标签:des style blog class c http
给定一个样本集T
样本总数为m
每个样本记做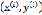
其中 为输入变量,也称为特征变量;
为输入变量,也称为特征变量; 为我们要预测的输出变量,也称为目标变量
为我们要预测的输出变量,也称为目标变量
 表示第
表示第 个样本。
个样本。
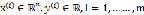
给定一个样本集,学习一个函数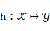 使得
使得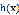 是对相应y的一个好的预测。
是对相应y的一个好的预测。
因为某些历史原因,h被称为假设(hypothesis)。
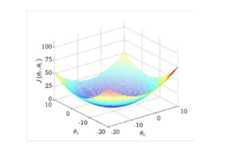
整个过程如下图所示:
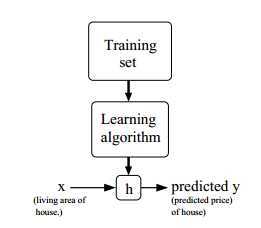
如果我们想要预测的目标变量是连续值,称为回归问题(regression);
当目标变量是少数离散值时,称为分类问题(classification)。
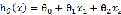
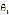 是线性函数的参数(parameters)。
是线性函数的参数(parameters)。
为了使我们的标记更简单,我们添加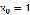 项:
项:
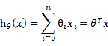
我们要使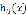 尽可能的靠近y
尽可能的靠近y
定义一个函数来度量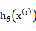 与相应
与相应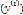 之间的距离,称为代价函数(cost
function)
之间的距离,称为代价函数(cost
function)
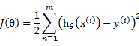
代价函数就是最小二乘(OLS ordinary least squares )
使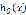 尽可能的靠近y,也就是选择
尽可能的靠近y,也就是选择 最小化
最小化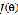 。
。
首先始化一个随机的 ,然后重复的执行以下操作来更新
,然后重复的执行以下操作来更新 :
:
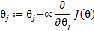
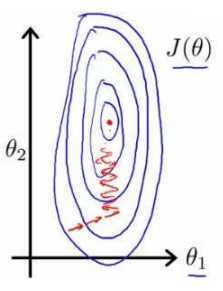
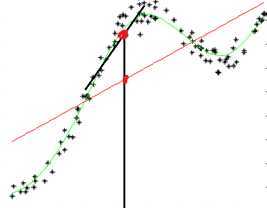
脑补如下前景:你从山上往山谷走,每一步在x轴方向走α长度,每走一步前向四周张望,选择最陡的方向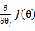 走。
走。
继续脑补:α大时,你很快就跑下山,但说不定就跨过全局最小值;α大时,下山需要花很长时间,但会更好的收敛于最小值。
对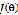 求偏导,假设只有一个训练样本时:
求偏导,假设只有一个训练样本时:
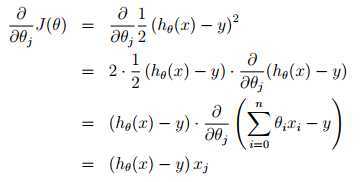
所以可以得到更新策略:
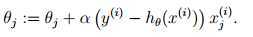
被称为LMS(least mean squares)更新策略,也称为Widrow-Hoff学习策略(Widrow Hoff 1960)
根据LMS更新策略,得到以下算法:
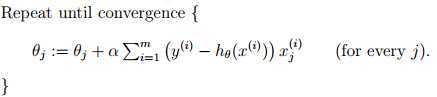
这个算法的特点是每此迭代都会查看所有的样本,所以被称为批梯度下降(batch gradient descent)
与批梯度下降算法相比,下面的算法每次迭代只查看一个样本:
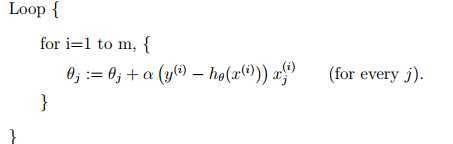
被称为随机梯度下降(stochastic gradient descent also incremental gradient descent)
当样本集比较大时,随机梯度下降比批梯度下降更快接近最小值,但随机梯度下降会在最小值附近徘回,而不会收敛于最小值。如果你在迭代的过程中减小α,随机梯度下降同样会收敛于最小值。
实际中,每个接近最小值都是可用的,有些值的泛化误差甚至小于最优值。
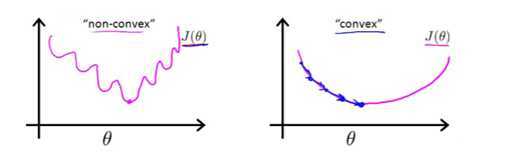
一般来说,梯度下降算法不能保证收敛于全局最优点。但如果目标函数是凸的(Convex),可以保证收敛于全局最优点。
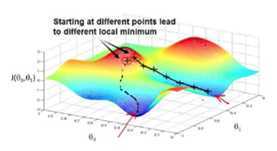
过程如图,自行脑补:
特征放缩(Feature Scaling)
保证特征有相近的尺度会帮助梯度下降算法更快收敛。如图,自行脑补:
最常用的方法是正规化:
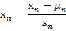
其中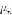 是平均值,
是平均值, 是标准差
是标准差
如何确定收敛,如何确定α?
