标签:compute turn 参数 多个 final 最好 需要 reduce range
一个接受数字n作为参数,并返回从1到n的所有数字之和。
public static int intSum(int n) { return Stream.iterate(1, i -> i + 1) .limit(n) .reduce(0, Integer::sum); }
这是一个简单的顺序流,如果n极大,那么显然单线程是有问题的,所以引入了并行概念。
public static int parallelIntSum(int n) { return Stream.iterate(1, i -> i + 1) .limit(n) .parallel() .reduce(0, Integer::sum); }
图示
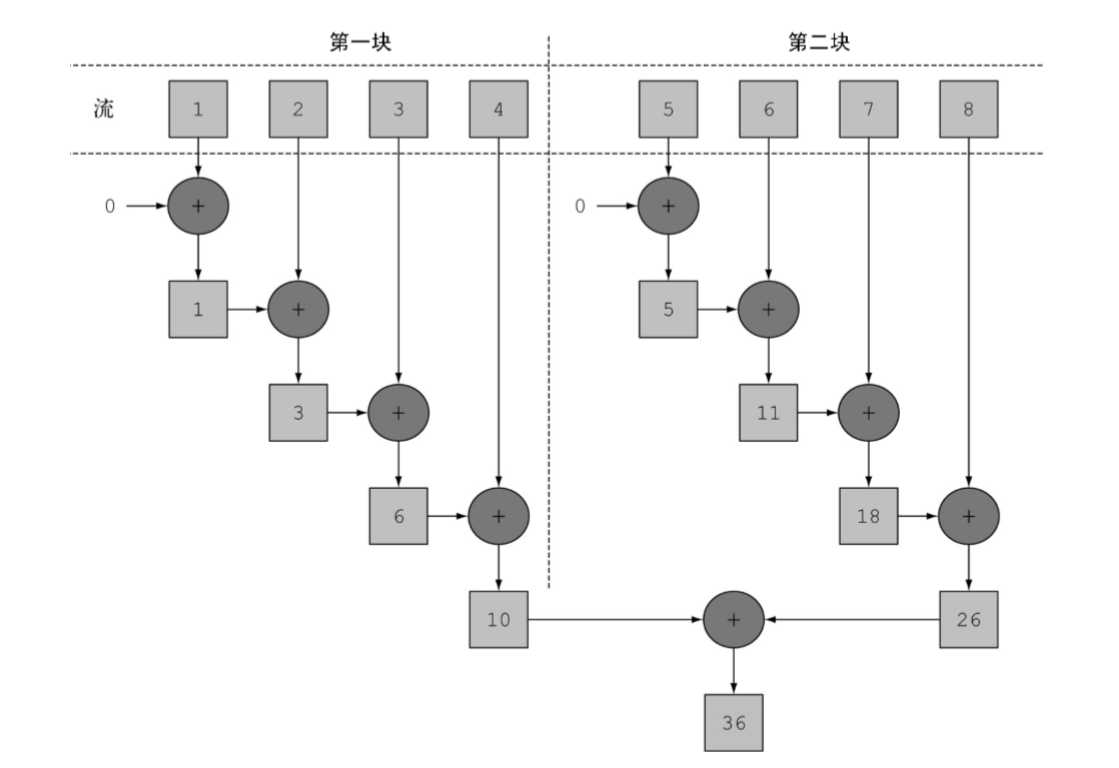
我们可以混合使用sequence和parallel吗?NO! 举一个错误的例子。
public static int complexSum(int n) { return IntStream.iterate(0, i -> i + 1) .parallel() .filter(i -> i % 2 == 0) .sequential() .map(x -> x * 2) .parallel() .reduce(0, Integer::sum); }
其实这个例子只会执行最后一个parallel。
这种并发的资源如何分配呢?
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由Runtime.getRuntime().available- Processors()得到的。
但是你可以通过java.util.concurrent.ForkJoinPool.common. parallelism来改变线程大小,如所:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
这是一个全局设置,因此它将代码中所有的并行流。让ForkJoinPool的大小等于处理器数量是个不错的默认值, 非你有很好的理由,则我们建你不要修改它。
实际上前面举得并行例子真的快吗?不,因为有两个问题导致它很慢:
iterate实际生成的是boxed对象,进行运算需要拆箱
我们很难把iterate分成多个块来并行
使用更加针对的方法
public static int parallelIntSum(int n) { return IntStream.rangeClosed(1, n) .parallel() .reduce(0, Integer::sum); }
其实这个不需要刻意记忆,就是我们日常的静态编程,我们对流也进行一次类型化就好了,实际上我觉得这个工作可以交给底层处理,但是可能是为了区分动态编程还是把控制交给使用者。
实际上,并行化是有开销的,首先是流的分割,再就是子流的线程分配,再就是数据的合并...最好是进行一定的测试确保性能,不建议直接使用。
对于并行流的使用要确保使用不能改变共享状态。
public static class Accumulator { private long total = 0; public void add(long value) { total += value; } }
public static long sideEffectParallelSum(long n) { Accumulator accumulator = new Accumulator(); LongStream.rangeClosed(1, n).parallel().forEach(accumulator::add); return accumulator.total; }
