标签:密码 template review 技术 而在 节点 实现 nbsp 上传
配置免密度登录
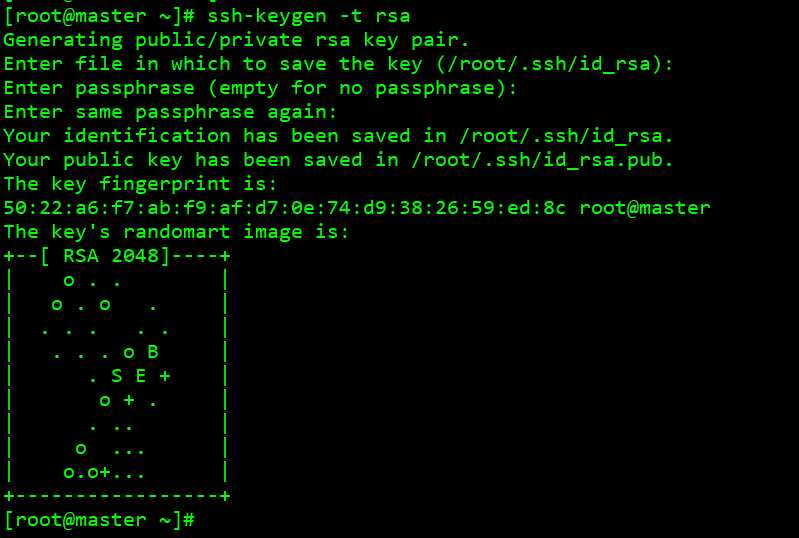
执行 ssh-keygen -t rsa
#建立 ssh 目录,一路敲回车, 生成的密钥对 id_rsa, id_rsa.pub,
默认存储在~/.ssh 目录下
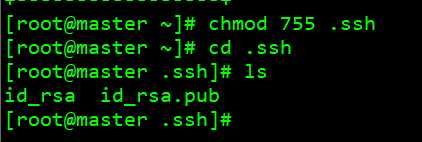
chmod 755 .ssh #赋予 755 权限 cd .ssh #ls – l id_rsa id_rsa.pub
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把公用密匙添加到 authorized_keys 文件中(此文件最后一定要赋予 644 权限)