绘制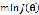 与迭代次数的关系图观测算法在何时趋于收敛
与迭代次数的关系图观测算法在何时趋于收敛
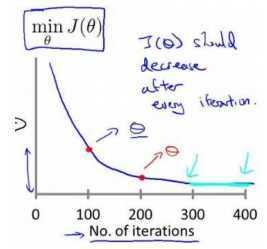
自动测试是否收敛的方法,例如将代价函数的变化直与某个阀直(例如0.001)进行比较,但通常看上面这样的图表更好。
梯度下降算法的每次迭代受到学习率的影响,如果学习率α过小,则达到收敛所需的迭代次数会非常高;如果学习率α过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试这些学习率:
α=0.01,0.3,0.1,0.3,1,3,10
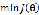 有直接解法:求导,令导数为零
有直接解法:求导,令导数为零
求解过程见cs229 Lecture notes,使用Matrix derivatives和trace operator简化了运算
比较喜欢这句"Armed with the tools of matrix derivatives, let us now proceed to find in closed-form the value of θ that minimizes J (θ)."
最终得到normal equations:
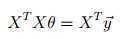
如果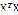 可逆,有如下解:(不可逆请用伪逆)
可逆,有如下解:(不可逆请用伪逆)
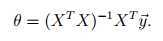
normal
equations可以直接得到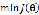 的解,不用担心gradient
descent没有收敛的问题
的解,不用担心gradient
descent没有收敛的问题
normal equations中求逆的过程非常耗时,而gradient descent对于特征数量n较大问题常常速度比normal equations快
gradient descent有个好处是可控:时间比较有限,设置一个比较大的α少跑几圈;时间比较充裕,设置一个比较小的α多跑几圈;对现在的值不满意可以接着跑
n小于10000考虑用Normal equations
如果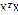 矩阵不满秩,或者其他数值解不稳定的情况(线性相关),则可以使用下面的解:
矩阵不满秩,或者其他数值解不稳定的情况(线性相关),则可以使用下面的解:
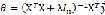
岭回归的算法通过最小化带惩罚项的代价函数:
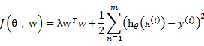
参数 在最小化
在最小化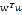 与最小化误差平方和之间起到平衡作用
与最小化误差平方和之间起到平衡作用
梯度下降不存在这种问题
可以添加高次项,或者自行构造有些特征使线性回归可以做拟合出非线性函数出来
比如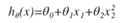
再比如考虑通过把房屋长度和宽度相乘构造房屋面积特征
后面会专门开辟一章讲模型选择
为什么最小二乘法最为代价函数?
