标签:des style blog http io os ar 使用 for
一、引言
本材料参考Andrew Ng大神的机器学习课程 http://cs229.stanford.edu,以及斯坦福无监督学习UFLDL tutorial http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
机器学习中的回归问题属于有监督学习的范畴。回归问题的目标是给定D维输入变量x,并且每一个输入矢量x都有对应的值y,要求对于新来的数据预测它对应的连续的目标值t。比如下面这个例子:假设我们有一个包含47个房子的面积和价格的数据集如下:
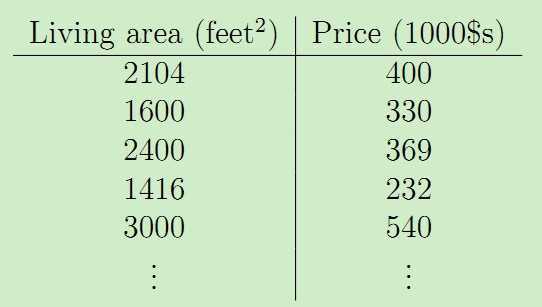
我们可以在Matlab中画出来这组数据集,如下:
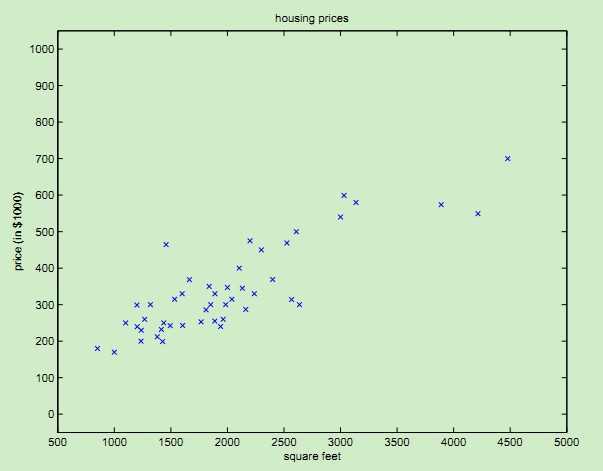
看到画出来的点,是不是有点像一条直线?我们可以用一条曲线去尽量拟合这些数据点,那么对于新来的输入,我么就可以将拟合的曲线上返回对应的点从而达到预测的目的。如果要预测的值是连续的比如上述的房价,那么就属于回归问题;如果要预测的值是离散的即一个个标签,那么就属于分类问题。这个学习处理过程如下图所示:
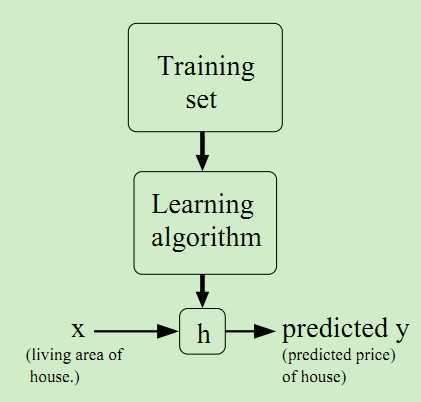
上述学习过程中的常用术语:包含房子面积和价格的数据集称为训练集training set;输入变量x(本例中为面积)为特征features;输出的预测值y(本例中为房价)为目标值target;拟合的曲线,一般表示为y = h(x),称为假设模型hypothesis;训练集的条目数称为特征的维数,本例为47。
二、线性回归模型
线性回归模型假设输入特征和对应的结果满足线性关系。在上述的数据集中加上一维--房间数量,于是数据集变为:
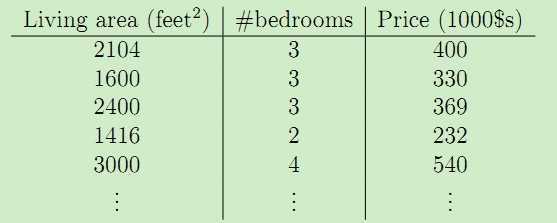
于是,输入特征x是二维的矢量,比如x1(i)表示数据集中第i个房子的面积,x2(i)表示数据集中第i个房子的房间数量。于是可以假设输入特征x与房价y满足线性函数,比如:
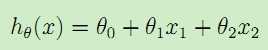
这里θi称为假设模型即映射输入特征x与结果y的线性函数h的参数parameters,为了简化表示,我们在输入特征中加入x0 = 1,于是得到:
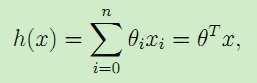
参数θ和输入特征x都为矢量,n是输入的特征x的个数(不包含x0)。
现在,给定一个训练集,我们应该怎么学习参数θ,从而达到比较好的拟合效果呢?一个直观的想法是使得预测值h(x)尽可能接近y,为了达到这个目的,我们对于每一个参数θ,定义一个代价函数cost function用来描述h(x(i))‘与对应的y(i)‘的接近程度:
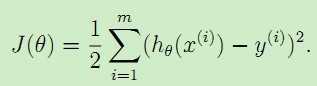
前面乘上的1/2是为了求导的时候,使常数系数消失。于是我们的目标就变为了调整θ使得代价函数J(θ)取得最小值,方法有梯度下降法,最小二乘法等。
