的方式
第二种是利用相关性分析的方法,选出对这个任务相关性比较高的体素进入我们的分类器模型。这个方式虽然是比较简单方便的,但是表现上不相关的体素也可能会对分类器有积极的贡献。
第三种是用一些向前或者向后搜索的方式,从一个起点开始(比如从相关系数最高的体素开始),逐个加入体素,观察分类器精度的变化,如果精度提高就保留这个体素,否则就删去这个体素。
但是,无论怎样在进行MVPA的过程中,我们总是很容易遇到维度(特征的数量)高于样本数的情况,因此选择一个稀疏性比较好的分类算法是很有必要的。
2.pattern assembly(这个翻译出来有点奇怪,就不强行翻译了)
这个过程实际上就是统一一下训练集数据的格式,以便于下一步的机器学习算法处理。主要是吧体素的活动按照顺序排成我们需要的矩阵,同时再构建一个标记的矩阵。(这个对机器学习比较熟悉的同学会很容易理解)
3.训练分类器(classifier training)
也就是吧我们训练集的体素活动数据和标记的数据送入机器学习模型进行分类器的训练
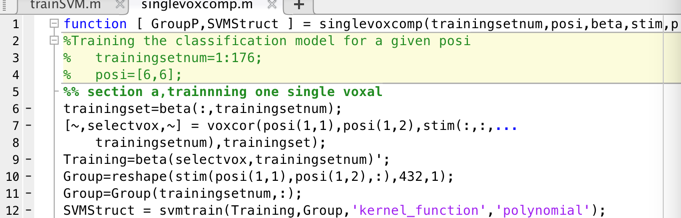 比如像我这样的实际操作,其实有时候也把MVPA的第二步和第三部翻到了一个函数里。
比如像我这样的实际操作,其实有时候也把MVPA的第二步和第三部翻到了一个函数里。
4.泛化测试(generalization testing)
在训练集以外的测试集上运行我们得到的分类模型,并与原来的标记数据进行对比,验证我们这个分类模型的泛化能力。一般常用的就是计算这个模型在测试集上做分类的准确率。
其实在MVPA进行的这四个步骤,是一个比较典型的机器学习模型构建的过程。因此玩转MVPA也是需要一点点机器学习基础的哦。
MVPA是一个目前认知神经科学非常流行的分析手段,越来越多的论文在分析过程中用到了MVPA。现在在分析fMRI数据的时候,我们从简单的看这个脑区有没有“亮”,变成了现在定量的来计算这个脑区对特定信息的表征精度。MVPA这也是机器学习促进脑科学研究的经典案例,利用了这些机器学习的算法,我们就可以从fMRI的实验数据中发掘出更多信息,从而帮助我们了解大脑对信息的编码原理。
ps:我成功构建了一个MVPA的模型,复现过Miyawaki et al., 2008的研究成果,感兴趣的同学可以一起交流MVPA的实际应用,编程思路等问题。
Chen, N et al., (2016). Perceptual learning modifies the functional specializations of visual cortical areas. Proc Natl Acad Sci U S A. doi:10.1073/pnas.1524160113
Haxby, J.V. et al. (2001) Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 293, 2425–2429
Haynes, J. D., & Rees, G. (2006). Decoding mental states from brain activity in humans. Nat Rev Neurosci, 7(7), 523-534. doi:10.1038/nrn1931
Kay, K. N., & Gallant, J. L. (2009). I can see what you see. Nat Neurosci, 12(3), 245. doi:10.1038/nn0309-245
Miyawaki, Y et al., (2008). Visual image reconstruction from human brain activity using a combination of multiscale local image decoders. Neuron, 60(5), 915-929. doi:10.1016/j.neuron.2008.11.004
Norman, K. A et al.,(2006). Beyond mind-reading: multi-voxel pattern analysis of fMRI data. Trends Cogn Sci, 10(9), 424-430. doi:10.1016/j.tics.2006.07.005
标签:temp 结果 func err als 模型 拓扑 dshow 流行
原文地址:https://www.cnblogs.com/lzhu/p/12110477.html