标签:就会 reg 权重 tin color 哪些 回归 模型 nim
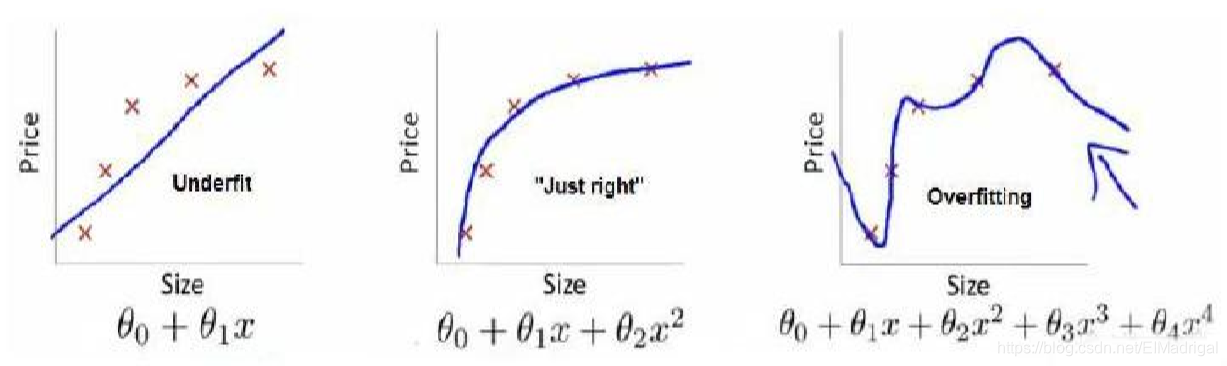
欠拟合(high bias):模型不能很好地适应训练集;
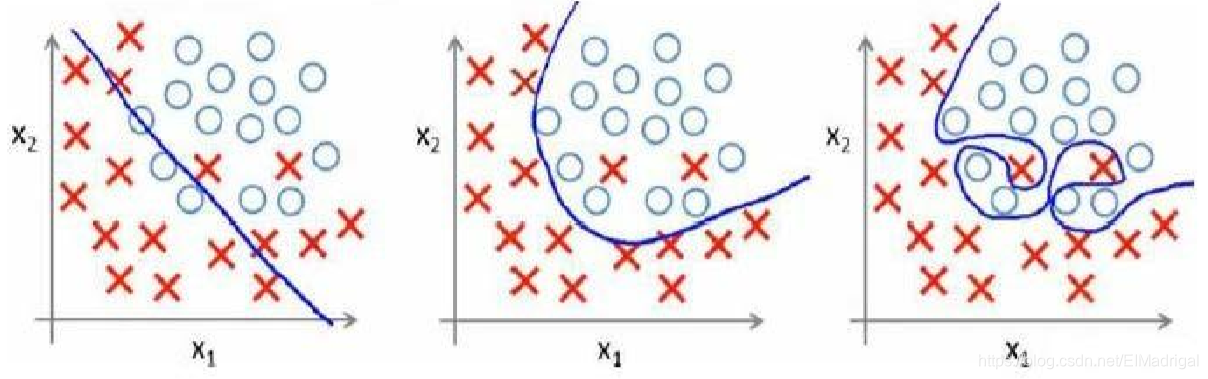
过拟合(high variance):模型过于强调拟合原始数据,测试时效果会比较差。
处理过拟合:
1、丢弃一些特征,包括人工丢弃和算法选择;
2、正则化:保留所有特征,但减小参数的值。
过拟合一般是由高次项引起,那么我们可以通过增加某些项的cost,来降低它们的权重。
在梯度下降过程中,要使损失函数变小,那么\(\theta\)就会变得很小,所以假设函数中的\(\theta\)就会变小,该项的权重就会降低。
如果不知道要惩罚哪些特征,可以一起惩罚(除了\(\theta_0\))。
将代价函数改为:
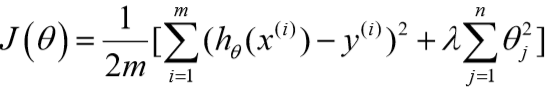
\(\lambda\)是正则化参数。
