标签:illegal 针对 写法 获取 swap code 添加元素 时间 ide
优先队列:出队顺序和入队顺序无关,而是和优先级有关(优先级高的先出队)
如果使用普通线性结构或者顺序线性结构实现优先队列,出队或者入队总有一方是O(n)级别的;如果使用堆实现优先队列,能使入队和出队的时间复杂度都是O(logn),效率是极高的。
二叉堆是一颗完全二叉树,不一定是满二叉树,但是确实节点的那部分一定是在整棵树的右下侧。满足的规律:1)根节点最大, 2)确实节点的那部分在整棵树的右下侧。(低层次的节点不一定大于高层次的节点)
下图是一颗最大堆:
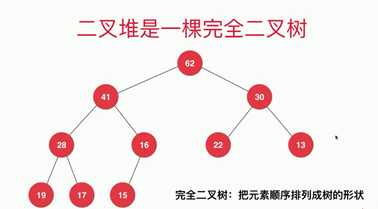
可以用数组存储:

从数组1位置开始存储:
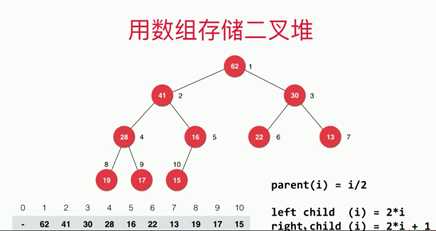
从数组0位置开始存储:
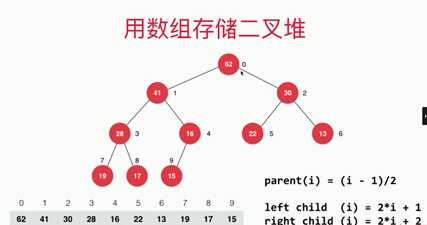
最大二叉堆可用于正数数组从大到小排序,100万的数据排序只需要1秒多。
1)添加元素和siftUp:添加后和父节点进行比较,如果大于父节点,则与父节点交换,并再次与父节点交换直到不大于父节点(也叫元素上浮sift up)
2)取出元素和siftDown:a、取出元素只能取出index=0位置处的最大元素,另外siftDown的思路:b、数组最后一个位置的元素移动到0的位置,然后对该元素进行siftDown:c、和两个孩子中最大的元素进行比较,d、如果小于两个孩子中的最大元素,则和该最大元素交换位置,e、并改变索引位置进行下一次递归调用。
3)heapify和replace
replace:取出堆中的最大元素后,再加入一个新元素
heapify:将任意数组整理成堆的形状
1) 基于堆实现优先队列
2) 具体问题编程:给定一个正数数组,返回其中出现频率前k高的元素:
例如:
给定数组[1,1,1,2,2,3],和k=2,返回[1,2];
最大二叉堆实现如下package heapimport array.Array;/*
* 从数组下标0的位置开始存放数据
* 利用最大二叉堆堆100万的随机正数进行从大到小的排序,仅需1秒多,效率是极高的
* */
public class MaxHeap<E extends Comparable<E>> {
private Array<E> data;
public MaxHeap(int capacity){
data = new Array<>(capacity);
}
public MaxHeap(){
data = new Array<>();
}
public int getSize(){
return data.getSize();
}
public boolean isEmpty(){
return data.isEmpty();
}
//寻找父元素的位置
private int parentIndex(int index){
if(index <= 0){
throw new IllegalArgumentException("index is illegal.");
}
return (index - 1)/2;
}
//寻找左子元素的位置
public int leftIndex(int index){
return 2*index+1;
}
//寻找右子元素的位置
public int rightIndex(int index){
return 2*index + 2;
}
//添加元素,需要调用元素上浮方法,元素上浮方法中需要调用交换元素的方法
public void add(E e){
data.addLast(e);
siftUp(data.getSize()-1);
}
//元素上浮
public void siftUp(int index){
//当前元素不是根元素,且父元素小于当前元素时,才上浮
while(index>0 && data.get(parentIndex(index)).compareTo(data.get(index))<0){
//当前元素与父元素交互
data.swapt(index,parentIndex(index));
//当前元素的位置改为父元素的索引位置
index = parentIndex(index);
}
}
//取出堆中的组大元素
public E extractMax(){
if(data.isEmpty()){
return null;
}else{
E max = data.get(0);
//直接交换是效率高的关键,不要删除0位置的元素,
// 再向0位置加入元素,否则整个数组向后移动效率是极低的
//比如下边注释的代码的写法
data.swapt(0,data.getSize()-1);
data.removeLast();
siftDown(0);
return max;
}
/*//如果堆中没有数据,则返回null
if(data.isEmpty()){
return null;
}
//数组中存放的第一个元素,就是堆的最大元素
E max = data.get(0);
//删除该最大值,将数组最后一个元素添加到数据头部,删除该最后一个元素
data.removeFirst();
if(data.isEmpty()){
//删除第一个元素后,堆中不再有数据,则直接返回最大元素即可
return max;
}
E last = data.getLast();
data.addFirst(last);
data.removeLast();
//调用元素下浮方法
siftDown(0);
return max;*/
}
//元素下浮
/*
首先需要知道:没有左子则一定没有有子,有左子不一定有右子
* 1、如果左子为null,则不做处理;
2、如果左子不为null,右子为null,则与左子比较
3、如果左子右子均不为null,则与最大的比较
* */
public void siftDown(int index){
while(leftIndex(index) < data.getSize()){
//获取下一个要比较的节点的位置
