标签:论坛 audio 实测 方法 结合 系统升级 src code line
先前的文章《三个小白是如何在三个月内搭一个基于kaldi的嵌入式在线语音识别系统的 》说我们花了不到三个月的时间搭了一个基于kaldi的嵌入式语音识别系统,不过它是基于传统的GMM-HMM的,是给我们练手用的,通过搭这个系统我们累积了一定的语音识别领域的经验,接下来我们就要考虑做什么形态的产品了。语音识别可以分大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition, LVCSR)和关键词识别(Keyword Spotting, KWS)。LVCSR 要求很强的计算能力,这类方案主要在服务器上实现。KWS只要识别出关键词即可,对算力要求不是很高,可以在终端芯片上实现。由于我们公司的芯片主要用于终端产品上,算力不是很强,因此我们就准备做关键词识别。对于关键词识别又可分为几种应用场景。一是音频文献中关键词检索,用于快速找到音频文献中需要的内容。二是语音唤醒词识别,用于唤醒终端设备,让其工作(不唤醒时设备处于睡眠状态)。三是命令词识别,用于语音命令控制的场景,终端设备收到某个命令词后就执行相应的操作。比如智能家居场景中,当用户说出“打开空调”被识别到后就把空调打开了。经过讨论后我们决定做中文命令词识别,暂时把应用场景定在智能家居上,并定义了几个命令词,例如“打开空调”、“关闭空调”等。后面如果要做其他场景,只要改变命令词重新训练模型即可,代码部分是不需要改动的。
先前的系统是基于GMM-HMM的,已out,我们想用深度神经网络(Deep Neural Networks,DNN)来做。kaldi中的DNN分为nnet1、nnet2、nnet3三种。nnet1是由Karel写的,使用的是DNN-HMM架构,这里DNN说白了就是MLP(MultiLayer Perceptron,多层感知机)。nnet2和nnet3是由Daniel写的,nnet2同样使用的是DNN-HMM架构,nnet3还包含了其他网络架构,有CNN/RNN/LSTM等。nnet1没有online decoder,nnet2和nnet3则有online decoder,比较下来我们决定用nnet2。DNN-HMM是基于GMM-HMM的,是用DNN替代GMM,因而我们前面的工作还可以用得上,所以这次的工作主要分两部分,一是模型训练,二是nnet2 online decoder相关代码的移植。上次负责模型训练的同学由于忙其他工作,这次模型训练就由我来做。nnet2 online decoder代码移植由另外一个同学负责。同时我们在前处理中把VAD(Voice Activity Detection,语音活动检测)加上,只把检测到语音的部分送到后面模块处理,这样降低了功耗。
这次我来弄模型训练。由于是新手,先得学习怎么训练模型,然后根据新的需求训练出新的模型。经过半个多月的学习,大体上搞清楚了模型训练的步骤。首先是数据准备,包括准备语料、字典和语言模型等。对于语料,可以花钱买,也可以自己录,要将其分成训练集、测试集和交叉验证集。字典表示一个词是由哪些音素组成的。语言模型通过专业的工具(如srilm的ngram-count)生成。然后处理语料得到scp/spk2utt/utt2spk等文件,处理字典、语言模型等得到FST等文件。再就是做MFCC得到每一帧的特征向量,最后进行各个阶段的训练得到相应的模型文件(final.mdl)。主要的阶段有单音素训练(mono)、三音素训练(tri1)、LDA_MLLT训练(tri2b)、SAT训练(tri3b)、quick训练(tri4b),每一步训练都是基于上一步训练解码后对齐的结果。上面这几步是GMM-HMM的训练,如果要做深度神经网络(DNN)的训练,则还要把DNN训练这步加上去。我们这次做的是中文命令词的识别,先定好命令词,然后从thchs30里找到这些词的声韵母的写法,需要注意的是thchs30里声韵母的写法跟通常拼音的写法有些不一样,再根据这些命令词用工具把语言模型生成。我们的语料是自己录的,发动了周围的同学帮忙录,有男声和女声。这些都准备好后先处理语料得到scp等文件,再根据字典、语言模型等生成fst等文件,最后就开始各个阶段的训练了。先训练传统的GMM-HMM,不断的调整参数,直至WER有一个不错的值。GMM-HMM模型训练好后我把模型load进我们先前搭好的demo,实测下来效果还不错。这说明GMM-HMM的模型训练是OK的,接下来就要开始训练DNN(nnet2)的模型了。
我没有立刻去训练nnet2的模型,而是再去学习了下DNN的基础知识(以前简单学习过,一直没用到,理解的不深,有些已经忘记了),重点关注了梯度下降法和网络参数怎么更新,并写成了两篇博客:《机器学习中梯度下降法原理及用其解决线性回归问题的C语言实现 》& 《kaldi中CD-DNN-HMM网络参数更新公式手写推导》。接下来就去看怎么训练nnet2的模型了。先到kaldi的官方网站上看训练nnet2的相关内容,大致明白就开始基于我们自己录制的语料库调试了。nnet2的训练脚本较乱,一个脚本下有多个版本(nnet4a / nnet4b / nnet4c / nnet4d / nnet5c / nnet5d)。我刚开始不清楚孰优孰劣,把每个都调通。在网上搜索调查了一下,kaldi的作者Daniel Povey在一个论坛里说隐藏层用p-norm做激活函数的性能更好一些。于是决定用推荐的nnet4d(激活函数就是用的p-norm)来继续训练。经过多次参数tuning后得到了一个WER相对不错的模型。
