标签:bin grep find send line 正则表达 意思 命令执行 路径
1. 正则表达式的基本流程
2. 正则表达式语法规则
3. 正则表达式的使用
?3.1基本使用
?3.2分组
?3.3断言
4.IP匹配
5. grep 命令中使用正则
?grep基本用法
?grep 正则表达例子
语言作为人们表达思想的载体,我们在平时的编程中要进行大量的字符串操作。正则表达式用在字符串处理中极其的方便,可以随心所欲的表示我们想要字符串的模式,可以说是字符串处理的一大杀器,此刀在手,所向披靡,任何字符串的问题都可轻松的化解。
正则表达式作为处理字符串强大的工具,像定义的编程语言一样,具有自己独特的语法和处理引擎,在提供正则表达式的语言里,正则表达式的语法是一样的,如果有区别,那也仅仅是支持语法的数量不同,c/c++,python,java都是支持正则表达式的,当然在grep命令中也可用正则表达式。正则表达式的匹配流程如下:
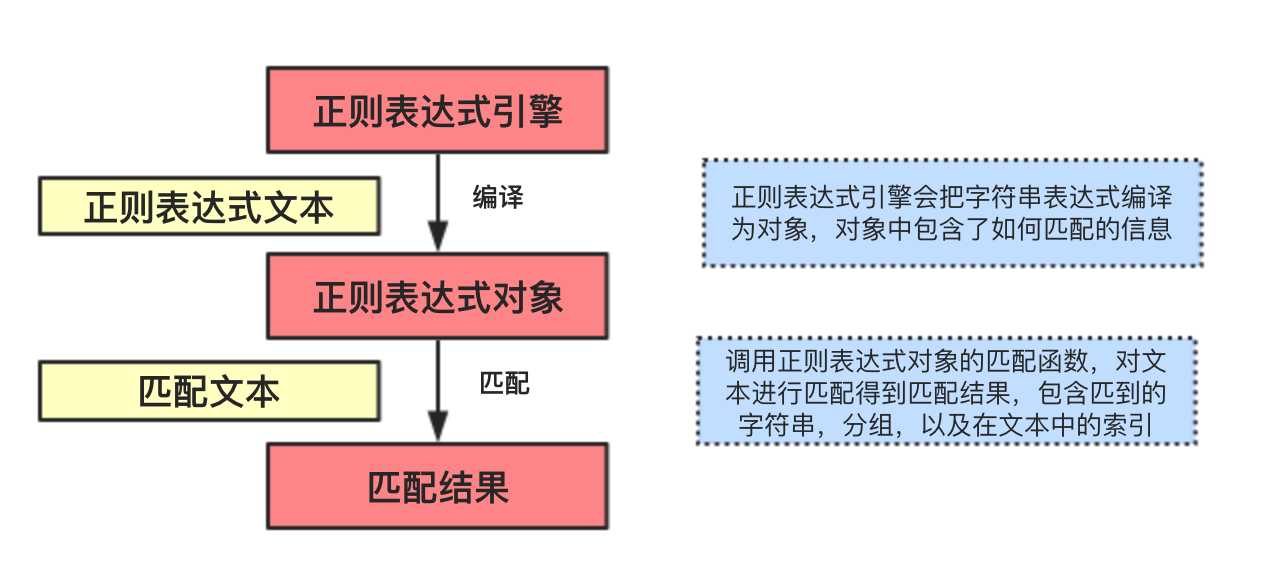
图1 正则表达式的基本流程
正则表达式的匹配过程中,像贪吃蛇一样(正则表达式是蛇,吃字符串并且很贪婪),依次的拿出表达式和匹配文本中的字符比较。如果每一个字符都能匹配成功表示匹配成功,否则失败。
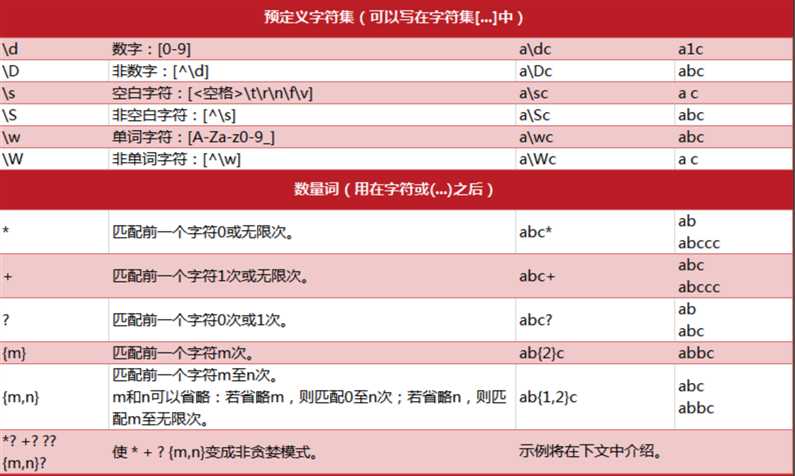
正则表达式有自己的语法规则,他的基本元素就是字符,为了处理多个字符的逻辑,定义标准字符集,用\d,\s,\w等特殊字符表示字符集,同时使用分组的形式支持自定义字符集。在表达逻辑方面定义了字符个数的表示,界定符,分组,断言等逻辑表示。使用字符和逻辑这些基本语法,就可以组合出丰富的匹配方式,足够处理任意复杂的逻辑。