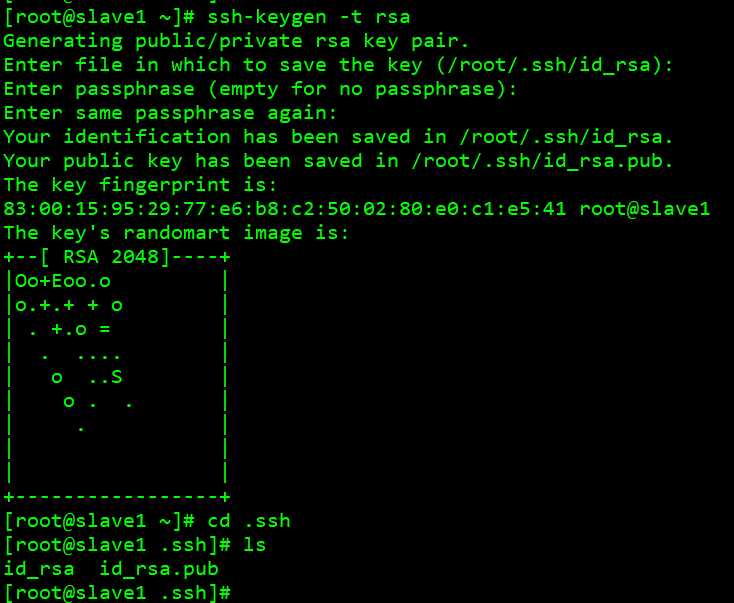
现在给slave1节点设置公钥
执行 ssh-keygen -t rsa
#建立 ssh 目录,一路敲回车, 生成的密钥对 id_rsa, id_rsa.pub,
默认存储在~/.ssh 目录下
chmod 755 .ssh #赋予 755 权限 cd .ssh #ls – l id_rsa id_rsa.pub
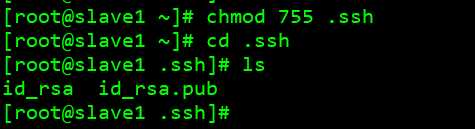
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把公用密匙添加到 authorized_keys 文件中(此文件最后一定要赋予 644 权限)

ssh slave1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