在我训练DNN模型的同时,负责代码移植的同学也在把nnet2 online decoder的相关代码往我们平台上移植,套路跟我先前的一样。同时kaldi也提供了一个应用程序(代码见online2-wav-nnet2-latgen-faster.cc),对WAV文件做nnet2的online decoder。我们先要把模型在这个应用程序上调通(通常kaldi代码是没有问题的,我们在这个应用程序里调通就说明模型训练是没有问题的,后面在我们自己的平台上去调试就有基准可参考了)。当我们把模型放进应用程序里运行,报了“Feature dimension is 113 but network expects 40”的错。调查下来发现kaldi应用程序要求MFCC是13维的,且有i-vector的功能(100维的),这样加起来就是113维的。而我训练的nnet2模型是基于tri3b的(DNN-HMM要利用GMM-HMM的训练解码对齐结果,对齐的越好DNN模型的识别率就越高),13维MFCC+26维delta+1维pitch,共40维,所以模型输入是40维的。讨论后为了降低复杂度,我们决定先把应用程序中的i-vector功能给去掉,同时我基于单音素的模型(13维MFCC)重新训练nnet2模型。基于新的模型运行应用程序不报错了,但是识别率很低。我们一时没有了方向,做了几次尝试还是识别率很低。后来我们开始比较我的训练处理流程和应用程序里的处理流程,发现我训练时用了CMVN(以前做GMM-HMM训练时就有),而应用程序代码处理流程里没有。于是在代码里把CMVN的处理加上,再去运行应用程序,识别率显著提升了。我们长舒了一口气,因为我们知道这个问题被解决了,从而心里有底了。再把应用程序的机制移植到我们平台上,同时另外一个同学也帮忙把webRTC的VAD也移植进来,有语音才会把那段语音往后面模块送,这跟应用程序中读WAV文件很类似,所以处理起来机制就很类似。用了两三天就把包含VAD、前处理(ANS、AGC)和nnet2 online decoder的系统联调好了。测试了一下,被训练过的人说命令词识别率大于90%,而未被训练过的识别率大于80%。但是有个严重的问题,就是集外词(out-of-vocabulary,OOV,就是命令词以外的词)都会被识别成一个集内词(命令词),即集外词没有被拒识。
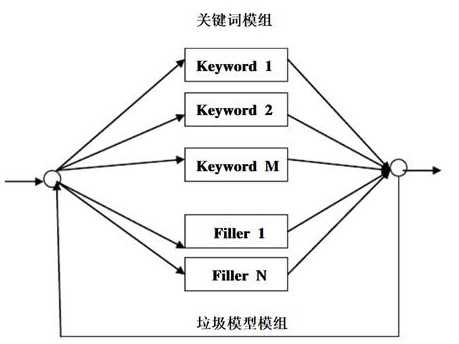
针对这个问题,我查了些资料并静下心来想了想,在当前架构下说出一个词,只会以WFST中路径最短的一个作为识别结果输出,所以才会有集外词被识别成了集内词。我们的系统目前只能识别那些指定的关键词,但是还不具备关键词识别系统的任何特点。我在前面的文章《语音识别中唤醒技术调研》 中曾总结过实现关键词识别的三种方法,一是基于LVCSR来做,在终端芯片上不太可行。二是keyword/filler方法,说白了就是把一些垃圾词也放进模型里去训练(大意如下图),识别时说集外词很大可能是垃圾词作为识别结果而不输出从而实现集外词拒识,在终端芯片上可行。三是纯深度学习方法(相对于3,1和2是传统方法)。我们的架构是DNN-HMM,虽然也用了深度神经网络,但DNN是用来替代GMM的,本质上还是一种传统方法,所以我决定把keyword/filler方法用到我们的系统上。先从thchs30里找到几百个集外词(垃圾词),然后根据这些词录制语料并放进模型里训练。用新生成的模型去测试,集外词拒识率大幅提高,但是一些情况下集外词还是被识别为集内词。例如关键词是“深度科技”,如说成“深度科学”就有可能被识别成“深度科技”。针对这种情况,我把相关的词(常用的)都放进垃圾词里,如“深度科学”、“深度科普”、“深度科研”等,再去测试这些词就不会被识别成集内词了。再例如一些词发音跟集内词发音很相似,比如说“深度科器”会被识别成“深度科技”,我试了试百度的小度音箱,把唤醒词“小度小度”说成“角度角度”或者“巧度巧度”,小度音箱依旧会被唤醒。市面上已大规模商用的产品都有这个现象,我也就没管它。与此同时,我还在看一些集外词拒识的相关论文,发现好多都结合用置信度(conference measure)来解决这个问题,其中中科院自动化所的一篇博士论文《语音识别中的置信度研究与应用》讲的比较好。看后我明白了要想在传统架构下把集外词拒识问题解决好,一是要用上keyword/filler方法,二是要用上置信度。目前我是没有能力根据论文去实现置信度的,也没有找到开源的关于置信度的实现,于是在kaldi WFST lattice代码里想办法。通过大量的集内词和集外词的测试我发现可以用一些变量去做判断,但是有可能集外词拒识率提高了,集内词识别率也下降了(用置信度也会有同样的问题,这个度很难掌控。这块内容也是挺难的,尤其对我一个做工程的且做语音识别没多久的来说) 。经过一段时间的努力后集内词的识别率和集外词的拒识率都有了一个相当的水准,但离商用还有一段距离,后面还有很多事情要做,比如加大语料(我们目前只有一个几十人的语料库,没有好几百人并且覆盖男女以及不同年龄段的语料库是不能商用的),后面会越来越难!
马上就2019年过去了。回首这一年,三分之二的时间都用来做语音识别了,全是摸索着向前走,有痛苦,也有欢乐,从最初的什么都不懂到现在的懂一点。希望2020年自己在这个领域进步再大一点。
标签:论坛 audio 实测 方法 结合 系统升级 src code line
原文地址:https://www.cnblogs.com/talkaudiodev/p/12085248.html