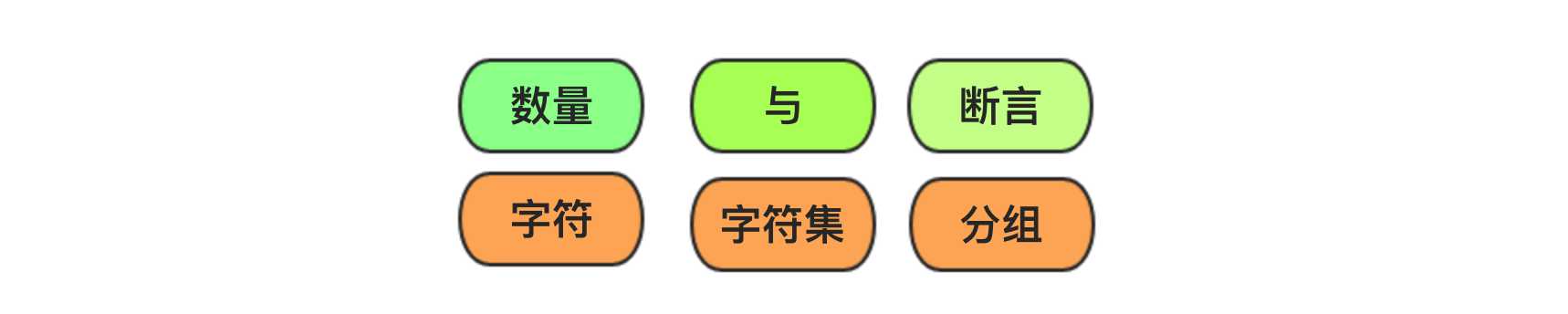
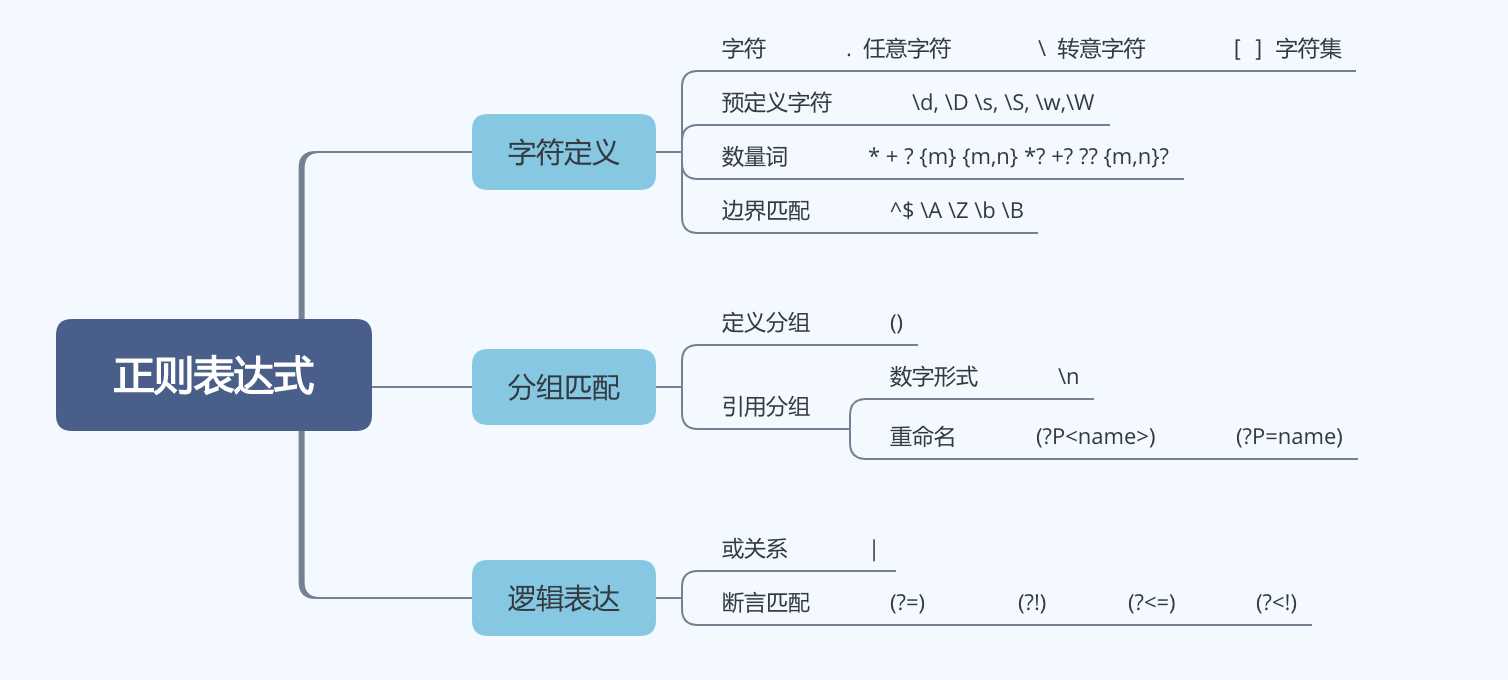
图2 正则表达式的语法表示
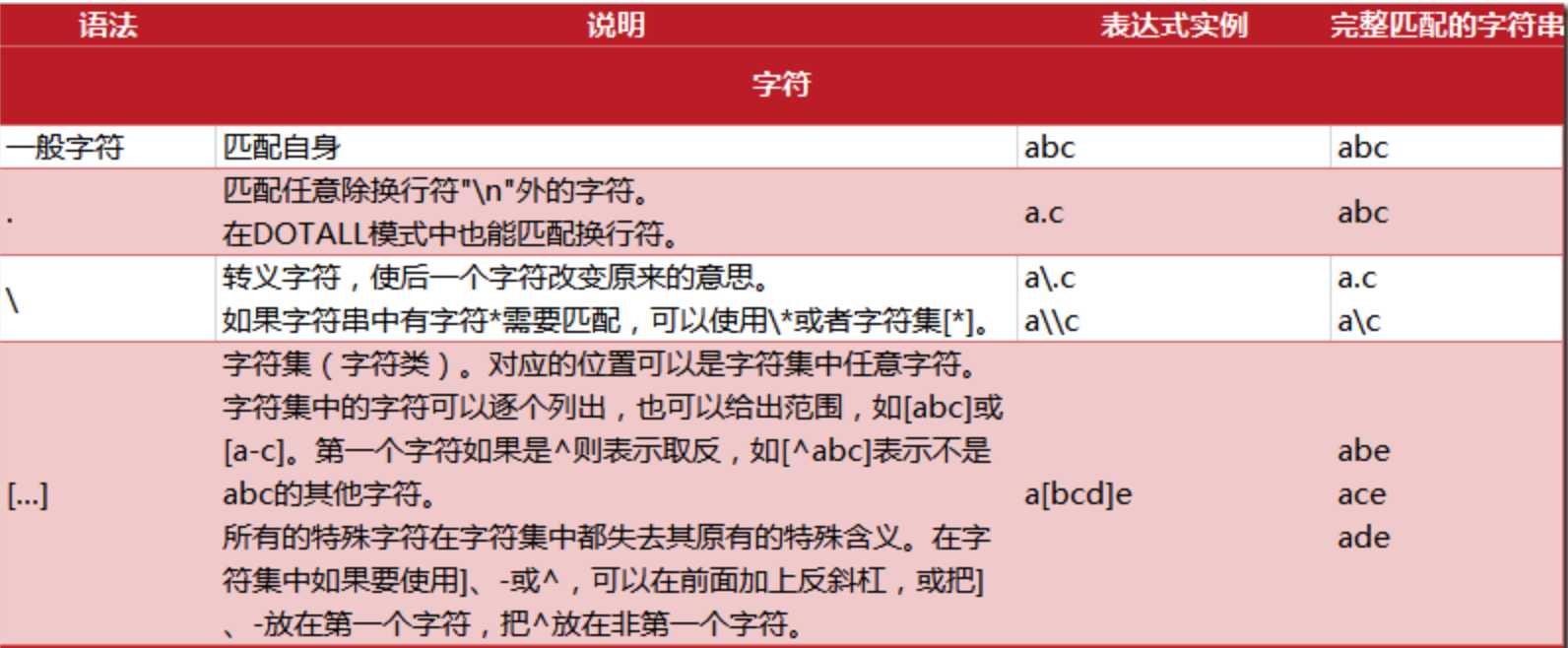
上面的\b表示是一个单词边界匹配的位置,单词字符后面或前面不与另一个单词字符直接相邻。

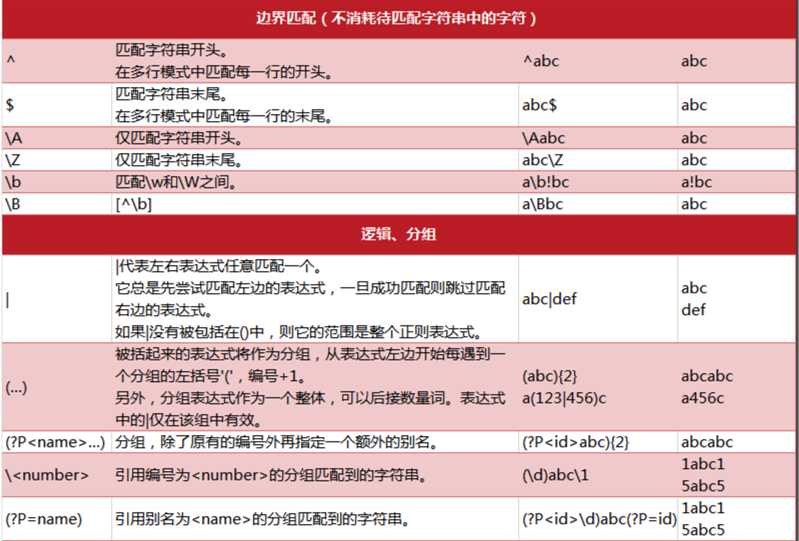
如图所示,箭头所指的都是边界。小数点的左右都会有单词边界,这意味着单词边界不仅仅是英文字母,还包括数字。也就是说只要不是连续的字符或数字两边都是界定符。
\B的表示, 一个非单词边界. 正则表达式\Bend\w*\b匹配字符串"end sends endure lender"的匹配结果是 ends和ender。

序号1 中使用了\d\s两种标准的字符限定集,\d匹配数字,\s匹配空字符,{3},{3,8}表示匹配数量的限定,匹配3个字符,匹配3-8个字符,数字的限定对上一个匹配基本元素起作用,\d{3}表示匹配任意的三个数字,a{3}表示匹配3个a,(){3}表示匹配前面的分组三次。匹配的结果238,可以看出匹配的过程,像是TCP的滑动窗口算法,依次的在匹配字符串上滑动匹配规则,判定是否匹配。
序号2 展示了贪婪匹配算法,总是尽可能多的匹配。
序号3 展示了分组匹配,在正则表达式子中定了了两个分组,使用了分组的捕获模式,捕获了匹配的相应分组‘000‘,‘323456‘
序号4 展示了,非贪婪匹配。非贪婪匹配在匹配规则后面加?,总是尝试匹配尽可能少的字符。正常模式下正则表达式"ab",用于匹配字符串"abbbc",将会匹配"abbb".如果使用非贪婪模式"ab?",将返回a。
序号5 展示了使用[]自定义字符集和""反斜杠的转义字符的用法。[]定义需要的字符集。