2.1 梯度下降法
现在我们要调整θ使得J(θ)取得最小值,为了达到这个目的,我们可以对θ取一个随机初始值(随机初始化的目的是使对称失效),然后不断地迭代改变θ的值来使J(θ)减小,知道最终收敛取得一个θ值使得J(θ)最小。梯度下降法就采用这样的思想:对θ设定一个随机初值θ0,然后迭代进行以下更新
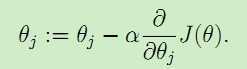
直到收敛。这里的α称为学习率learning rate。
梯度方向由J(θ)对θ 的偏导数决定,由于要求的是最小值,因此对偏导数取负值得到梯度方向。将J(θ)代入得到总的更新公式
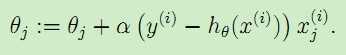
这样的更新规则称为LMS update rule(least mean squares),也称为Widrow-Ho? learning rule。
对于如下更新参数的算法:
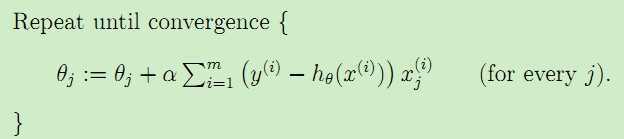
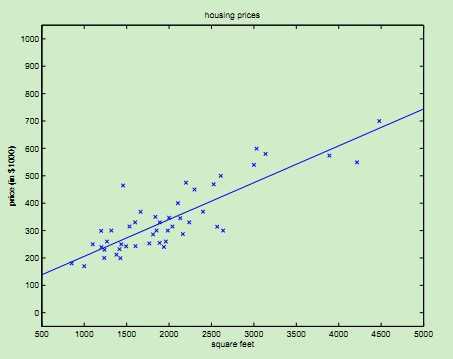
由于在每一次迭代都考察训练集的所有样本,而称为批量梯度下降batch gradient descent。对于引言中的房价数据集,运行这种算法,可以得到θ0 = 71.27, θ1 = 1.1345,拟合曲线如下图:
如果参数更新计算算法如下:
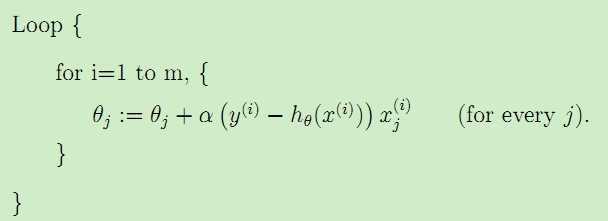
这里我们按照单个训练样本更新θ的值,称为随机梯度下降stochastic gradient descent。比较这两种梯度下降算法,由于batch gradient descent在每一步都考虑全部数据集,因而复杂度比较高,随机梯度下降会比较快地收敛,而且在实际情况中两种梯度下降得到的最优解J(θ)一般会接近真实的最小值。所以对于较大的数据集,一般采用效率较高的随机梯度下降法。
2.2 最小二乘法
梯度下降算法给出了一种计算θ的方法,但是需要迭代的过程,比较费时而且不太直观。下面介绍的最小二乘法是一种直观的直接利用矩阵运算可以得到θ值的算法。为了理解最小二乘法,首先回顾一下矩阵的有关运算:
假设函数f是将m*n维矩阵映射为一个实数的运算,即![]() ,并且定义对于矩阵A,映射f(A)对A的梯度为:
,并且定义对于矩阵A,映射f(A)对A的梯度为:
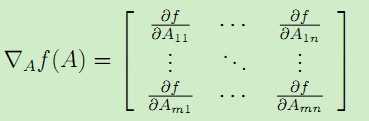
因此该梯度为m*n的矩阵。例如对于矩阵A= ,而且映射函数f(A)定义为:F(A) = 1.5A11 + 5A122 + A21A22,于是梯度为:
,而且映射函数f(A)定义为:F(A) = 1.5A11 + 5A122 + A21A22,于是梯度为:
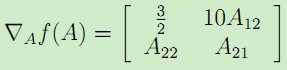 。
。
另外,对于矩阵的迹的梯度运算,有如下规则:
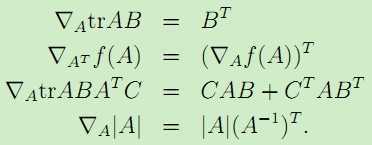 。
。