这是完全错误的,因为total是所有操作Accumulator线程的共享属性,不是原子操作。
虽然顺序流到并行流现在看起来很简单,但是要确保是否有必要。比如需要考虑的一个因素,背后的数据结构支持流拆分的性能如何

fork/join框架
import static lambdasinaction.chap7.ParallelStreamsHarness.FORK_JOIN_POOL;
public class ForkJoinSumCalculator extends RecursiveTask<Long> { public static final long THRESHOLD = 10_000; private final long[] numbers; private final int start; private final int end; public ForkJoinSumCalculator(long[] numbers) { this(numbers, 0, numbers.length); } private ForkJoinSumCalculator(long[] numbers, int start, int end) { this.numbers = numbers; this.start = start; this.end = end; } @Override protected Long compute() { int length = end - start; if (length <= THRESHOLD) { return computeSequentially(); } ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2); leftTask.fork(); ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end); Long rightResult = rightTask.compute(); Long leftResult = leftTask.join(); return leftResult + rightResult; } private long computeSequentially() { long sum = 0; for (int i = start; i < end; i++) { sum += numbers[i]; } return sum; } public static long forkJoinSum(long n) { long[] numbers = LongStream.rangeClosed(1, n).toArray(); ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers); return FORK_JOIN_POOL.invoke(task); } }
这是自行实现的一个框架,实际上来讲这个Pool我们是单例的,因为不适合使用者随意更改。这其实就是一个分治的线程级别的实现。
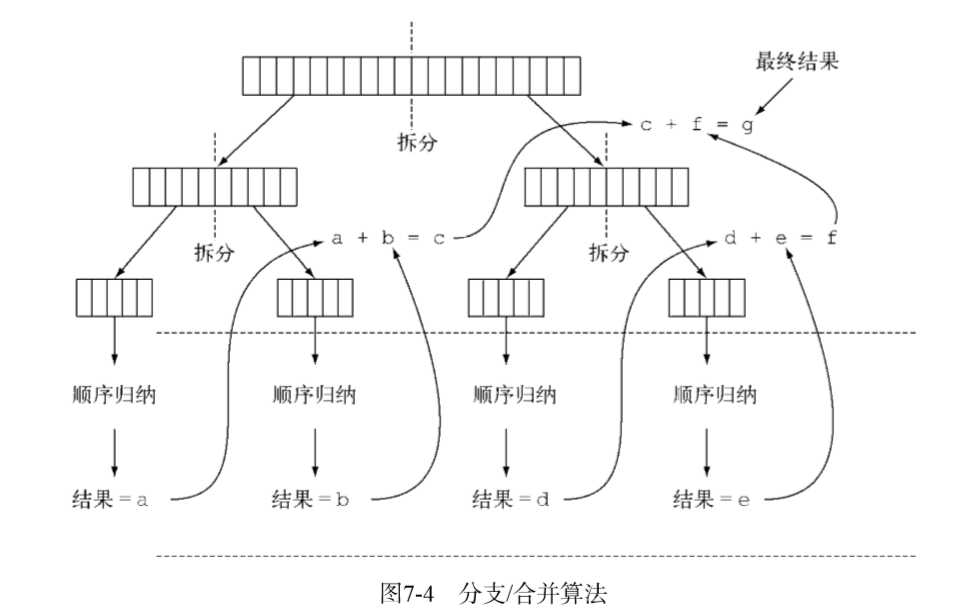
使用的注意地方,最关键的就是join会阻塞,所以你要保证所有的子任务都ok后再调用join,否则阻塞会导致性能问题。
实际上的线程是多个的,但是从算法图解上看,并不是一个理想的并行方案,因此有了工行窃取。
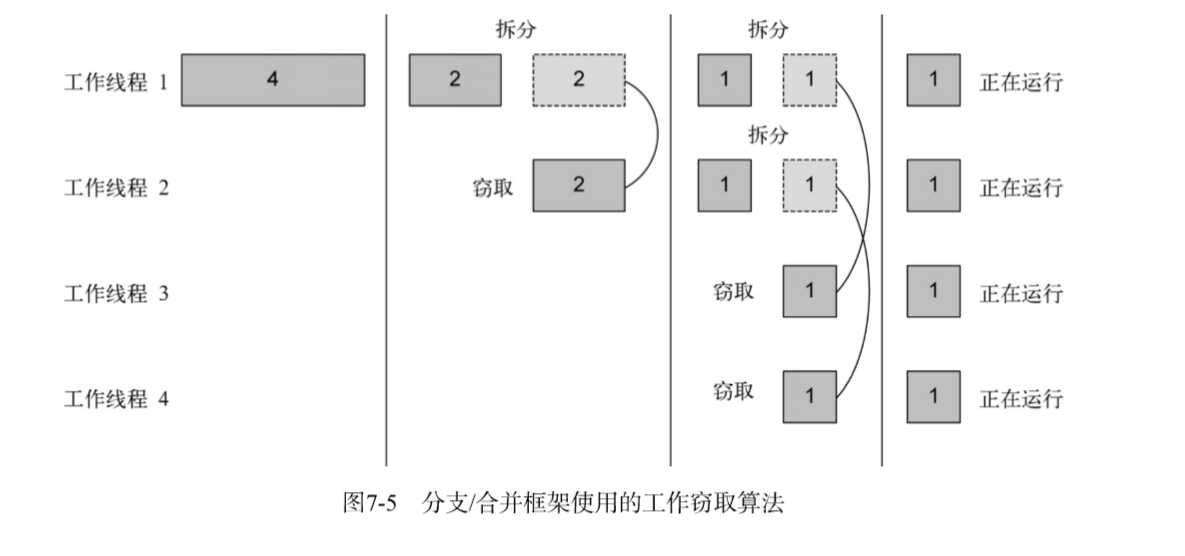
end
标签:compute turn 参数 多个 final 最好 需要 reduce range
原文地址:https://www.cnblogs.com/CherryTab/p/12129378.html