int j = leftIndex(index);
if(j+1<data.getSize() && data.get(j+1).compareTo(data.get(j)) > 0){
j = rightIndex(index);
}
//如果当前节点>=要比较的节点,则是终止条件,不用再做任何处理
if(data.get(index).compareTo(data.get(j)) >= 0){
//退出while循环
break;
}else{
//否则交换数据,改变index位置,并进行下一次while判断
data.swapt(index,j);
index = j;
}
}
//这部分注释部分的写法与上边while形式的写法效率基本相同
/*//获取左子元素的位置
int leftIndex = leftIndex(index);
//如果左子元素的位置>=size,则代表左子元素的位置为空,则不用交换
//根据二叉堆的性质,左子为null,右子一定为null
if(leftIndex >= data.getSize()){
//如果左子树为null
return;
}else if(rightIndex(index) >= data.getSize()){
//如果右子树为null
//如果左子大,则交换,否则直接返回
if(data.get(index).compareTo(data.get(leftIndex)) < 0){
data.swapt(index,leftIndex);
index = leftIndex;
//下一次递归调用
siftDown(index);
}else{
return;
}
}else{//如果左右子树都不为null
//获取右子元素的位置
int rightIndex = rightIndex(index);
if(data.get(leftIndex).compareTo(data.get(rightIndex)) < 0){
//如果左子、右子均不为null,则与最大的比较,小于最大的,则交换,大于最大的,则返回
//右子大,与右子比较
if(data.get(index).compareTo(data.get(rightIndex)) < 0){
data.swapt(index,rightIndex);
index = rightIndex;
//下一次递归调用
siftDown(index);
}else{
return;
}
}else{
//左子大,与左子比较
if(data.get(index).compareTo(data.get(leftIndex)) < 0){
data.swapt(index,leftIndex);
index = leftIndex;
//下一次递归调用
siftDown(index);
}else{
return;
}
}
}*/
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
int size = data.getSize();
int capacity = data.getCapacity();
sb.append(String.format("MaxHeap:size = %d ,capacity = %d \n",size,capacity));
sb.append("[");
for(int i=0;i<size;i++){
sb.append(data.get(i));
if(i!=size-1){
sb.append(",");
}
}
sb.append("]");
return sb.toString();
}
//取出最大元素后,加入新的元素
public E replace(E e){
//如果先extractMax(最后一个元素放在0的位置,然后一次下浮),再add(一次上浮),两次O(logn)
//如果两步一起考虑,直接将第一个元素替换为要新增的元素,做一次下浮即可,一次O(logn)
E max = findMax();
//首元素替换为新增加的元素后,做一次下浮操作
data.set(0,e);
siftDown(0);
return max;
}
public E findMax(){
if(data.isEmpty()){
throw new IllegalArgumentException("cannot find max from empty heap");
}
return data.get(0);
}
//对任意数组进行排序,形成最大二叉堆
public Array<E> heapify(Array<E> array){
//最简单的思路:变脸array数组,调用MaxHeap的add方法(上浮),但是效率较低:O(nlogn)
//高效率的思路:从最后一个非叶子节点开始,向前遍历,做下浮操作(遍历的数据节省一半):O(n)
//获取最后一个非叶子节点的位置:数组最后一个节点的父节点的位置
int index = parentIndex(array.getSize()-1);
//由于下浮是针对data的
data = array;
for(int i=index;i>=0;i--){
siftDown(i);
}
return data;
}
}
优先队列实现如下:
package heap;
import queue.Queue;
/*
基于最大二叉堆实现优先队列,入队:O(logn),出队:O(logn)
优先队列:优先级高的先出队
*/
public class PriorityQueue<E extends Comparable<E>> implements Queue<E> {
private MaxHeap<E> maxHeap;
public PriorityQueue(){
maxHeap = new MaxHeap<>();
}
@Override
public int getSize() {
return maxHeap.getSize();
}
@Override
public boolean isEmpty() {
return maxHeap.isEmpty();