下面,我们将测试集中的输入特征x和对应的结果y表示成矩阵或者向量的形式,有:
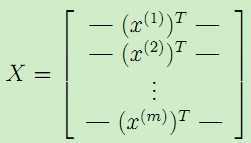 ,
,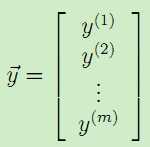 ,
,
对于预测模型有![]() ,即
,即![]() ,于是可以很容易得到:
,于是可以很容易得到:
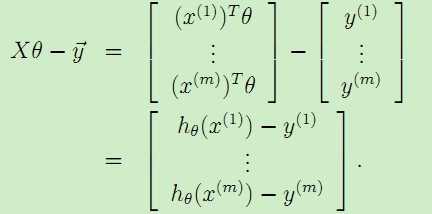 ,
,
所以可以得到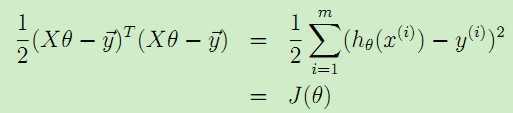 。
。
于是,我们就将代价函数J(θ)表示为了矩阵的形式,就可以用上述提到的矩阵运算来得到梯度:
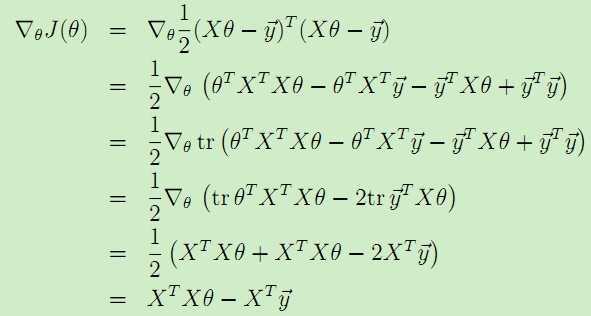 ,
,
令上述梯度为0,得到等式:![]() ,于是得到θ的值:
,于是得到θ的值:
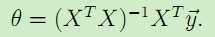 。这就是最小二乘法得到的假设模型中参数的值。
。这就是最小二乘法得到的假设模型中参数的值。
2.3 加权线性回归
首先考虑下图中的几种曲线拟合情况:
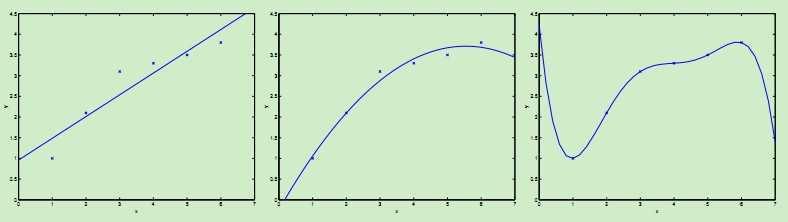
最左边的图使用线性拟合![]() ,但是可以看到数据点并不完全在一条直线上,因而拟合的效果并不好。如果我们加入x2项,得到
,但是可以看到数据点并不完全在一条直线上,因而拟合的效果并不好。如果我们加入x2项,得到![]() ,如中间图所示,该二次曲线可以更好的拟合数据点。我们继续加入更高次项,可以得到最右边图所示的拟合曲线,可以完美地拟合数据点,最右边的图中曲线为5阶多项式,可是我们都很清醒地知道这个曲线过于完美了,对于新来的数据可能预测效果并不会那么好。对于最左边的曲线,我们称之为欠拟合--过小的特征集合使得模型过于简单不能很好地表达数据的结构,最右边的曲线我们称之为过拟合--过大的特征集合使得模型过于复杂。
,如中间图所示,该二次曲线可以更好的拟合数据点。我们继续加入更高次项,可以得到最右边图所示的拟合曲线,可以完美地拟合数据点,最右边的图中曲线为5阶多项式,可是我们都很清醒地知道这个曲线过于完美了,对于新来的数据可能预测效果并不会那么好。对于最左边的曲线,我们称之为欠拟合--过小的特征集合使得模型过于简单不能很好地表达数据的结构,最右边的曲线我们称之为过拟合--过大的特征集合使得模型过于复杂。
正如上述例子表明,在学习过程中,特征的选择对于最终学习到的模型的性能有很大影响,于是选择用哪个特征,每个特征的重要性如何就产生了加权的线性回归。在传统的线性回归中,学习过程如下:
 ,
,
而加权线性回归学习过程如下:
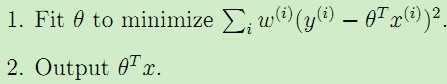 。
。
二者的区别就在于对不同的输入特征赋予了不同的非负值权重,权重越大,对于代价函数的影响越大。一般选取的权重计算公式为:
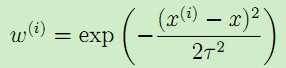 ,
,
其中,x是要预测的特征,表示离x越近的样本权重越大,越远的影响越小。