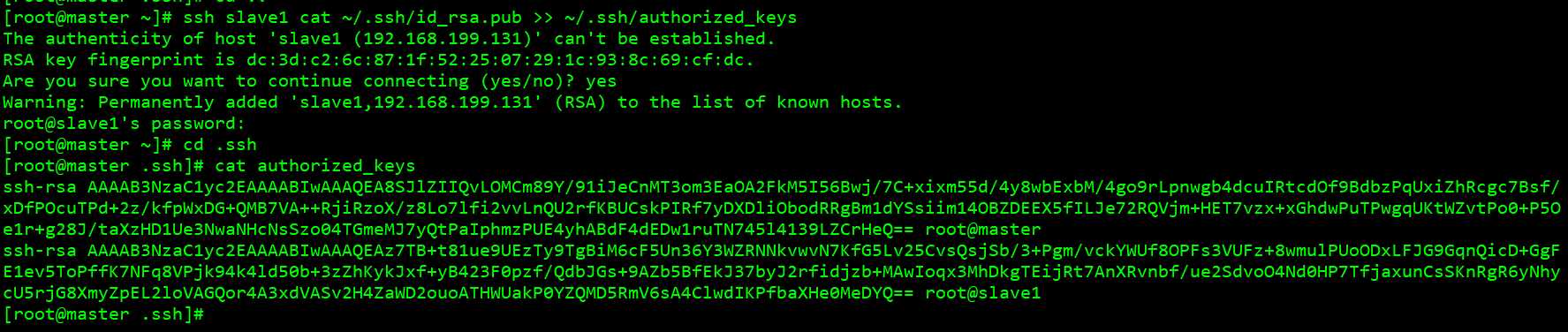
有几个 slave 节点就需要运行几次命令, slave1 是节点名称 scp ~/.ssh/authorized_keys slave1:~/.ssh/ #把 authorized_keys 文件拷贝回每一个节点, slave1 是节点名称

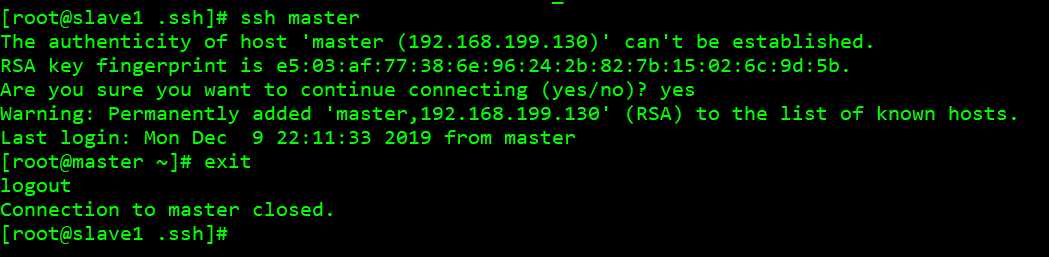
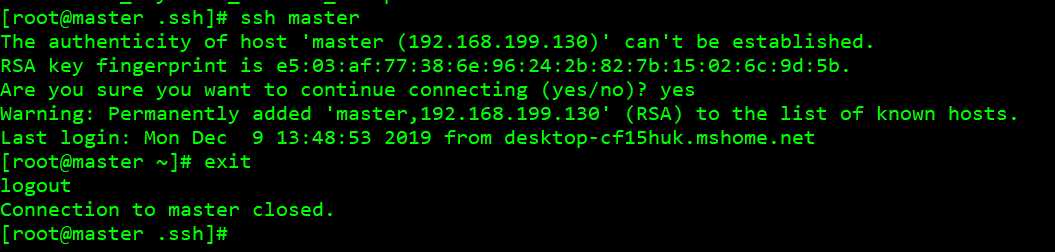
可以看到能相互之间实现了免密码登录。
解压 Scala 和 Spark
1、 删除 cdh 中的 Spark:
rm -rf /usr/bin/spark*
rm -rf /etc/spark


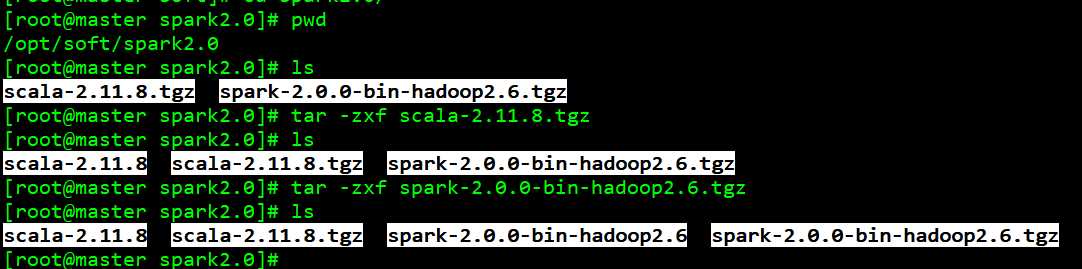