}
@Override
public void enqueue(E e) {
maxHeap.add(e);
}
@Override
public E dequeue() {
return maxHeap.extractMax();
}
@Override
public E getFront() {
return maxHeap.findMax();
}
}
测试代码如下:
package heap;
import array.Array;
import java.util.Random;
public class Main {
public static void main(String[] args) {
/*MaxHeap<Integer> maxHeap = new MaxHeap();
int[] arr = {28,16,13,22,17,15,19,41,62,30};
//int[] arr = {1930445623,1259258643,1865631293,795116128};
//测试增加,增加时会上浮
for(int i=0;i<arr.length;i++){
maxHeap.add(arr[i]);
}
//[62,41,19,28,30,13,15,16,22,17]
System.out.println(maxHeap);
//测试删除,删除时会下浮
maxHeap.extractMax();
System.out.println(maxHeap);//41,30,19,28,17,13,15,16,22
maxHeap.extractMax();
System.out.println(maxHeap);//30,28,19,22,17,13,15,16
System.out.println("测试利用最大二叉堆完成从大到小排序:");*/
//maxHeapOrder(1000000);
testHeapify();
}
//该测试相当于利用最大二叉堆实现100万个随机正数的从大到小排序
//100完的数据完成排序仅需1秒多,效率极高
public static int[] maxHeapOrder(int count){
long startTime = System.nanoTime();
MaxHeap<Integer> maxHeap = new MaxHeap<>();
int[] arr = new int[count];
Random random = new Random();
//随机数加入堆中
for(int i=0;i<count;i++){
maxHeap.add(random.nextInt(Integer.MAX_VALUE));
}
long endTime1 = System.nanoTime();
System.out.println("向堆中加入数据耗时(秒):" + (endTime1-startTime)/1000000000.0);
//循环遍历,从堆中取出最大值放入int[]数组中
for(int i=0;i<count;i++){
arr[i] = maxHeap.extractMax();
}
long endTime2 = System.nanoTime();
System.out.println("循环从堆中取出最大元素耗时(秒):" + (endTime2-endTime1)/1000000000.0);
//测试arr中的数据是否是从大到小排序的
for(int i=0;i<arr.length-1;i++){
if(arr[i] <arr[i+1]){
throw new IllegalArgumentException("arr不是从大到小排序的");
}
}
long endTime3 = System.nanoTime();
System.out.println("测试排序是否正确耗时(秒):" + (endTime3-endTime2)/1000000000.0);
System.out.println("正确完成从大到小的排序");
return arr;
}
public static void testHeapify(){
MaxHeap<Integer> maxHeap = new MaxHeap<>();
int count = 1000000;
Array<Integer> array = new Array<>(count);
Random random = new Random();
//随机生成10个正数的数组,取值范围0到100
for(int i=0;i<count;i++){
array.addLast(random.nextInt(count*10));
}
long startTime = System.nanoTime();
Array<Integer> newArray = maxHeap.heapify(array);
long endTime = System.nanoTime();
System.out.println("1000万的数组生成最大堆耗时(秒):" + (endTime-startTime)/1000000000.0);
System.out.println(newArray.getSize());
}
}
找出频度最高的k个元素实现如下:
package heap;
import java.util.*;
/*优先队列的入队和出队都是O(logn)的,
*
* */
public class PrioritySolution {
/*
*方法一:
* 1、利用最大堆,频度最小的元素存放在堆的最顶部
* 2、k到n个元素进入堆时,每次只需要和堆的最顶部的元素进行比较,如果频度值小于堆最顶部频度值,则不做处理;
* 否则删除堆顶元素(下浮),再加入新的元素(上浮),每次做完操作,堆的大小都是k,上浮和下浮也只是针对k个长度进行,所以每次操作都是O(logk)的。
* 3、堆最后保存的大小只有k个元素,取这k个元素的时候,每次操作相当于都是O(logk)的
* 所以该中算法的时间复杂度是o(nlogk)的方法,而方法二的时间复杂度是O(nlogn)的