三、logistic回归与Softmax回归
3.1 logistic回归
下面介绍一下logistic回归,虽然名曰回归,但实际上logistic回归用于分类问题。logistic回归实质上还是线性回归模型,只是在回归的连续值结果上加了一层函数映射,将特征线性求和,然后使用g(z)作映射,将连续值映射到离散值0/1上(对于sigmoid函数,而对于双曲正弦tanh函数为1/-1两类)。采用假设模型为:
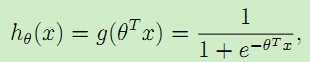 ,
,
而sigmoid函数g(z)为:
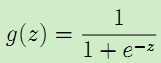
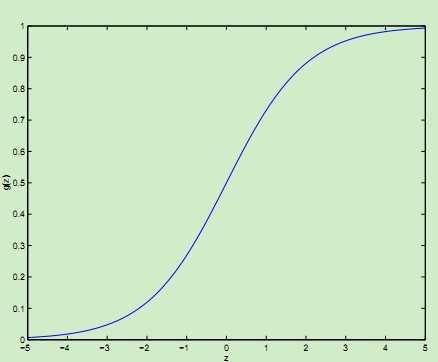
当z趋近于-∞,g(z)趋近于0,而z趋近于∞,g(z)趋近于1,从而达到分类的目的。这里的![]()
那么对于这样的logistic模型,怎么调整参数θ呢?我们假设
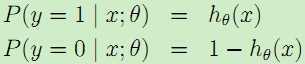 ,由于是两类问题,即
,由于是两类问题,即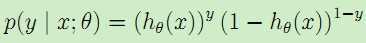 ,于是得到似然估计为:
,于是得到似然估计为:
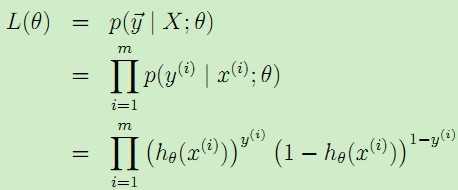
对似然估计取对数可以更容易地求解: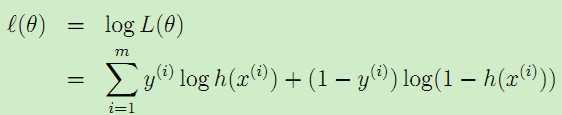 。
。
接下来是θ的似然估计最大化,可以考虑上述的梯度下降法,于是得到:
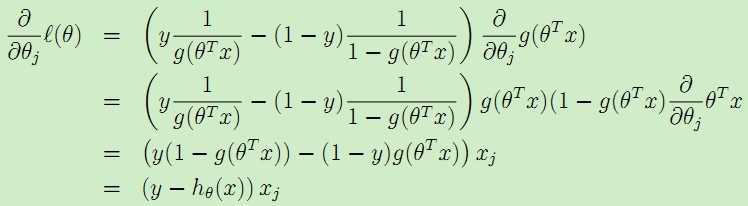
得到类似的更新公式:![]() 。虽然这个更新规则类似于LMS得到的公式,但是这两种是不同算法,因为这里的hθ(x(i))是一个关于θTx(i)的非线性函数。
。虽然这个更新规则类似于LMS得到的公式,但是这两种是不同算法,因为这里的hθ(x(i))是一个关于θTx(i)的非线性函数。
3.2 Softmax回归
logistic回归是两类回归问题的算法,如果目标结果是多个离散值怎么办?Softmax回归模型就是解决这个问题的,Softmax回归模型是logistic模型在多分类问题上的推广。在Softmax回归中,类标签y可以去k个不同的值(k>2)。因此对于y(i)从属于{1,2,3···k}。
对于给定的测试输入x,我们要利用假设模型针对每一个类别j估算概率值p(y = j|x)。于是假设函数hθ(x(i))形式为:
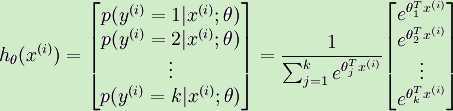
其中θ1,θ2,θ3,···,θk属于模型的参数,等式右边的系数是对概率分布进行归一化,使得总概率之和为1。于是类似于logistic回归,推广得到新的代价函数为:
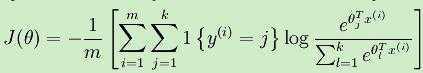
可以看到Softmax代价函数与logistic代价函数形式上非常相似,只是Softmax函数将k个可能的类别进行了累加,在Softmax中将x分为类别j的概率为:
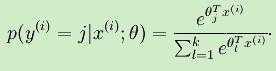
于是对于Softmax的代价函数,利用梯度下降法使的J(θ)最小,梯度公式如下:
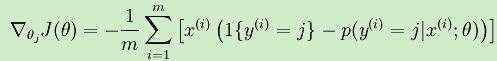
表示J(θ)对第j个元素θj的偏导数,每一次迭代进行更新: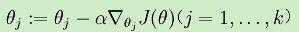 。
。
3.3 Softmax回归 vs logistic回归
特别地,当Softmax回归中k = 2时,Softmax就退化为logistic回归。当k = 2时,Softmax回归的假设模型为:
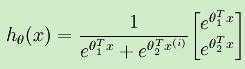
我们令ψ = θ1,并且两个参数都剪去θ1,得到:

于是Softmax回归预测得到两个类别的概率形式与logistic回归一致。
现在,如果有一个k类分类的任务,我们可以选择Softmax回归,也可以选择k个独立的logistic回归分类器,应该如何选择呢?
这一选择取决于这k个类别是否互斥,例如,如果有四个类别的电影,分别为:好莱坞电影、港台电影、日韩电影、大陆电影,需要对每一个训练的电影样本打上一个标签,那么此时应选择k = 4的Softmax回归。然而,如果四个电影类别如下:动作、喜剧、爱情、欧美,这些类别并不是互斥的,于是这种情况下使用4个logistic回归分类器比较合理。
四、一般线性回归模型
首先定义一个通用的指数概率分布:
![]()
考虑伯努利分布,有:
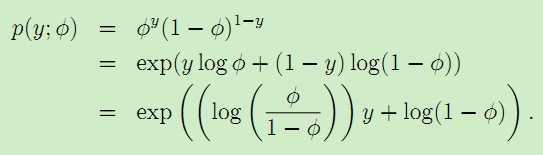
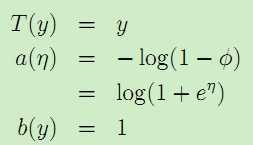
再考虑高斯分布:
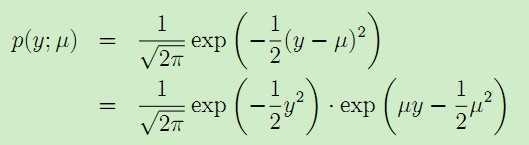
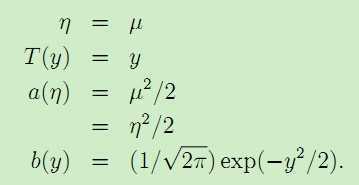
一般线性模型满足:1. y|x;θ 满足指数分布族E(η) 2. 给定特征x,预测结果为T(y) = E[y|x] 3. 参数η = θTx 。
对于第二部分的线性模型,我们假设结果y满足高斯分布Ν(μ,σ2),于是期望μ = η,所以:
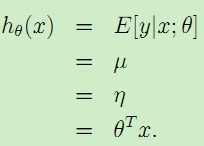
很显然,从一般线性模型的角度得到了第二部分的假设模型。
对于logistic模型,由于假设结果分为两类,很自然地想到伯努利分布,并且可以得到![]() ,于是 y|x;θ 满足B(Φ),E[y|x;θ] = Φ,所以
,于是 y|x;θ 满足B(Φ),E[y|x;θ] = Φ,所以
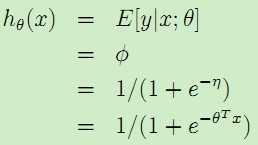
于是得到了与logistic假设模型的公式,这也解释了logistic回归为何使用这个函数。
标签:des style blog http io os ar 使用 for
原文地址:http://www.cnblogs.com/fanyabo/p/4060498.html