标签:kernel mic blog sdn tps 引入 深度学习 线性变换 决策
吴恩达机器学习:https://www.bilibili.com/video/av9912938/?p=43
有一个很好的文章:https://blog.csdn.net/qq_39422642/article/details/78725278
https://blog.csdn.net/LeviAckerman/article/details/80353135
视频来自:https://www.bilibili.com/video/av38272602/?p=10
SVM的核心是:最大间隔

SVM和其他不同的算法类似的是:都是划分了决策边界。
不同是:决策边界划分的方法不同。
核心思想2:

引入y,把之前的两个式子,合并成一个。这也是个小trick
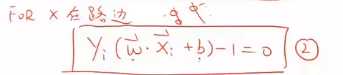
支持向量满足这个式子(式2)。
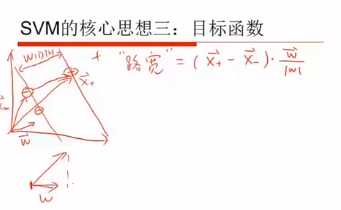
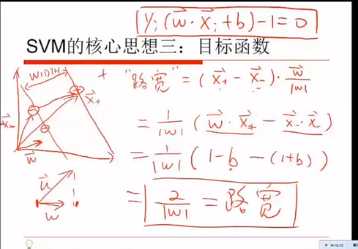
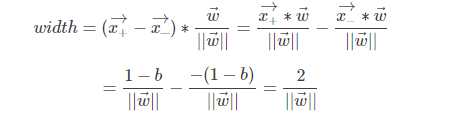
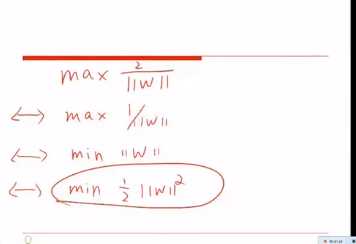



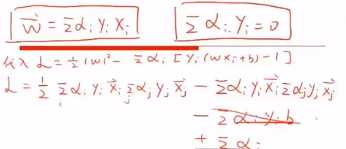
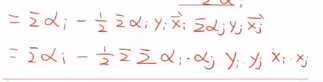
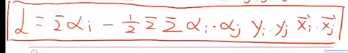
这个式子非常重要!。
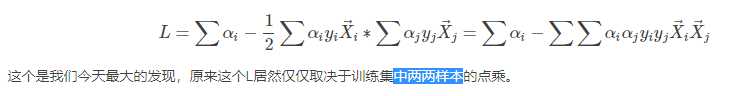
拉格朗日乘子是需要学出来的东西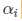
我们不关心x具体为什么,而是关心两个x的点乘。这其实也是一种kernel。
代入决策公式得
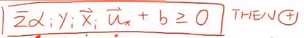
其中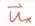 为测试集中的数据。
为测试集中的数据。
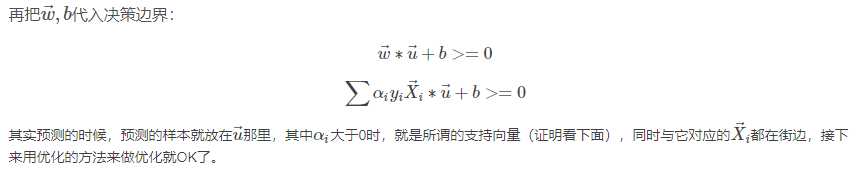
测试集的点和路边的点两两乘内积,求完内积再求加权的和,如果>0,则为+。这就是最简单的SVM的形式。
当不为0时,Xi就不是路边的点了。只有为0时,才是路边的点。
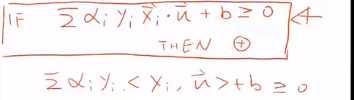
求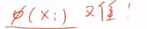 核函数太难了。
核函数太难了。
但是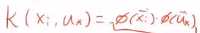 可以求出来。
可以求出来。
因为两两点乘为一个常数,所以k是一个线性函数。
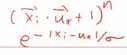
上面的是多项式核,下面的为高斯(RBF)核
在建模的时候,我们只需要知道核函数是什么,而不需要非线性变换的函数是什么。
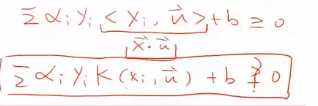
这样我们就把上面的式子转化成了下面的式子。
现在就剩下一个问题:如何求
有了,就会有w,b。
题外话:SVM的所有优化都是凸优化。深度学习的时候,达到局部最优就可以了。不一定非要全局最优。
SMO如何做的?
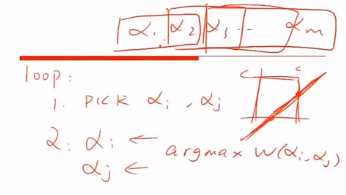
每次固定2个变量,求极值,依次迭代。
标签:kernel mic blog sdn tps 引入 深度学习 线性变换 决策
原文地址:https://www.cnblogs.com/JasonPeng1/p/12110139.html