标签:个人 不同 返回 排除 sample dataframe 默认 包含 条件
# 导入 random(随机数) 模块 import random ‘‘‘ 使用random 模块的 randint() 函数来生成随机数 语法是:random.randint(a,b) 函数返回数字 N , N 为a到b之间的数字(a <= N <= b),包含 a 和 b 下面案例是生成0 ~ 9 之间的随机数, 你每次执行后都返回不同的数字(0 到 9) ‘‘‘ a=random.randint(0,9) print(a)
range() 函数可创建一个整数列表,一般用在 for 循环中。 使用语法: range(start, stop[, step]) 参数说明: start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5) start: 计数从 start 开始,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5 step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
‘‘‘ 抽奖:生成多个随机数 应用案例:从395个用户中随机抽取10个人作为中奖者 ‘‘‘ for i in range(10): userId=random.randint(0,395) #用%s格式化字符串 print(‘第 %s 位获奖用户id是 %s‘ % (i,userId) )
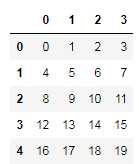
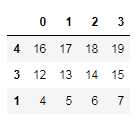
‘‘‘ #arange产生一个含有5*4个元素的一维数组 reshape:将数组转换成5行4列的二维数组 ‘‘‘ df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4))) df
#随机选择一个n行的子集 sample1=df.sample(n=3) sample1
中心极限定理,是指概率论中讨论随机变量序列部分和分布渐近于正态分布的一类定理。
这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量近似服从正态分布的条件。
1、样本的平均值约等于总体平均值
2、不管是什么分布、任意一个总体的样本平均朱都会围绕在总体平均值的周围,并且呈正态分布
三、用样本评估总体
样本的数量较总体较少,因此有可能把极端值排除在外(样本的标准差<总体标准差)

目的:样本标准差是用来估计总体标准差

1、样本偏差:很少的数据得出结论,以偏概全
2、幸存者偏差:通常只关注显而易见的样本,忽视没有机会出现的样本
3、概率偏见:自以为位置的概率,心里概率与实际的概率的偏差
4、信息茧房:个性化推荐
信息茧房其实是现在社会一个很可怕的现象,从字面意思来看的话其实比喻的是信息被虫茧一般封锁住。
这个问题反映了现在随着个性化推荐的普及衍射的一个社会问题。

1
标签:个人 不同 返回 排除 sample dataframe 默认 包含 条件
原文地址:https://www.cnblogs.com/foremostxl/p/12112967.html