序号6展示了限定符的作用。^用于限定开头,$用于限定表达式的结尾.<\b>
从上面的例子中我们已经定义了分组,分组是用"()"括起来的正则表达式,可以用"|“连接多个分组,用于表达或逻辑,它总是先匹配左边的表达式,匹配成功就跳过后面的表达式。也可以在括号内使用,|的两侧是两个分组。一般情况下,分组即捕获,可以在匹配结果中,获取捕获的字符串,上面的例子三种就捕获了两个分组,分别是(‘000‘, ‘323456‘) 。
分组的定义有两种三种形式:
定义分组
#普通分组
reg1 = r'^(\d{3})-(\d{3,8})$'
#匹配分组但不捕获
reg2 = r'(?:\d{3})-(\d{3,8})$'
str1 = '010-12345'
match_oper(reg1, str1) # ('010', '12345')
match_oper(reg2, str1) # ('12345',)引用分组
#分组引用,严格的匹配上一个分组捕获的内容
reg1 = r'(\d{3})-\1'
#分组指定别名
reg2 = r'(?P<name1>\d{3})-(?P=name1)'
str1 ='010-010'
str2 ='010-011'
match_oper(reg1, str1) #匹配,group ('010',)
match_oper(reg1, str2) #不匹配
match_oper(reg2, str1) #匹配,group ('010',)
match_oper(reg2, str2) #不匹配
reg3 = r'<(?P<name1>\w*)><(?P<name2>h[1-5])>.*</(?P=name2)></(?P=name1)>'