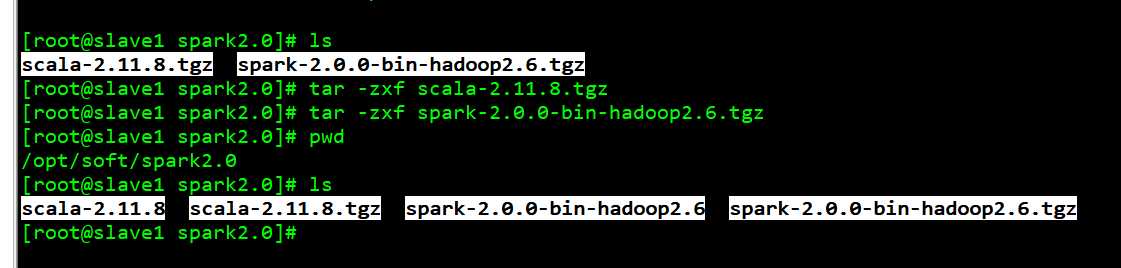
2、 上传至 spark-2.0.0-preview-bin-hadoop2.6.tgz 和 scala-2.11.8.tgz 至 /opt/soft/spark2.0 下, 并进行解压
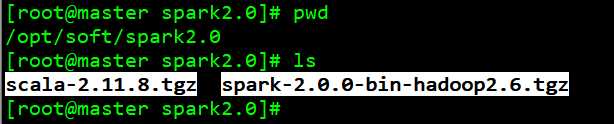
tar -zxf scala-2.11.8.tgz tar -zxf spark-2.0.0-bin-hadoop2.6.tgz
vi /etc/profile, 增加如下内容:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export SPARK_HOME=/opt/soft/spark2.0/spark-2.0.0-bin-hadoop2.6
