标签:gen cbo 16px lin 预测 出现 阅读 生成 理解
概述:
UniLM是微软研究院在Bert的基础上,最新产出的预训练语言模型,被称为统一预训练语言模型。它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,Unilm在抽象摘要、生成式问题回答和语言生成数据集的抽样领域取得了最优秀的成绩。
一、AR与AE语言模型
AR: Aotoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等。
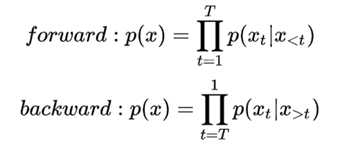
AE:Autoencoding Language Modeling,又叫自编码语言。通过上下文信息来预测当前被mask的token,代表有BERT ,Word2Vec(CBOW)。
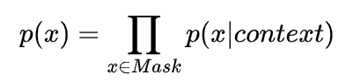
AR 语言模型:
AE 语言模型:
论文阅读总结:UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)
标签:gen cbo 16px lin 预测 出现 阅读 生成 理解
原文地址:https://www.cnblogs.com/gczr/p/12113434.html