str3 = '<html><h1>www.baidu.com</h1></html>'
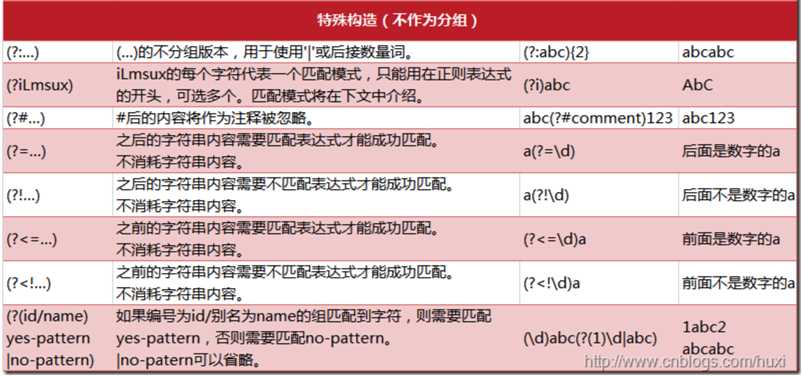
match_oper(reg3, str3) # ('html', 'h1')断言正如它的名字一样,是一种零宽度的匹配,它匹配的内容不会保存到匹配结果中,也就是不消耗字符串的内容,表达的结果如c语言中的assert。它的作用是给指定的位置,添加一个限定条件,用来规定此位置之前之后的字符必须满足条件才能使正则表达式匹配成功。断言又分为正向断言和负向断言。
s1='''char *a="hello world"; char b='c'; /* this is comment */ int c=1; /* this is multiline comment */'''
print re.findall( r'(?<=/\*).+?(?=\*/)' , s1 ,re.M|re.S)
#匹配结果[' this is comment ', ' this is multiline comment ']上面的例子展示了正向和负向断言,用于匹配代码中的注释。
reg1 = r"\d{0,3}.\d{0,3}.\d{0,3}.\d{0,3}"
reg2 = r'((2(5[0-5]|[0-4]\d))|([0-1]?\d{1,2}))'
reg3 = r'(2(5[0-5]|[0-4]\d))|(1\d{1,2})|([1-9]\d(?!\d))|(\d(?!\d))'首先写reg1能匹配三个数字,但是不能满足IP地址每个字段小于255的要求。因此分别对2,1,0开头的数字使用与逻辑做处理得到reg2.但是reg2能匹配"01"之类的字符串,于是做进一步的划分,分别针对2,1,2个字符,1个字符的情况分别处理。