export SCALA_HOME=/opt/soft/spark2.0/scala-2.11.8
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME=/bin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=/etc/hadoop/conf
source /etc/profile 起效
两个节点都配置环境变量
3、 修改 SPARK_HOME/conf 下
mv slaves.template slaves , slaves 里配置工作节点主机名列表


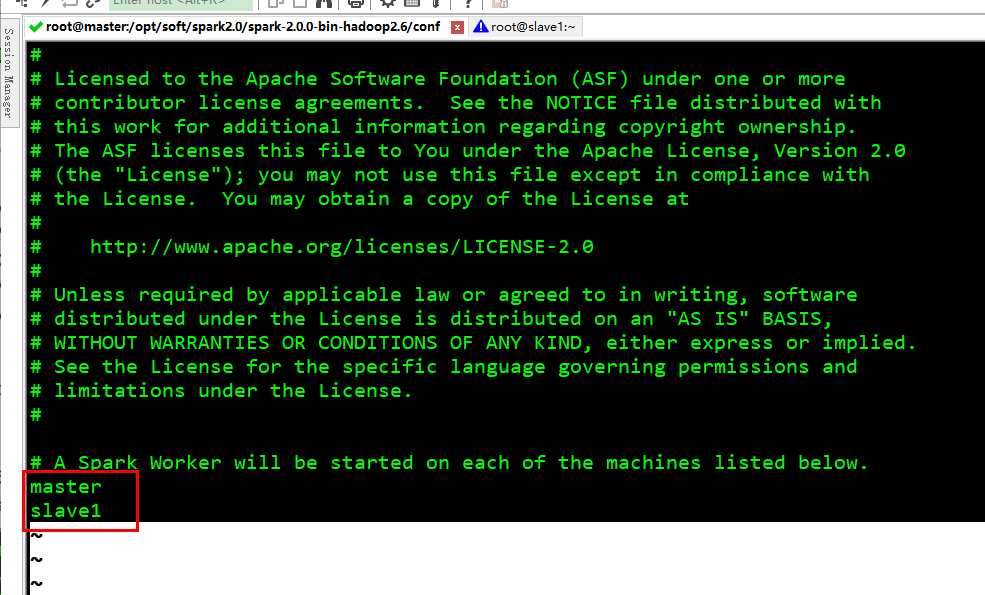


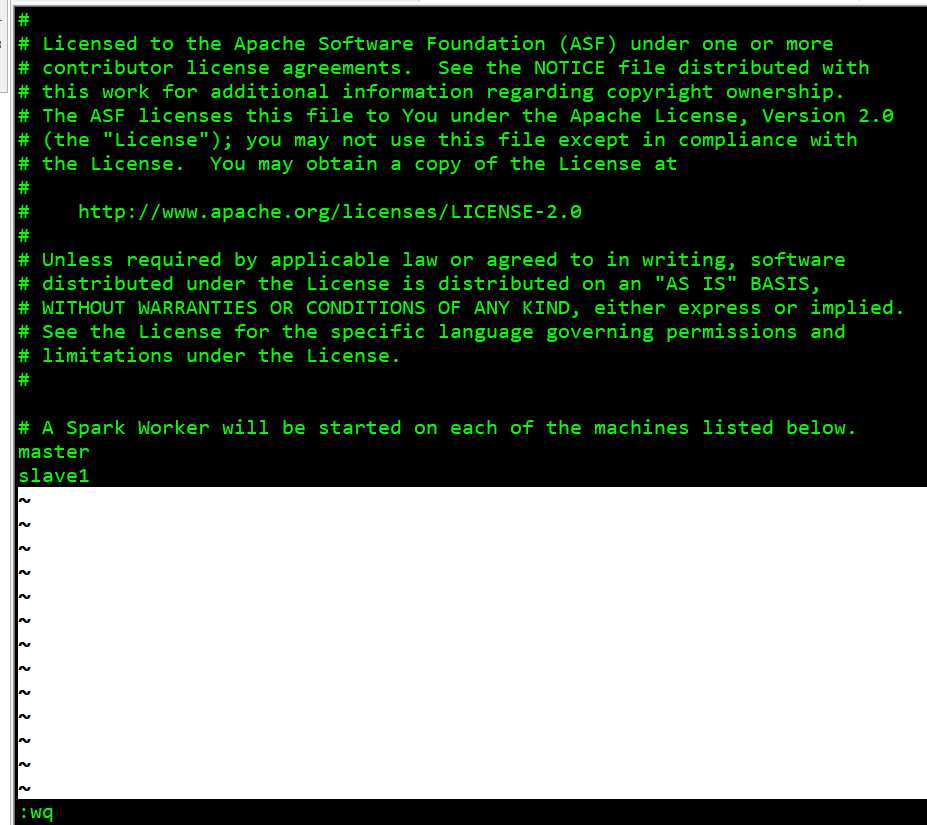
