标签:产生 inf alt 个数 完成 列表 过程 数据结构 多层
我们先抛开redis,单独了解下跳越表
skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。
我们先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:


利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:
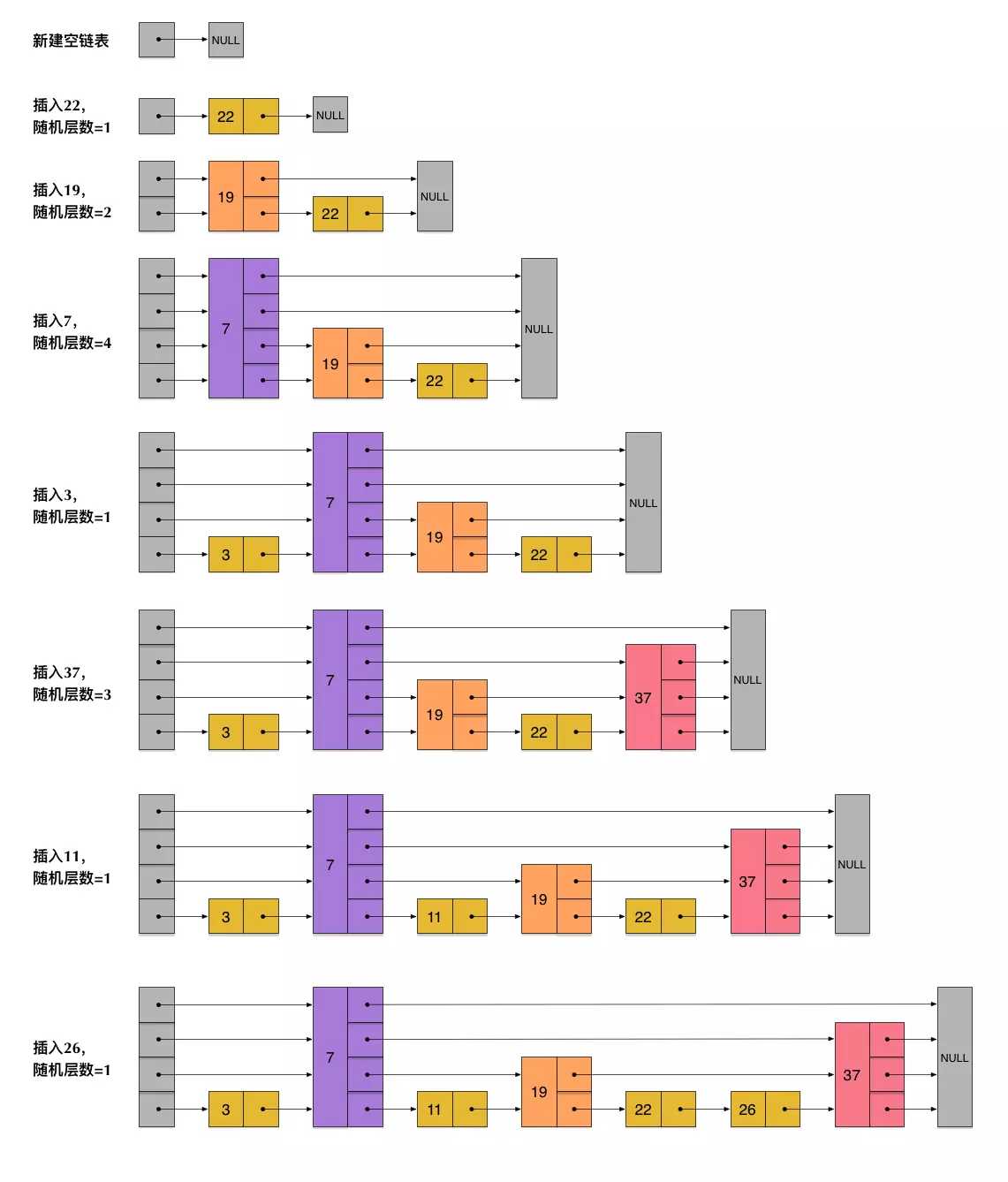
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
根据上图中的skiplist结构,我们很容易理解这种数据结构的名字的由来。skiplist,翻译成中文,可以翻译成“跳表”或“跳跃表”,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:
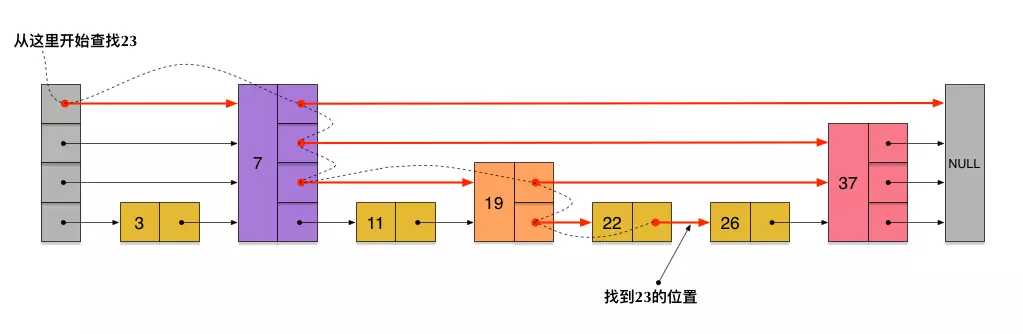
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
至此,skiplist的查找和插入操作,我们已经很清楚了。而删除操作与插入操作类似,我们也很容易想象出来。这些操作我们也应该能很容易地用代码实现出来。
当然,实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key进行排序的,查找过程也是根据key在比较
标签:产生 inf alt 个数 完成 列表 过程 数据结构 多层
原文地址:https://www.cnblogs.com/zh718594493/p/12111949.html