如果\(\lambda\)过大,那么所有的参数都会最小化,那么假设就会变为\(h_\theta(x)=\theta_0\),造成欠拟合。
\(\theta_0\)没有正则化处理,所以梯度下降要分情况:
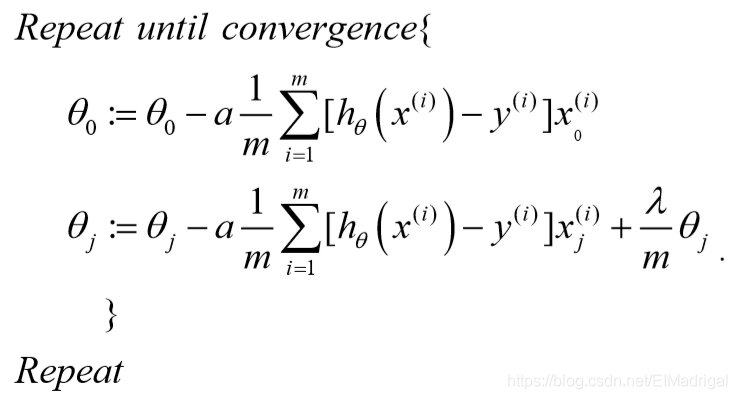
化简下:
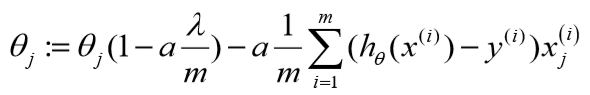
可以看到:
正则化后的参数更新比原来多减小了一个值。
再看线性回归的另外一个工具:常规方程。
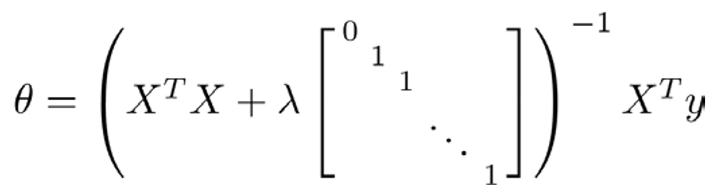
推导过程省略......
对于逻辑回归的代价函数,同样增加一个正则化表达式:
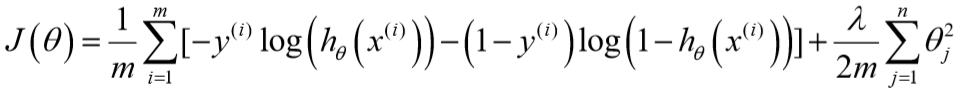
梯度下降算法与线性回归相同,不过\(h_\theta(x)\)不同。
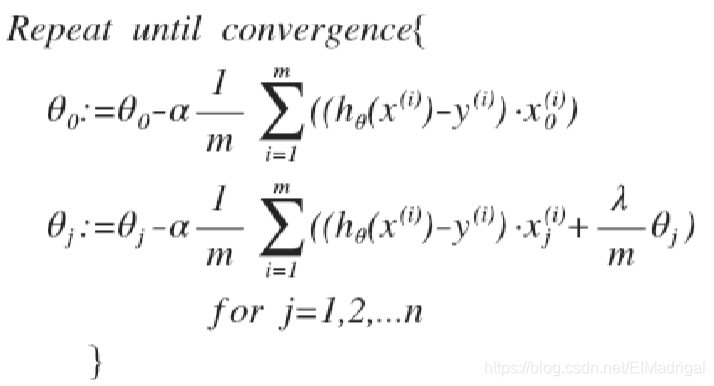
标签:就会 reg 权重 tin color 哪些 回归 模型 nim
原文地址:https://www.cnblogs.com/EIMadrigal/p/12130865.html