mv spark-env.sh.template spark-env.sh , spark-env.sh 配置一些环境变量, 由于我们用 Yarn 模式,
这里面不用配置


4、 运行测试
在 2.0 之前, Spark 在 YARN 中有 yarn-cluster 和 yarn-client 两种运行模式, 建议前者。
而在 2.0 里--master 的 yarn-cluster 和 yarn-client 都 deprecated 了, 统一用 yarn 。
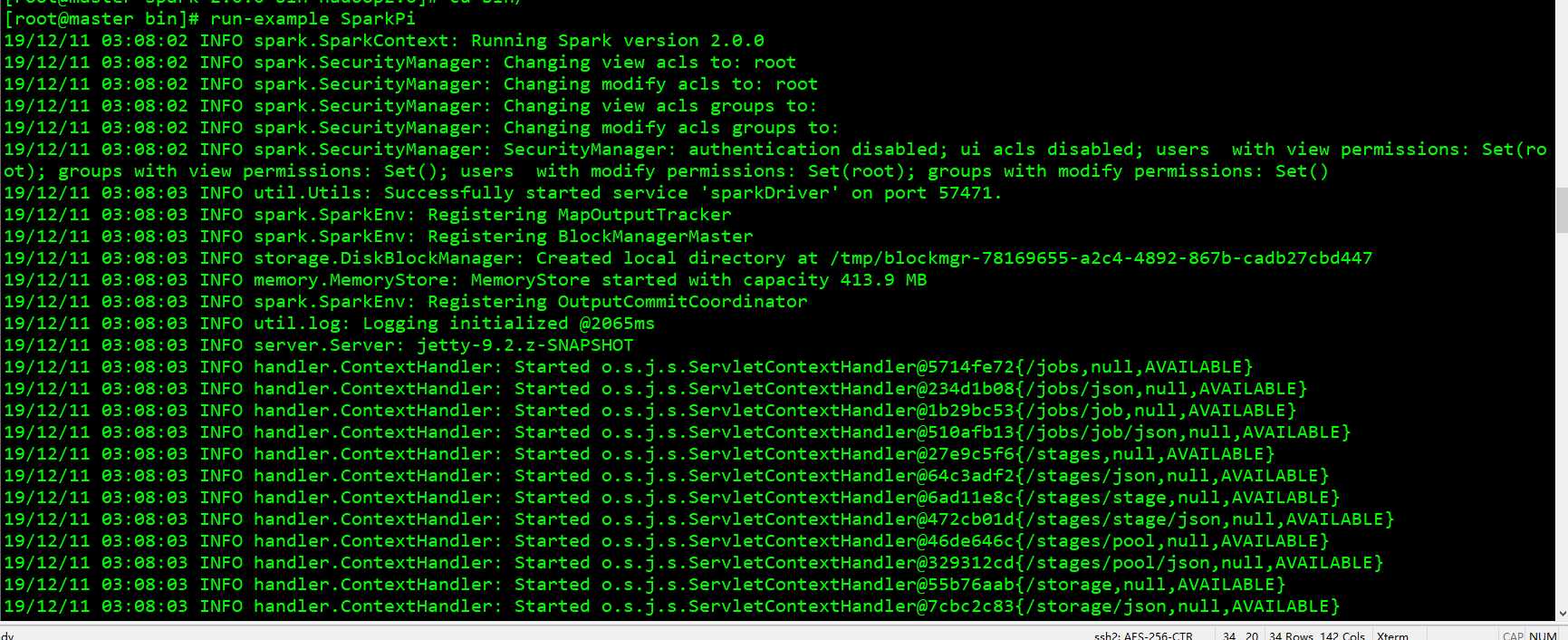
用 run-example 方便测试环境:
run-example SparkPi local 模式运行
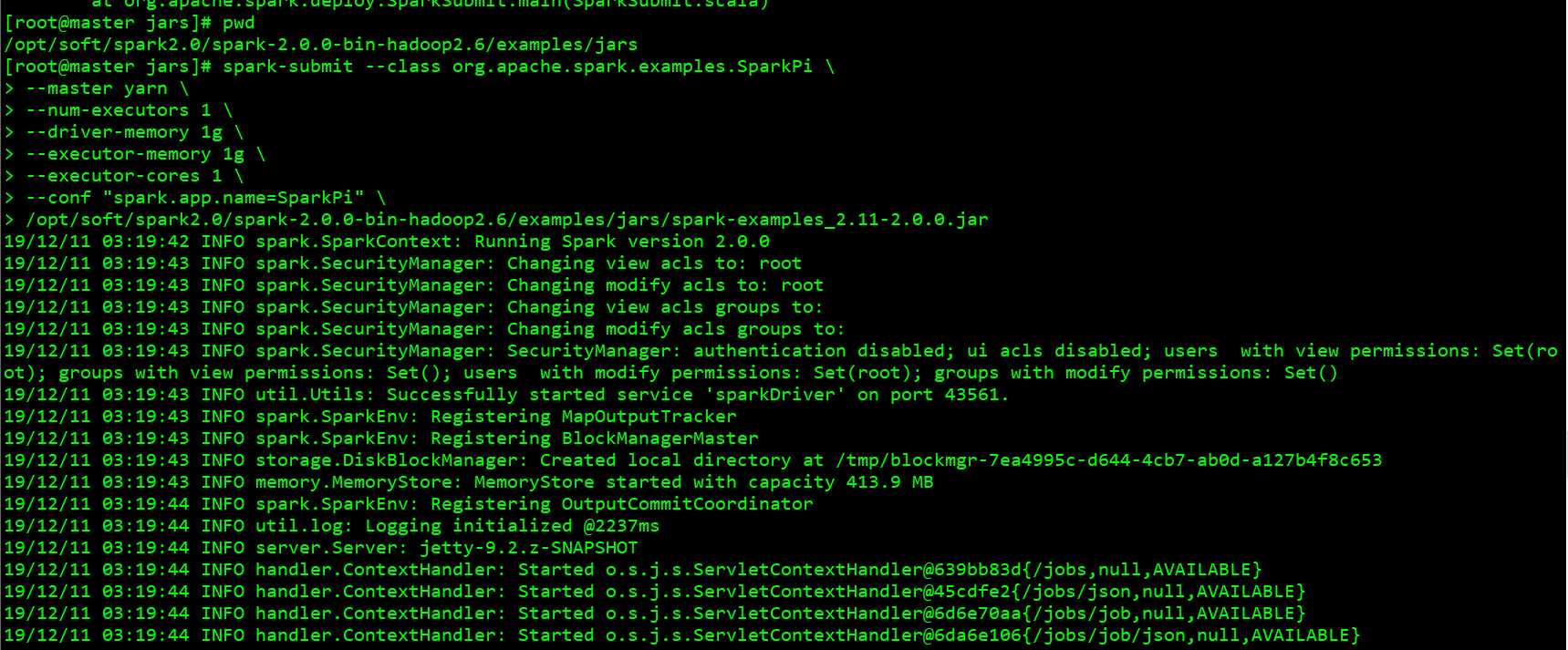
分布式模式运行:
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 1 --driver-memory 1g --executor-memory 1g --executor-cores 1 --conf "spark.app.name=SparkPi" /opt/soft/spark2.0/spark-2.0.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.0.0.jar
可以看到报错了
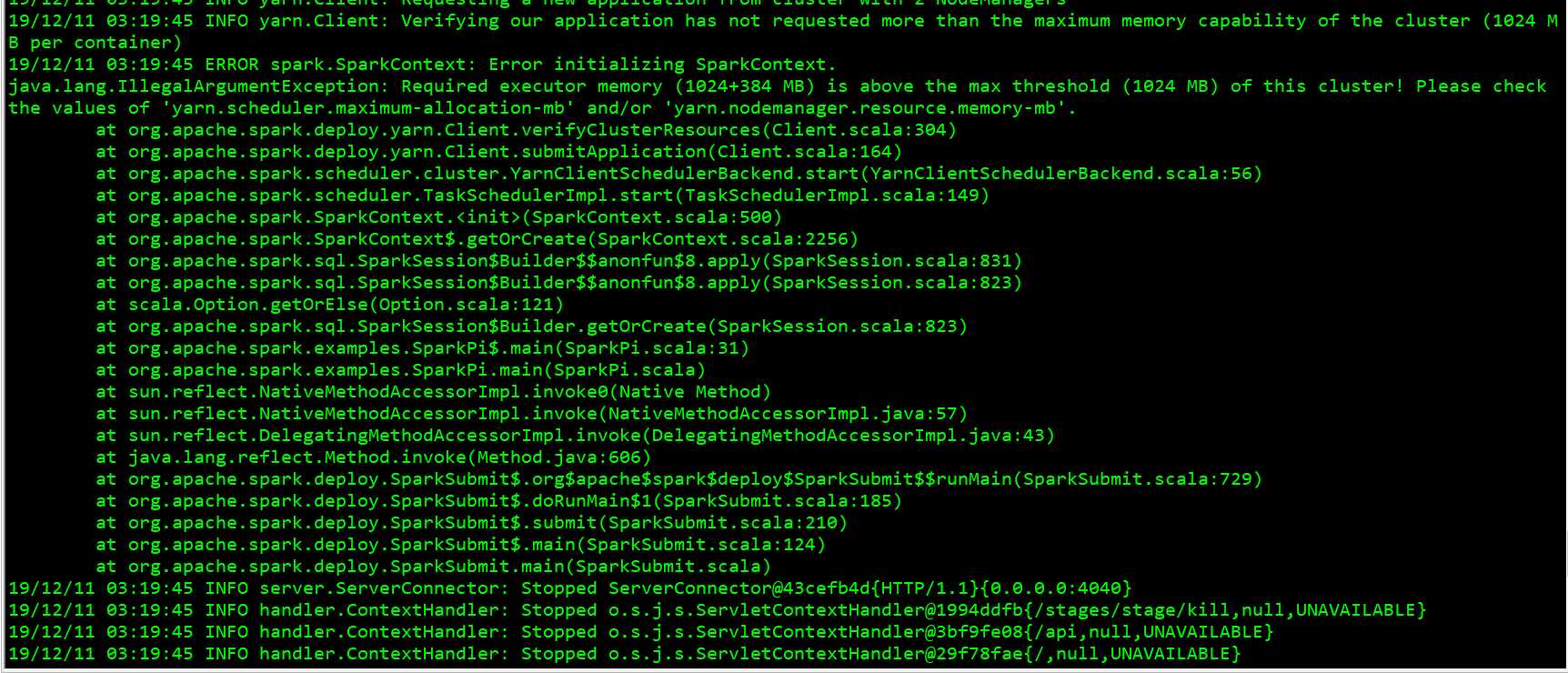
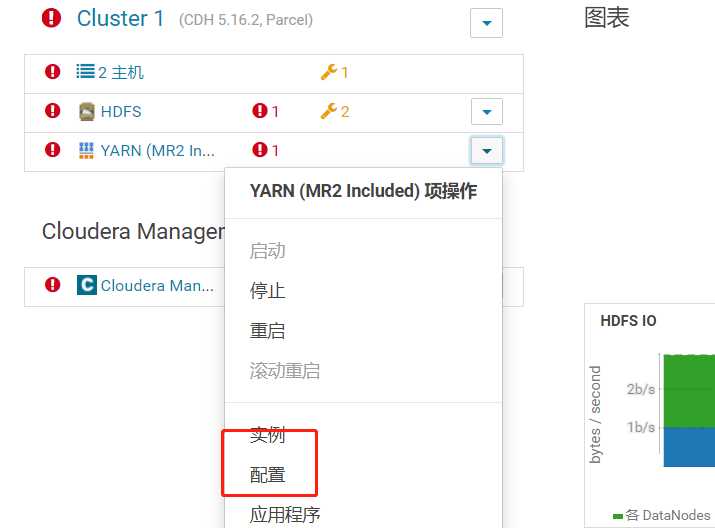
内存不足, 报错的话, 在 cm 里进行 yarn 的配置, 如下 2 个设置为 2g:
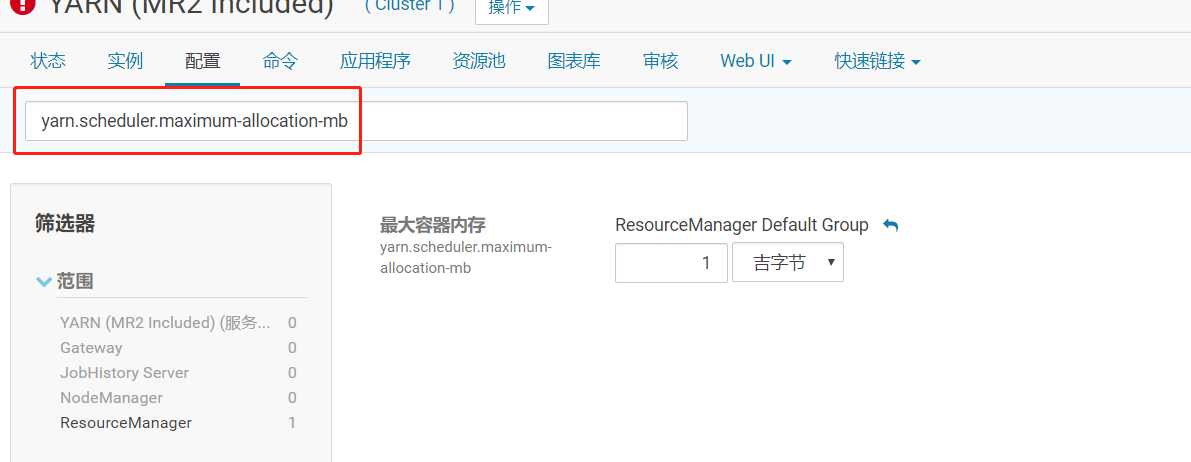