匹配整个IP
reg8 = r'((((2(5[0-5]|[0-4]\d))\.)|(1\d\d\.)|([1-9]\d\.)|(\d\.)){3}((2(5[0-5]|[0-4]\d))|1\d\d|([1-9]\d(?!\d))|(\d(?!\d))))'
match_ip_ope(reg8, "100.11.1.11") #匹配
match_ip_ope(reg8, "256.11.1.11")#不匹配
match_ip_ope(reg8, "100.01.01.11")#不匹配
match_ip_ope(reg8, "100.1111.1.11")#不匹配
match_ip_ope(reg8, "100.0.1.11")#匹配
match_ip_ope(reg8, "255.255.255.255")#匹配上面得到了针对IP的单个位置的匹配规则,因为前三个位置都包含".",所以前面三个匹配的规则相同,加上数量限定{3}即可。后面的一个只需要使用单位匹配规则就可以了。
grep [-acinv] [--color=auto] [-A n] [-B n] '搜寻字符串' 文件名‘搜寻字符串‘是正则表达式,为了避免shell的元字符对正则表达式的影响,请用单引号(‘‘)括起来,千万不要用双引号括起来("")或者不括。
参数说明:
-a:将二进制文档以文本方式处理
-c:显示匹配次数
-i:忽略大小写差异
-n:在行首显示行号
-w: 精确匹配
-A:After的意思,显示匹配字符串后n行的数据
-B:before的意思,显示匹配字符串前n行的数据
-v:反向搜索,显示没有匹配行
-e 指定正则表达式来
-E: 以扩展的正则表达式的模式来解释模式