*
* 举例:如果有1024个元素,取频度最大的8个元素
* 方法一:O(nlogk)=O(1024*log8)=O(1024*3)
* 方法二:O(nlogn)=O(1024*log1024)=O(1024*10)
*
* 这样两者的效率就差出了3倍
* */
private class Freq implements Comparable<Freq>{
public int e;
public int freq;
public Freq(int e,int freq){
this.e=e;
this.freq=freq;
}
@Override
//认为频度值小的元素是大元素,会排在堆顶
public int compareTo(Freq o) {
if(freq==o.freq){
return 0;
}else if(freq<o.freq){
return 1;
}else{
return -1;
}
}
}
public List<Integer> topKFrequent(int[] nums,int k){
//计算不同数值出现的频率
Map<Integer,Integer> map = new TreeMap();
for(int num:nums){
if(map.containsKey(num)){
map.put(num,map.get(num)+1);
}else{
map.put(num,1);
}
}
Set<Integer> set = map.keySet();
PriorityQueue<Freq> priorityQueue = new PriorityQueue<>();
for(Integer key:set){
//前k个元素直接加入堆中,不用与对顶元素比较
if(priorityQueue.getSize() < k){
priorityQueue.enqueue(new Freq(key,map.get(key)));
}else if(map.get(key) > priorityQueue.getFront().freq){
//从k个元素开始,如果频度大于对顶的频度最小的元素的频度
//对顶元素出队,新的元素入队,下浮和上浮都是针对大小只有k的元素做的
priorityQueue.dequeue();
priorityQueue.enqueue(new Freq(key,map.get(key)));
}
}
List<Integer> list = new ArrayList<>();
//由于队列中只有频度最大的k个元素,所以全部遍历即可
while(!priorityQueue.isEmpty()){
list.add(priorityQueue.dequeue().e);
}
return list;
}
public static void main(String[] args) {
int[] arr = {5,4,5,6,6,6,2,3};
PrioritySolution solution = new PrioritySolution();
System.out.println(solution.topKFrequent(arr,2));
}
/*
*方法二:
* 1、利用最大堆,频度最高的元素存放在堆的最顶部
* 2、k到n个元素进入堆时,都需要从堆的最后一个元素做上浮操作,且每次堆的大小都会+1,最后堆的大小为n
* 3、从堆顶依次取出前k个频度最大的元素(取一次n的大小-1),每次取出,堆进行下浮的时候,相当于遍历的d堆的大小都是n级别的
* 所以该中算法的时间复杂度是o(nlogn)的
* */
/*private class Freq implements Comparable<Freq>{
public int e;
public int freq;
public Freq(int e,int freq){
this.e=e;
this.freq=freq;
}
@Override
public int compareTo(Freq o) {
if(freq==o.freq){
return 0;
}else if(freq<o.freq){
return -1;
}else{
return 1;
}
}
}
public List<Integer> topKFrequent(int[] nums,int k){
//计算不同数值出现的频率
Map<Integer,Integer> map = new TreeMap();
for(int num:nums){
if(map.containsKey(num)){
map.put(num,map.get(num)+1);
}else{
map.put(num,1);
}
}
Set<Integer> set = map.keySet();
PriorityQueue<Freq> priorityQueue = new PriorityQueue<>();
for(Integer key:set){
priorityQueue.enqueue(new Freq(key,map.get(key)));
}
List<Integer> list = new ArrayList<>();
for(int i=0;i<k;i++){
list.add(priorityQueue.dequeue().e);
}
return list;
}
public static void main(String[] args) {
int[] arr = {5,4,5,6,6,6,2,3};
PrioritySolution solution = new PrioritySolution();
System.out.println(solution.topKFrequent(arr,2));
}*/
}
如有理解不到之处,望指正!
标签:illegal 针对 写法 获取 swap code 添加元素 时间 ide
原文地址:https://www.cnblogs.com/xiao1572662/p/12114188.html