yarn.scheduler.maximum-allocation-mb
yarn.nodemanager.resource.memory-mb
搜索
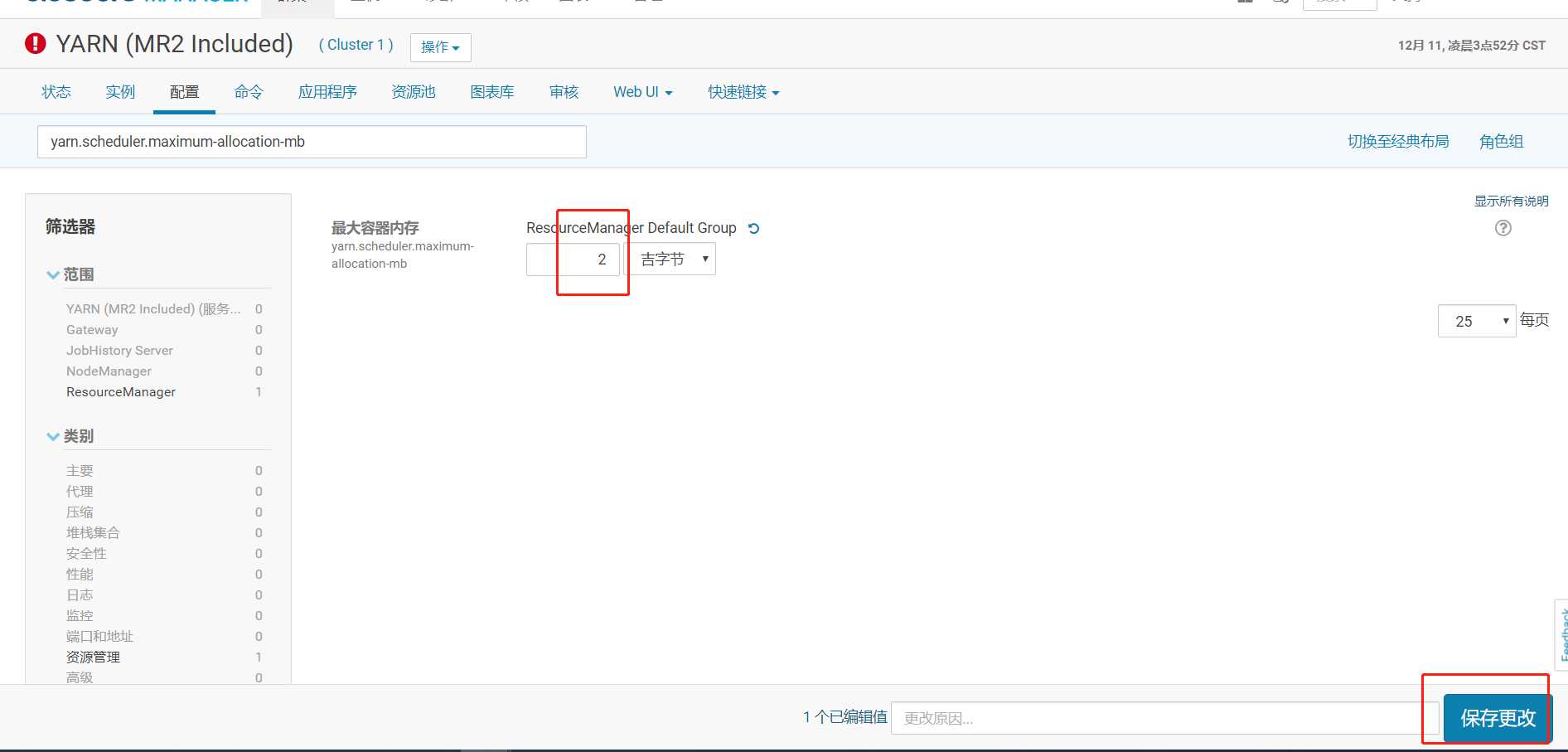
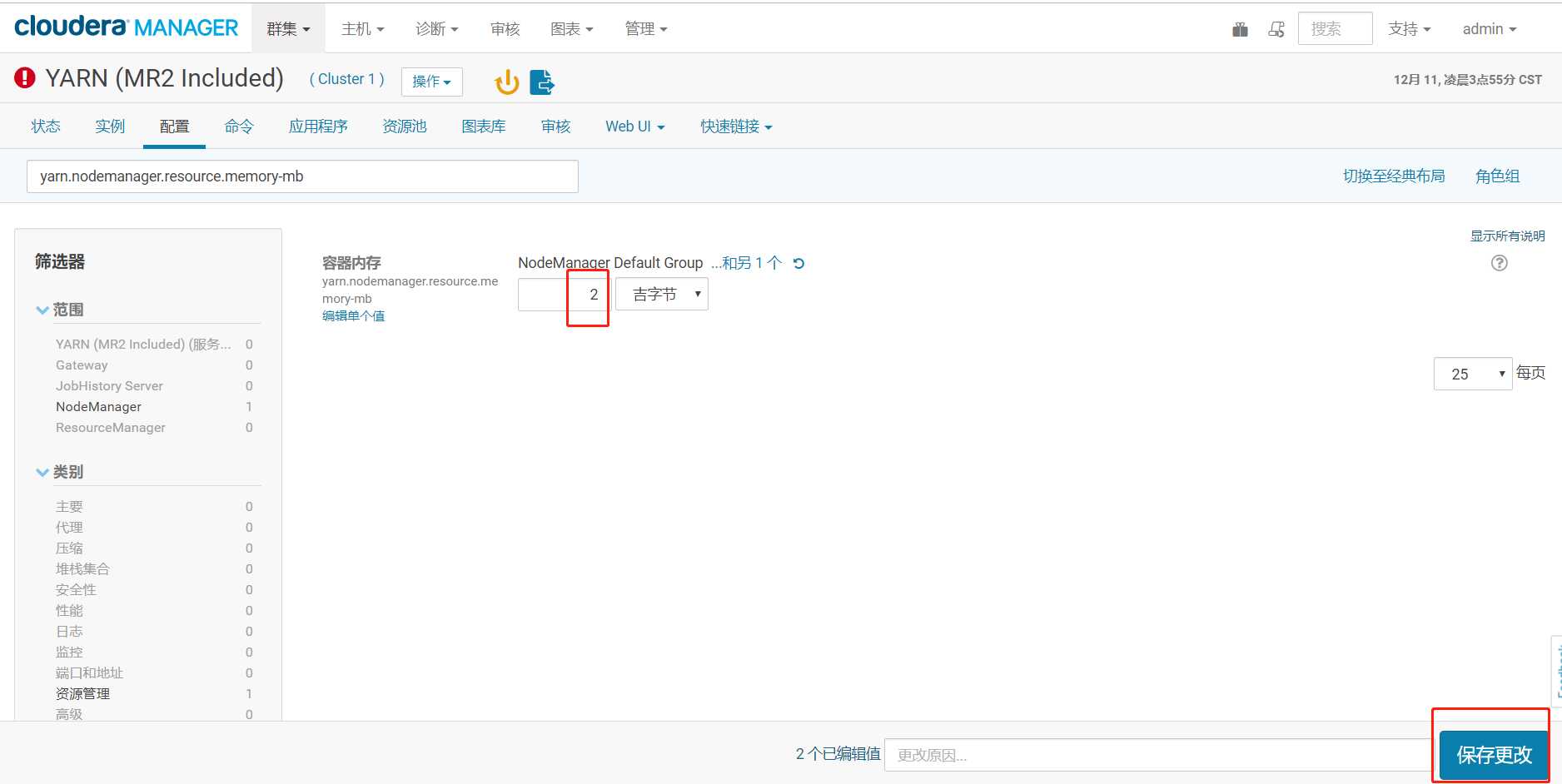
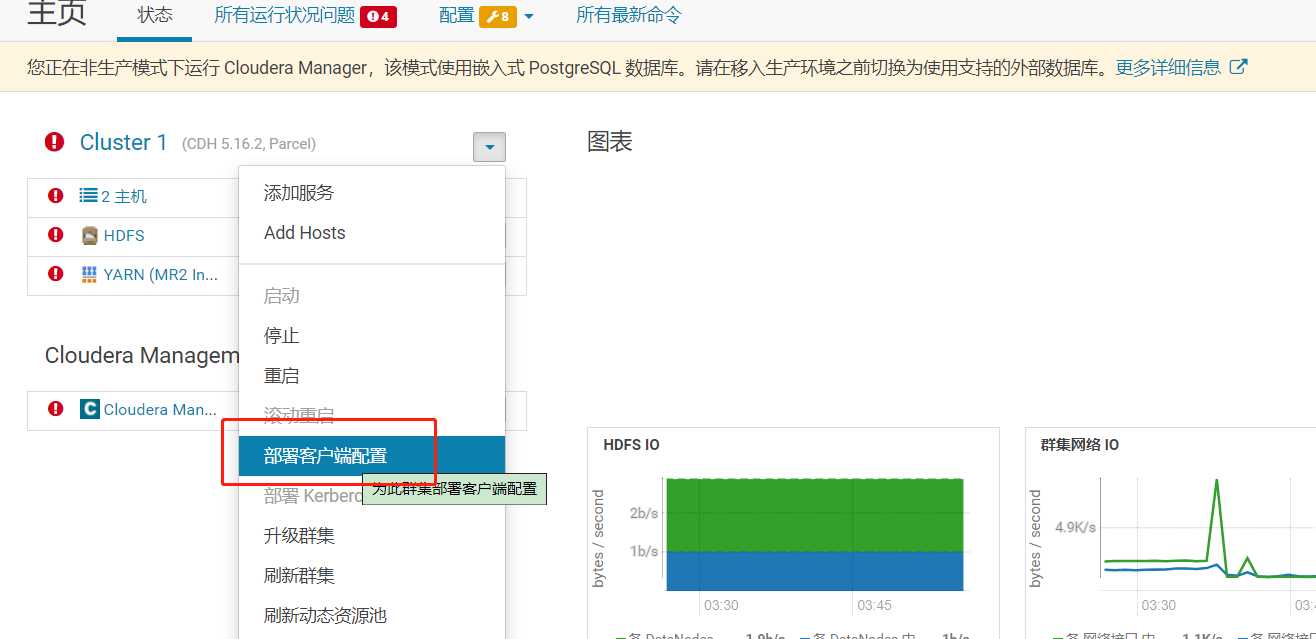
部署客户端配置的作用: 把 cm 界面里修改过的参数同步到每个节点的 xml 配置文件里。
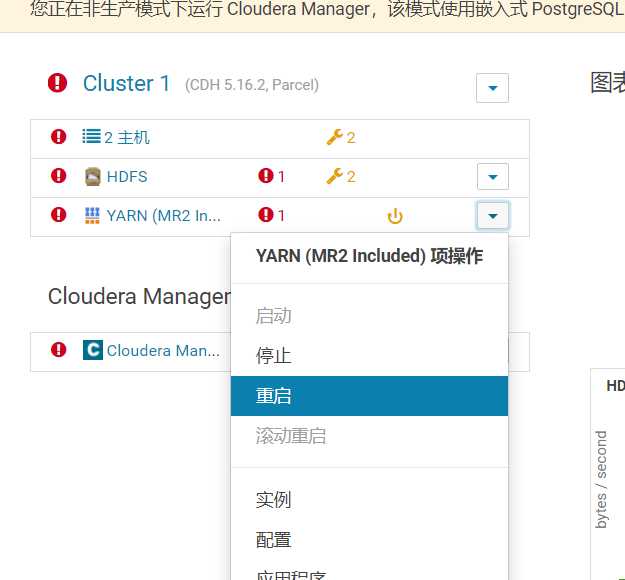
然后重启 Yarn 服务起效
标签:密码 template review 技术 而在 节点 实现 nbsp 上传
原文地址:https://www.cnblogs.com/braveym/p/12024024.html