标签:csv att info head core 使用 class 整数 label
读取CSV文件时,,设置sep参数,可以替换分割用的符号:
df = pd.read_csv(‘student_scores.csv‘, sep=‘:‘) df.head()
这样可以把冒号作为分隔符。
read_csv 的另一个功能是指定文件的哪一行作为标题,而标题指定了列标签。通常第一行是标题,但有时如果文件顶部有额外的元信息,我们希望指定另一行作为标题。可以这样操作:
df = pd.read_csv(‘student_scores.csv‘, header=2) df.head()
这里使用第 2 行作为标题,上面的所有数据都被删除。默认情况下,read_csv 使用 header=0,使用第一行作为列标签。
如果文件中不包括列标签,可以使用 header=None 防止数据的第一行被误当做列标签。
还可以用以下方法自己指定列标签:
labels = [‘id‘, ‘name‘, ‘attendance‘, ‘hw‘, ‘test1‘, ‘project1‘, ‘test2‘, ‘project2‘, ‘final‘] df = pd.read_csv(‘student_scores.csv‘, names=labels) df.head()
除使用默认索引(从 0 递增 1 的整数)之外,还可以将一个或多个列指定为数据框的索引:
df = pd.read_csv(‘student_scores.csv‘, index_col=‘Name‘) df.head()
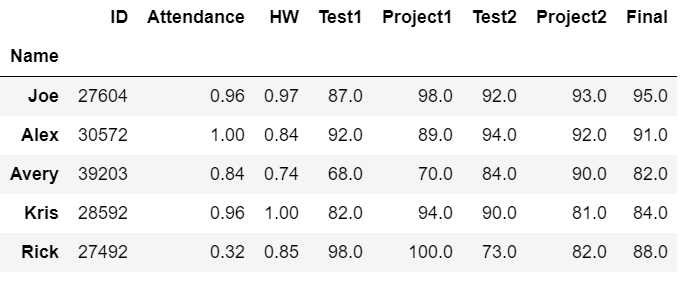
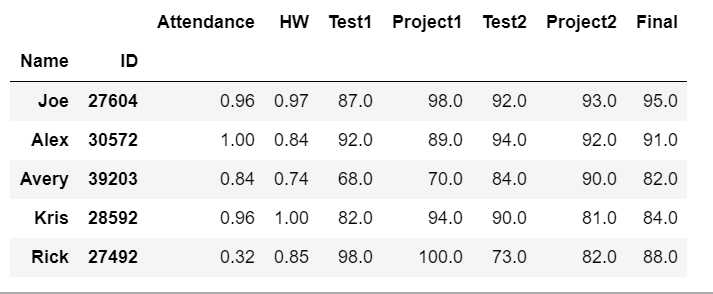
df = pd.read_csv(‘student_scores.csv‘, index_col=[‘Name‘, ‘ID‘]) df.head()
df_powerplant.to_csv(‘powerplant_data_edited.csv‘) df = pd.read_csv(‘powerplant_data_edited.csv‘) df.head()
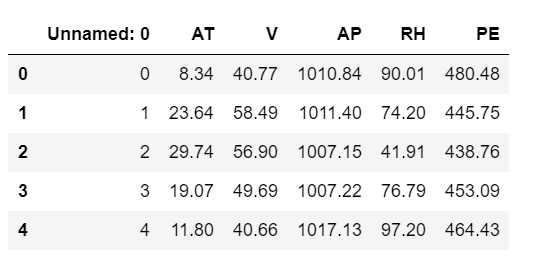
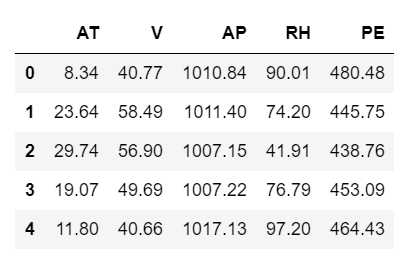
这个 Unnamed:0 是to_csv() 默认保存索引,除非指定不保存。如需忽略索引,必须提供参数 index=False:
df_powerplant.to_csv(‘powerplant_data_edited.csv‘, index=False) df = pd.read_csv(‘powerplant_data_edited.csv‘) df.head()
标签:csv att info head core 使用 class 整数 label
原文地址:https://www.cnblogs.com/shenxi-ricardo/p/12123845.html