假设样本来自某未知的过程:
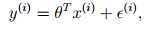
其中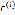 项捕捉了建模的参数对输出的影响,和随机噪音。
项捕捉了建模的参数对输出的影响,和随机噪音。
假设:(个人感觉这样的假设还是比较合理的)
1.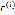 独立同分布(IID
independently and identically distributed)
独立同分布(IID
independently and identically distributed)
2.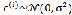
也就是:
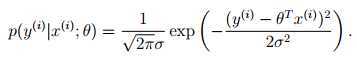
 标记指
标记指 不是随机变量,而是真实存在,未被发现的值。
不是随机变量,而是真实存在,未被发现的值。
用极大似然估计法(Maximum Likehood
Estimate)对 进行估计:
进行估计:
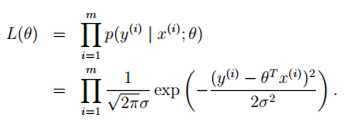
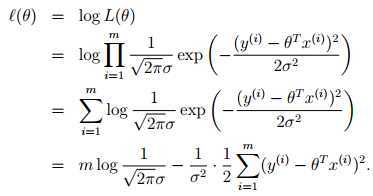
最大化?(θ)等价于最小化代价函数:
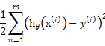
以上的假设( 独立同分布,
独立同分布,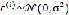 )不是最小二乘法的必要条件。
)不是最小二乘法的必要条件。
充分必要条件来自Gauss–Markov theorem。这个定理同时有多个等价版本。。
考虑一下四组数据(F.J. Anscombe 1973)
|
一 |
x |
10 |
8 |
13 |
9 |
11 |
14 |
6 |
4 |
12 |
7 |
5 |
|
y |
8.04 |
6.95 |
7.58 |
8.81 |
8.33 |
9.96 |
7.24 |
4.26 |
10.84 |
4.82 |
5.68 | |
|
二 |
x |
10 |
8 |
13 |
9 |
11 |
14 |
6 |
4 |
12 |
7 |
5 |
|
y |
9.14 |
8.14 |
8.74 |
8.77 |
9.26 |
8.1 |
6.13 |
3.1 |
9.13 |
7.26 |
4.74 | |
|
三 |
x |
10 |
8 |
13 |
9 |
11 |
14 |
6 |
4 |
12 |
7 |
5 |
|
y |
7.46 |
6.77 |
12.74 |
7.11 |
7.81 |
8.84 |
6.08 |
5.39 |
8.15 |
6.42 |
5.73 | |
|
四 |
x |
8 |
8 |
8 |
8 |
8 |
8 |
8 |
19 |
8 |
8 |
8 |
|
y |
6.58 |
5.76 |
7.71 |
8.84 |
8.47 |
7.04 |
5.25 |
12.5 |
5.56 |
7.91 |
6.89 |
进行线性回归,得到相同的直线方程(你这是在逗我)
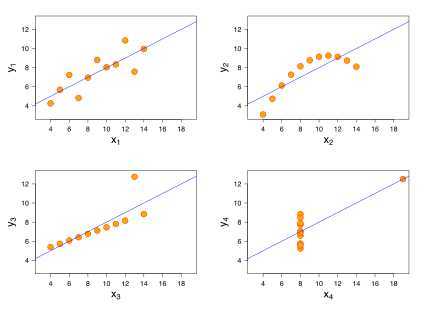
第一组数据是大多人看到上述统计数字的第一反应,是最"正常"的一组数据;
第二组数据所反映的事实上是一个精确的二次函数关系,只是在错误地应用了线性模型后,各项统计数字与第一组数据恰好都相同;
第三组数据描述的是一个精确的线性关系,只是这里面有一个异常值,它导致了上述各个统计数字,尤其是相关度值的偏差;
第四组数据则是一个更极端的例子,其异常值导致了平均数、方差、相关度、线性回归线等所有统计数字全部发生偏差。
所以请不要滥用线性回归,以及其他机器学习算法。拿到数据的第一件事就是把数据绘来。
正态性检验
直方图,排列图/柏拉图,概率纸图,Q-Q图,P-P图等有时间再做整理
[请善用excel,最强大的数据分析工具,没有之一]
1.学习θ ,使得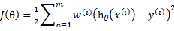 最小化,其中权重
最小化,其中权重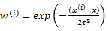
2.输出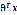
non-parametric algorithm 非参数算法(为了做预测,须存储东西的数量随着样本数量的增加而线性增加)
预测阶段需要整个样本集
如果样本离x较远,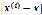 较大,
较大,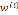 接近于0;如果样本离x较近,
接近于0;如果样本离x较近,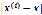 较小,
较小,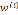 接近于1。
接近于1。
τ控制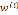 随样本与x的距离下降的多快,称为带宽参数(bandwidth)
随样本与x的距离下降的多快,称为带宽参数(bandwidth)
1. Supervised Learning - Linear Regression,布布扣,bubuko.com
1. Supervised Learning - Linear Regression
标签:des style blog class c http
原文地址:http://www.cnblogs.com/noooop/p/3731032.html