--color:以特定颜色高亮显示匹配关键字# grep -i '^[Ss]' /proc/meminfo# grep -v '/sbin/nologin$' /etc/passwd | cut -d: -f1# grep '/bin/bash$' /etc/passwd | cut -d: -f1 | sort -n -r | head -1# grep '\<[[:digit:]]\{1,2\}\>' /etc/passwd# grep '^[[:space:]]\+.*' /boot/grub/grub.conf# grep '^#[[:space:]]\+[^[:space:]]\+' /etc/rc.d/rc.sysinit# netstat -tan | grep 'LISTEN[[:space:]]*$# grep '\(\<[[:alnum:]]\+\>\).*\1$' /etc/passwdHe like his lover.
He love his lover.
He like his liker.
He love his liker.找出其中最后一个单词是由此前某单词加r构成的行;
# grep '\(\<[[:alpha:]]\+\>\).*\1r' grep.txt# grep -E '^(root|centos|user1\>)' /etc/passwd# grep -o '\<[[:alpha:]]\+\>()' /etc/rc.d/init.d/functions# echo /etc/rc.d/ | grep -o '[^/]\+/\?$' | grep -o '[^/]\+'标签:bin grep find send line 正则表达 意思 命令执行 路径
原文地址:https://www.cnblogs.com/linengier/p/12112652.html